HDFS主要解决什么问题,与IPFS有什么不同?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS主要解决什么问题,与IPFS有什么不同?相关的知识,希望对你有一定的参考价值。
HDFS主要解决什么问题,与IPFS有什么不同?
近年,随着区块链、大数据等技术的推动,全球数据量正在无限制地扩展和增加。分布式存储的兴起与互联网的发展密不可分,互联网公司由于其大数据、轻资产的特点,通常使用大规模分布式存储系统。
与传统的高端服务器、高端存储器和高端处理器不同的是,互联网公司的分布式存储系统由数量众多的、低成本和高性价比的普通 PC 服务器通过网络连接而成。由于互联网的业务发展迅猛,使得存储系统架构不能依靠传统的纵向扩展的方式,即先买小型机,不够时再买中型机,甚至大型机。互联网后端的分布式系统要求支持横向扩展,即通过增加普通 PC 服务器来提高存储系统的整体处理能力。
另外,随着服务器的不断加入,需要能够在软件层面实现自动负载均衡,使得系统的处理能力得到线性扩展。在这种情况下,分布式存储的成为大多数企业的必然选择。
那么分布式存储的种类有哪些呢?
分布式存储包含的种类繁多,除了传统意义上的分布式文件系统、分布式块存储和分布式对象存储外,还包括分布式数据库和分布式缓存等,但其中架构无外乎于三种:
A、中间控制节点架构 - 以 HDFS 为代表的架构是典型的代表
B、完全无中心架构 – 计算模式,以 Ceph 为代表的架构是其典型的代表
C、完全无中心架构 – 一致性哈希,以 swift 为代表的架构是其典型的代表
这里我们主要对比下HDFS与IPFS
HDFS的简介
HDFS(Hadoop Distributed File System)是hadoop项目的核心子项目,是分布式计算中数据存储管理的基础。是基于流数据模式访问和处理超大文件的需求而开发的, 可以运行于廉价的商用服务器上。
它所具有的高容错、 高可靠性、 高可扩展性、 高获得性、 高吞吐率等特征为海量数据提供了不怕故障的存储, 为超大数据集(Large Data Set) 的应用处理带来了很多便利。
HDFS是开源的,存储着Hadoop应用将要处理的数据,类似于普通的Unix和linux文件系统,不同的是它是实现了google的GFS文件系统的思想,是适用于大规模分布式数据处理相关应用的、可扩展的分布式文件系统。
为什么需要HDFS?
小量的数据,单机的磁盘是能够很好地处理面对的数据,但当数据量巨大(PB)时,磁盘开始纠结处理我们需要的海量信息。我们无法提升单个磁盘的传输速度, 因为这个技术已经没有空间了 只能将大任务分解成小任务 , 一块磁盘分解成多个磁盘。 对多个磁盘上的文件进行管理, 就是分布式文件管理系统—HDFS
HDFS的功能
1)数据的分布式存储和处理。
2)Hadoop 提供了一个命令接口来与 HDFS 进行交互。
3)namenode 和 datanode 的内置服务器可帮助用户轻松检查群集的状态。
4)对文件系统数据的流式处理访问。
5)HDFS 提供文件权限和身份验证。
HDFS系统架构 及主要组件
在之前分步启动Hadoop集群时大家应该注意到了,集群中与HDFS相关的进程有两类,分别是namenode与datanode。HDFS是一个主从架构的系统,其中namenode作为主节点管理着多个从工点datanode。其架构图如下所示:
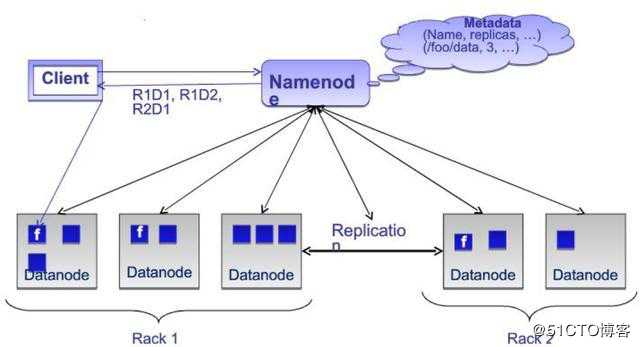
Namenode:
管理维护着文件系统树以及整个文件树内所有的文件和目录即文件系统的元数据; 控制客户端对文件的访问; 它还执行文件系统操作, 如重命名,关闭和打开文件/目录。DateNode:
管理所存储的数据;按照客户端的请求, 执行在文件系统上的读写操作;还根据NameNode的指令执行操作如block的创建、 删除和备份。
Block
通常用户的数据存储在HDFS上的文件中;该文件将被拆分为一个或多个片段, 并存储在单个的数据节点;这些文件片段称为blocks。 换句话说, HDFS可读写的最小数据量叫做Block。 默认的block大小是64MB/128M(可根据配置增加)。
Rack
安装集群计算机的机架,一个机架可以安装几台计算机,在整个Hadoop集群中又会有几个这样的机架组成。
如果客户端需要从某个文件读取数据,首先从 NameNode 获取该文件的位置,然后从该 NameNode 获取具体的数据。在该架构中 NameNode 通常是主备部署( Secondary NameNode ),而 DataNode 则是由大量节点构成一个集群。由于元数据的访问频度和访问量相对数据都要小很多,因此 NameNode 通常不会成为性能瓶颈,而 DataNode 集群中的数据可以有副本,既可以保证高可用性,可以分散客户端的请求。因此,通过这种分布式存储架构可以通过这种分布式存储架构可以通过横向扩展 datanode 的数量来增加承载能力,也即实现了动态横向扩展的能力。
通常,用户数据存储在 HDFS 的文件中。文件系统中的文件将分为一个或多个片段存储在单个数据节点中。这些文件段称为block。换句话说,HDFS 可以读取或写入的最小数据量称为block。默认块大小为 64MB,可以根据 HDFS 配置进行更改。
HDFS的特点
1、故障检测和恢复 – 由于 HDFS 包含大量产品硬件,组件故障频繁。因此,HDFS 应具有快速自动故障检测和恢复的机制。
2、数据集的管理 – HDFS 每个群集都有数百个节点来管理具有大型数据集的应用程序。
3、数据硬件处理 – 当计算在数据物理附近时,可以高效地完成请求的任务。特别是在涉及大量数据集时,它减少了网络流量并提高了吞吐量。
IPFS的简介
IPFS(Inter Planetary File System),又叫星际文件系统。IPFS在2015年开启,目前已经有5年时间了。IPFS和Filecoin一直热度不断,影响力也是越来越大。在这里我们先撇开区块链部分的Filecoin不谈,重点分析下IPFS在分布式存储方面的应用。
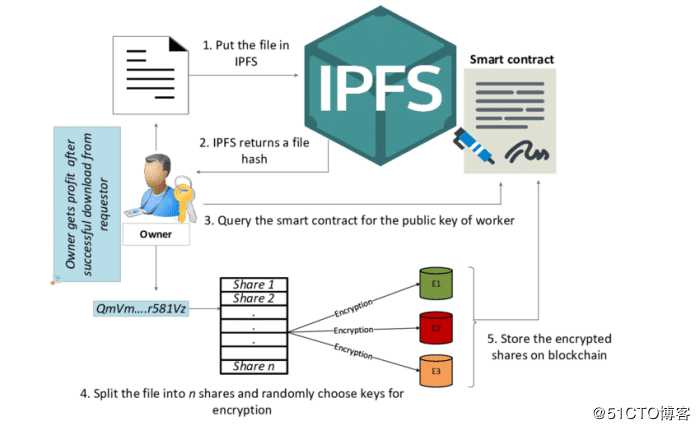
IPFS的工作原理
第一个原理,就是在IPFS系统中,每个文件都会被进行 Hash 处理,并生成数字指纹。
第二,就是我们要查找文件时,IPFS 通过使用一个分布式哈希表,可以快速找到拥有数据的节点进行检索,并使用哈希验证其是否为正确的数据,从而找到我们想要的文件。
第三, IPFS会通过网络删除重复的、具有相同哈希值的文件,也就是说,它通过计算是可以判断哪些文件是冗余重复的,并跟踪每个文件的版本历史记录。
第四,每个网络节点只存储它感兴趣的内容,以及一些索引信息,有助于我们弄清楚谁在存储什么。
第五,使用称为 IPNS(去中心化命名系统),每个文件都可以被协作命名为易读的名字,通过搜索,我们就能很容易地找到想要查看的文件。
由于,IPFS跟HTTP协议,都被称为互联网底层协议。那么上网的时候,我们经常能看到这样一串字符,http:// ?www.baidu.com,或者是http:// www.taobao.com、或是http:// ?www.aiqiyi.com等……,这就是我们俗称所谓的域名。但IPFS有非常优于HTTP的地方,主要体现在以下几个方面:
IPFS它的安全性更高。一方面,IPFS中的每个文件及其中的所有块,都被赋予了一个称为加密散列的唯一指纹;另一方面,IPFS是一个点对点的分布式文件系统,是可以用来存储文件的,这个文件我们可以理解为:包括文本、图片、音频、视频等等;再者,由于IPFS的工作机制是将整个文件进行拆散, 然后储存在全球的不同节点。需要数据的时候,通过文件的索引从原来存储的位置找回来,能够保护数据的隐私与安全性。
举例BAT,我们现在使用的云储存方式是:我们把数据交给BAT(百度云、阿里云、腾讯云),需要数据的时候找BAT拿回来。这个过程看上去没什么毛病,可一旦BAT的服务器停机,或者是你的隐私被偷窥了呢?
IPFS它的去中心化使得数据上传、下载速度可以更快,还能够让数据永久化的存储。因为IPFS是由全球的存储节点构成的,也就是说未来我们可以在世界的每个角落,都可以快速的访问存储在ipfs网络上的文件。简单地说就是把这些文件进行加密,然后存储到电脑、手机等等这些使用硬盘的仪器当中。
从上述的原理中我们可以清晰地看出,在存储方面IPFS与传统的分布式存储是完全不同的,是完全去中心化的。
HDFS与IPFS对比
a 、应用对象
HDFS主要是企业级的应用,针对企业的大文件存储,因为 HDFS 采用的是以元数据的方式进行文件管理,而元数据的相关目录和块等信息保存在 NameNode 的内存中, 文件数量的增加会占用大量的 NameNode 内存。如果存在大量的小文件,会占用大量内存空间,引起整个分布式存储性能下降,所以尽量使用 HDFS 存储大文件比较合适。而IPFS主要是针对个人用户市场,根据个人的文件进行存储,存储的节点越多,存储的文件越多,整个文件系统的稳定性也就越高。
b 、读写频次
HDFS适合低写入,多次读取的业务。HDFS 的数据传输吞吐量比较高,但是数据读取延时比较差,不适合频繁的数据写入。IPFS对于文件的读取和写入具有很强的包容性和扩展性,文件的读取和写入越多,整个基于IPFS的经济生态系统也就越繁荣,在系统中的用户也就越受益。
c 、存储环境
HDFS 采用多副本数据保护机制,使用普通的 X86 服务器就可以保障数据的可靠性,不推荐在虚拟化环境中使用。IPFS使用个人的普通服务器即可作为节点,运行IPFS系统,提供去中心化的存储服务
d、存储系统
HDFS 主要针对大企业,虽是分布式存储,其主要的控制着仍是企业主体,属于一个封闭的存储系统。IPFS完全去中心化的操作,任何企业和个人都可以接入存储网络。
e、寻址方式
HDFS如果客户端需要从某个文件读取数据,首先从 NameNode 获取该文件的位置,然后从该 NameNode 获取具体的数据,IPFS则是直接从内容所在的节点获取文件,是基于内容获取的方式。
基于IPFS技术开发的应用也不断出现,IPFS直接整合至Brave浏览器中,将 Hadoop 置于IPFS之上进行p2p数据分析,PeerPad利用IPFS构建无服务器、实时的、离线协作式应用等。在陆续与微软、美国宇航局(NASA)等知名机构、企业建立合作关系后,IPFS的实际应用价值得到了进一步深化。
总结IPFS/IPSE分布式架构的优点:
去中心化
分布式节点网络,无单点问题
加密技术保护数据完整性和安全性
存储成本和传输成本远低于中心化系统
通证激励
以上就是本篇文章的全部内容,更多详细信息敬请关注。
以上是关于HDFS主要解决什么问题,与IPFS有什么不同?的主要内容,如果未能解决你的问题,请参考以下文章