[NLP]文本分类-textCNN
Posted mj-selina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[NLP]文本分类-textCNN相关的知识,希望对你有一定的参考价值。
一、简要
卷积神经网络的核心思想是捕捉局部特征,对于文本来说,局部特征就是由若干单词组成的滑动窗口,类似于N-gram.
卷积神经网络的优势在于能够自动地对N-gram特征进行组合和筛选,获得不同抽象层次的语义信息。
二、textCNN
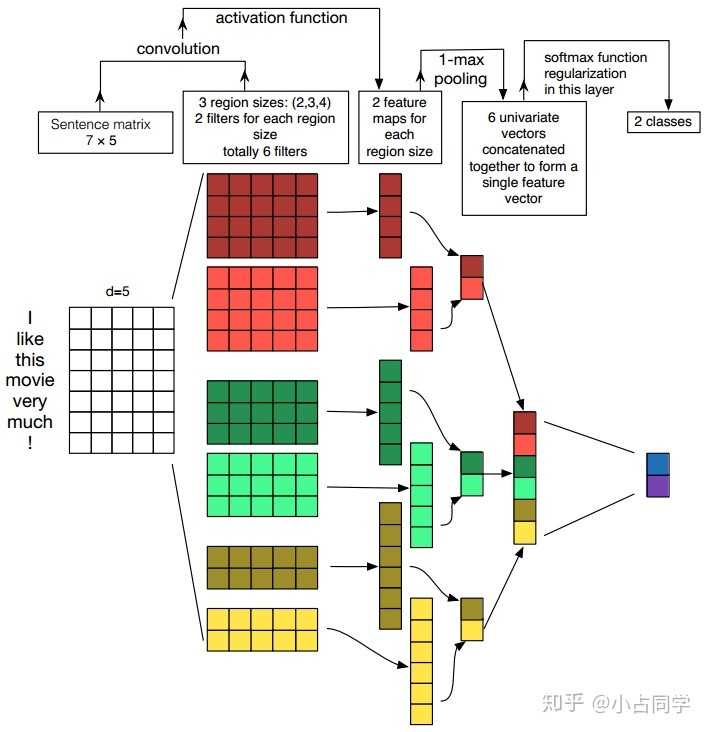
具体描述:
1、 第一层是输入层,输入层是一个n*d矩阵,其中n表示输入文本的长度,d表示每个词/字向量的维度。
注:每个词向量既可以是预先在其他语料库中训练好的,也可以作为未知的参数由网络训练而得到。二者各有优势,前者可以利用其他语料库得到的先验知识,后者可以更好的抓取与当前任务相关联的特征。因此,图中的输入层实际采用了双通道的形式,即有两个n*d矩阵,其中一个用预训练好的词向量特征,并且在训练过程中不再发生变化;另一个是用预训练好的词向量做初始化,但是会作为参数,随着网络的训练过程发生改变。
2、 第二层是卷积层,第三层是池化层。
卷积层:我们用大小分别为2,3,4的filter来对输入层进行卷积,每个大小的filter各有2个(对应产生2个feature map),分别于输入的词向量做卷积后会得到6个feature map。
池化层:使用1-max pooling分别对6个feature map做池化操作,最终会生成6个scalar,将其拼接后生成的向量经过softmax完成分类。
注1:卷积核的大小与词向量的维度相同,且卷积核只会在高度方向上行动,说明卷子操作会在完整的单词上进行,而不会对几个单词的一部分vector进行卷积,这保证了word作为语言中最小粒度的合理性。
注2:使用多个相同size的filter是为了从同一个窗口学习相互之间互补的特征。比如可以设置size为3的filter有64个卷积核。
三、textCNN的缺点:它的全局max pooling丢失了结构信息,因此很难去发现文本中的转折关系等复杂模式。(改进方法:使用k-max pooling做优化,k-max pooling会针对每个卷积核保留前k个最大值,并且保留这些值出现的顺序,即按照文本中的位置顺序来排列这k个最大值,在某些比较复杂的文本上相对于1-max pooling会有提升)
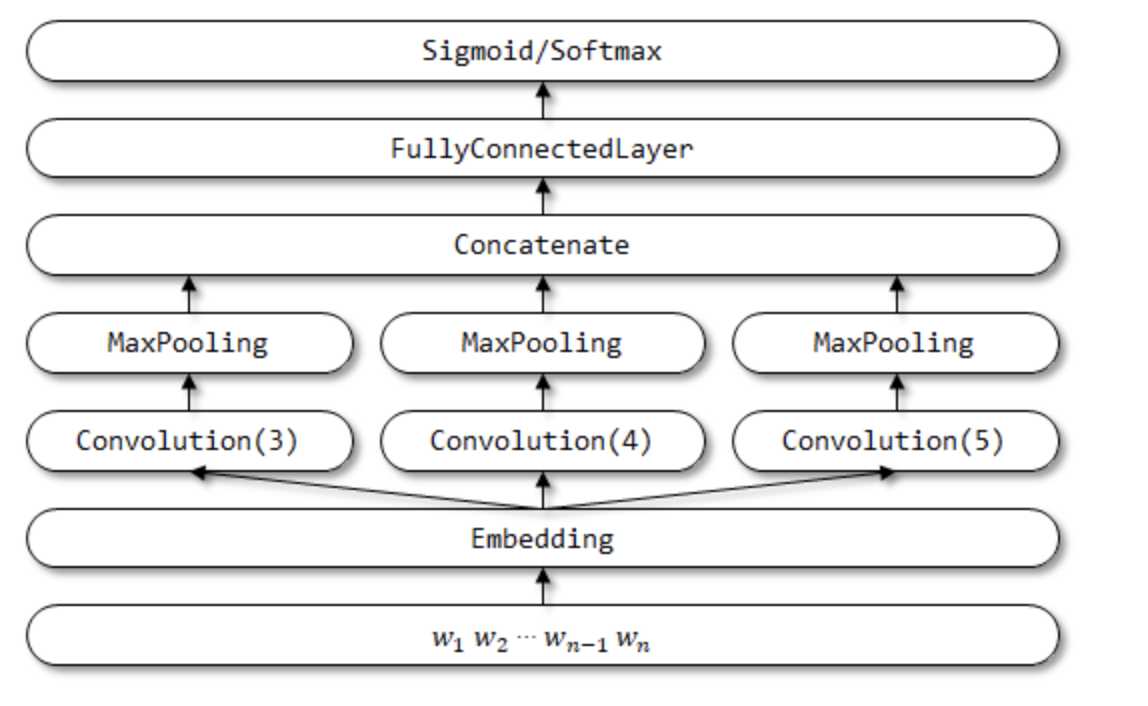
代码流程:
四、textCNN的超参数调参
输入词向量表征:词向量表征的选取(如选word2vec还是GloVe)
卷积核大小:一个合理的值范围在1~10。若语料中的句子较长,可以考虑使用更大的卷积核。另外,可以在寻找到了最佳的单个filter的大小后,尝试在该filter的尺寸值附近寻找其他合适值来进行组合。实践证明这样的组合效果往往比单个最佳filter表现更出色
feature map特征图个数:主要考虑的是当增加特征图个数时,训练时间也会加长,因此需要权衡好。当特征图数量增加到将性能降低时,可以加强正则化效果,如将dropout率提高过0.5
激活函数:ReLU和tanh是最佳候选者
池化策略:1-max pooling表现最佳
正则化项(dropout/L2):相对于其他超参数来说,影响较小点
参考文献:
[1] https://zhuanlan.zhihu.com/p/77634533
[2]https://github.com/jeffery0628/text_classification
以上是关于[NLP]文本分类-textCNN的主要内容,如果未能解决你的问题,请参考以下文章