IDA使用技巧及大杂烩
Posted sandymandy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IDA使用技巧及大杂烩相关的知识,希望对你有一定的参考价值。
IDA Pro基本简介
IDA加载完程序后,3个立即可见的窗口分别为IDA-View,Named,和消息输出窗口(output Window)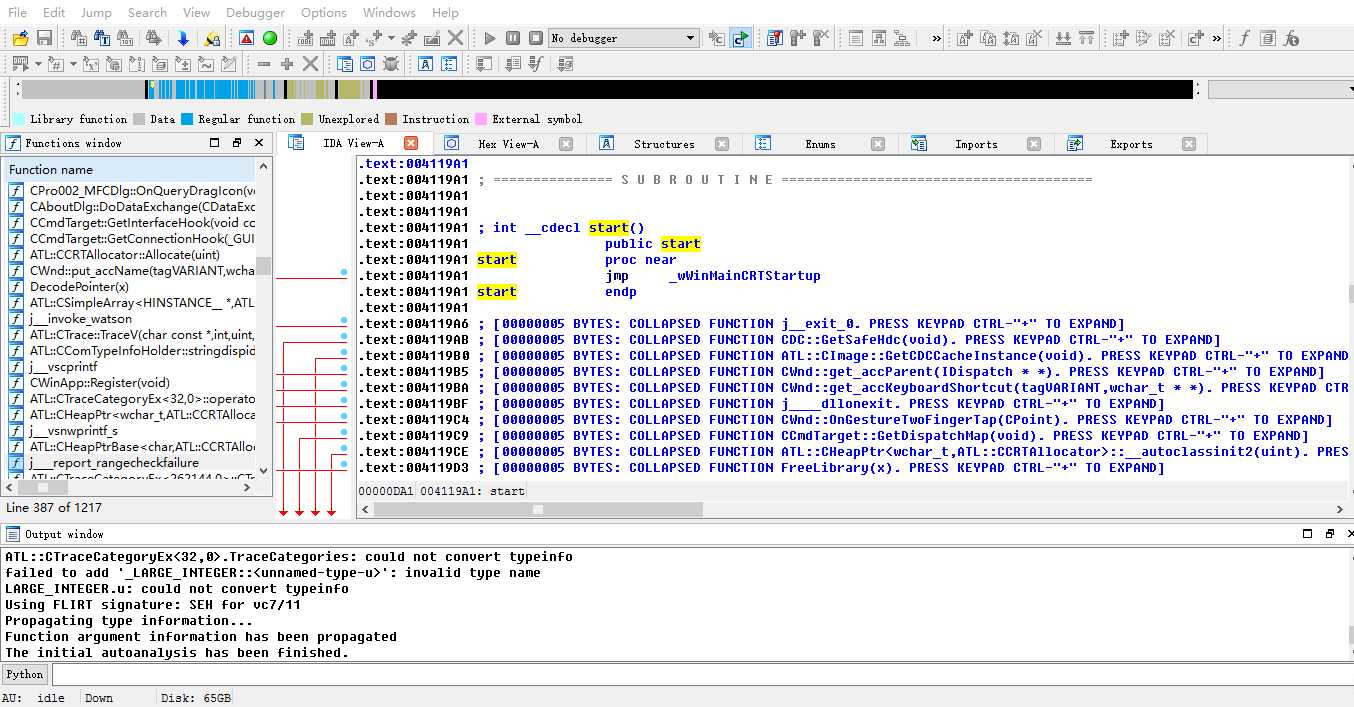
IDA图形视图会有执行流,Yes箭头默认为绿色,No箭头默认为红色,蓝色表示默认下一个执行块。
在寄存器窗口中显示着每个寄存器当前的值和对应在反汇编窗口中的内存地址。函数在进入时都会保存堆栈地址EBP和ESP,退出函数时恢复。
选择菜单Debugger下的Start process(也可以按F9键)来开始调试。调试会让程序在电脑中执行,所以IDA会提示注意提防恶意程序、病毒和木马。
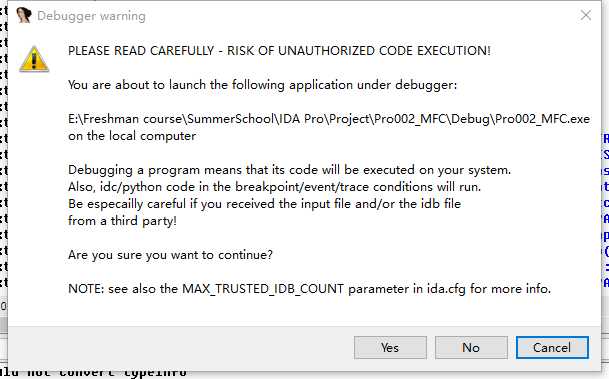
打开IDA Pro 6.5,为进入IDA界面提供三种选项,分别是New(新建),Go(运行),Previous(上一个)。
选择File菜单下的Open,打开想要逆向的可执行文件,会显示一个Load a new file的界面。这里可以选择:
1. 程序的类型;
2. 处理器的类型;
3. 加载的段地址和偏移量;
4. 是否允许分析;
5. 一些加载选项;
6. 内核和处理器的一些选项;
7. windows系统dll所在的目录。
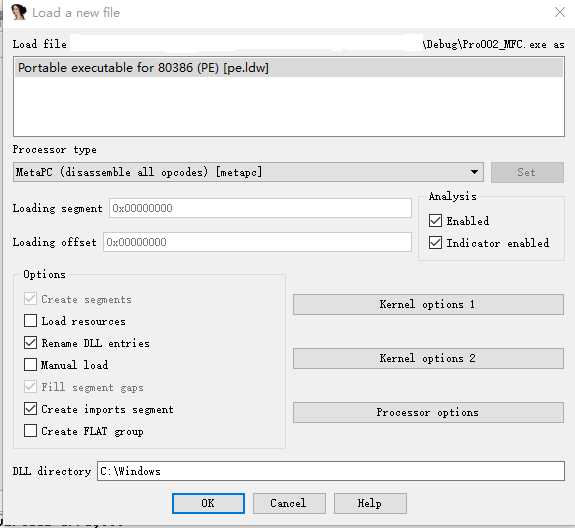
默认选择PE文件就可以,对于一些网络数据包或者其他格式的文件,可以使用二进制加载,自己进行解析。
工作区有多个子窗口,
- IDA View-A是反汇编窗口,
- HexView-A是十六进制格式显示的窗口,
- Imports是导入表(程序中调用到的外面的函数),
- Functions是函数表(这个程序中的函数),
- Structures是结构,
- Enums是枚举。
IDA view: 定位要修改的代码段在哪里。
Hex view: 用来修改我们的数据
exports window: 导出窗口
import window: 导入窗口
names window: 函数和参数的命名列表
functions window: 样本的所有函数窗口
strings window: 字符串显示窗口,会列出程序中的所有字符串
IDA很智能,鼠标移到某些标识符上会自动有适当的提示,双击还能自动跳到相应的位置。把一个函数逆向的方法很简单,只要按F5键就会出来逆向出的C语言程序了。
退出IDA时,会进行文件保存确认,如果需要继续进行分析,将IDA中间数据库打包,下次继续打开就可以进行分析;如果不需要继续分析,选择不要打包,不要存储数据库。
IDA打开应用程序时,会为其创建一个数据库,后缀为IDB。IDB由4个文件组成:
- 后缀为id0的二叉树形式的数据库,
- 后缀为id1的程序字节标识,
- 后缀为nam的Named窗口的索引信息,
- 后缀为til的给定数据库的本地类型定义的相关信息。
一旦IDA为某个可执行程序创建数据库,它本身就不再需要访问这个可执行文件,除非使用IDA的Debug功能。
跳转指令分三类:
- 无条件跳转: JMP;
- 根据 CX、ECX 寄存器的值跳转: JCXZ(CX 为 0 则跳转)、JECXZ(ECX 为 0 则跳转);
- 根据 EFLAGS 寄存器的标志位跳转, 这个太多了.
学 Win32 汇编[28] - 跳转指令: JMP、JECXZ、JA、JB、JG、JL、JE、JZ、JS、JC、JO、JP 等
— MOVSX MOVZX
比如
MOVSX EAX, BYTE PTR [00401000]
或
MOVZX EAX, BYTE PTR [00401000]
在C语言中应该如何表达啊?
比如定义一个全局变量
BYTE bt = 101;
DWORD dw;
应该如何把bt赋值到dw中. 并且功能与MOVSX/MOVZX相同?
汇编语言与C语言的语言构件不同,并不是一定能转成完全等价的C语言的代码的。
对于以上代码,可以这样理解:
movsx ====> dw = (DWORD) ( (signed char) (bt) )
movzx ====> dw = (DWORD) ( (unsigned char) (bt) )
movzx是把高位全部用0填充,而movsx是把原来数的最高位扩展成超出的位。
对于bt=101,也就是0x65,八位二进制是“01100101”,因为它的最高位是0,因此这两种情况,dw都等于0x00000065
换一个,比如bt=247,也就是0xF7,八位二进制是“11111110”它的最高位是1。
经过movsx变换后,dw等于0xfffffff7;
而经过movzx变换后,dw等于0x000000f7
交叉参考
通过交叉参考(XREF)可以知道指令代码互相调用的关系.如下:
.text:00401165 loc_401165: ;CODE XREF:sub_401120+B|j
这句CODE XREF:sub_401120+B|j 表示该调用地址是401120,
“j”表示跳转(jump)
“o”表示偏移值(offset)
“p”表示子程序(procedure)
双击这里或按回车键可以跳到调用该处的地方
参考重命名:
找到一段代码(一般为函数入口名),右键点击选择”Rename”可以将函数名称变成易懂的名称.
标签的用法:
在菜单”Jump”中选择”Mark Position” 将会打开 标记当前位置功能,输入一个名称, 在菜单”Jump/Jump to marked position” 中或按”Ctrl+M”键双击想要调转的名称,便会到达制定的代码位置.
进制的转换:
选择快捷键的#可以转换进制,选择”Toggle leading zeroes”功能是用0填补数据前的空位.
cqd,为Convert Double to Quad的缩写,意为将双字数据扩展为四字。
该指令先把edx的每一位置成eax的最高位(若eax>=0x80000000, 则edx=0xFFFFFFFF;若eax<0x80000000,则edx=0x00000000) ,再把edx扩展为eax的高位。
该指令常用于扩展被除数,很久前,指令集规定除数必须是被除数的一半长,这个规定一直被沿用。使用IDIV执行除法时,如果除数是32位,这就要求被除数是64位,即EDX:EAX,所以扩展一下EAX以满足除法指令的条件并且得到正确的结果。
DIV 和IDIV
DIV和IDIV两个都是算术除法操作指令。DIV是无符号数除法 DIV s ;完成两个无符号数相除。
IDIV 是有符号数除法指令,完成两个有符号数相除。被除数、商、除数、余数存放位置及对s的规定与DIV指令相同。

修改程序的指令或者数据,并进行保存
如何修改数据
在Hex View窗口下,
[S1]双击要修改的地方
[S2]使用F2捷方式修改当前字节
[S3]再按下F2快捷方式应用修改。
如何改变执行流程
[1]修改跳转指令。
[2]修改内存数据。
[3]IDA View中使用下面的命令Jump to IP,Set IP, Run to cursor。
保存修改
使用下面的主菜单命令,直接把修改保存到输入文件中,即可。
[IDA Main Menu]->[Edit]->[PatchProgram]->[Apply patches to input file…]。
OD中右键-保存到文件-选择
我的OD是这样的,只能修改一条,通过选择,保存一条重新载入再修改再保存.
如何对DLL文件进行动态跟踪
- 用[F2]在IDA View中当前代码行切换断点。
- 启动装载DLL的EXE文件。
- 使用[Debugger]->[Attach toprocess]把当前二进制代码attach到正在运行的进程中去。
- 现在应该进入断点。[F7]Stepinto。[F8]Stepover。[F9]continue。
- Cursor移到内存位置后双击就可以查看到具体内存中的值,右击快捷菜单[Jumpto IP]项,可以回到你刚才指令的地方。
- IDA View中有很多行代码,可以使用[;]快捷键对当前行进行注释。
- 为了观察具体指令的二进制表示你还需要[IDAView]->[右击快捷菜单]->[Synchronize with]->[Hex View 1]这样Hex View会和你的IDA View中光标位置同步。
- 在IDA View中为函数改名,用[N]快捷键。
- 观察内存(变量)[Tool bar]->[Open the watch list window],[Toolbar]->[Add a variable towatch]。
- 如果作者混淆了二进制代码,你需要IDAView在频繁使用[D]ata快捷键,[C]ode快捷键,强制IDA,解析指定数据块为数据(Data)或代码(Code)。
这些32位寄存器有多种用途,但每一个都有“专长”,有各自的特别之处。
EAX 是”累加器”(accumulator), 它是很多加法乘法指令的缺省寄存器。
EBX 是”基地址”(base)寄存器, 在内存寻址时存放基地址。
ECX 是计数器(counter), 是重复(REP)前缀指令和LOOP指令的内定计数器。
EDX 则总是被用来放整数除法产生的余数。
ESI/EDI 分别叫做”源/目标索引寄存器”(source/destination index),因为在很多字符串操作指令中, DS:ESI指向源串,而ES:EDI指向目标串.
EBP 是”基址指针”(BASE POINTER), 它最经常被用作高级语言函数调用的”框架指针”(frame pointer). 在破解的时候,经常可以看见一个标准的函数起始代码:
push ebp ; 保存当前ebp
mov ebp,esp ; EBP设为当前堆栈指针
sub esp, xxx ; 预留xxx字节给函数临时变量.
…
这样一来,EBP 构成了该函数的一个框架, 在EBP上方分别是原来的EBP, 返回地址和参数. EBP下方则是临时变量. 函数返回时作 mov esp,ebp/pop ebp/ret 即可.
ESP 专门用作堆栈指针,被形象地称为栈顶指针,堆栈的顶部是地址小的区域,压入堆栈的数据越多,ESP也就越来越小。在32位平台上,ESP每次减少4字节。
汇编中的ASSUME
经常用来将寄存器当作结构体指针来用
ASSUME edx:ptr STRUCT ;
将edx 定义为STRUCT指针变量把STRUCT结构体的起始地址给edx
lea edx, STRUCT
这个时候可以用 [edx].调用STRUCT的字段
ASSUME edx:nothing ;
取消定义 这个时候edx 不是指针
[edx].不能调用字段了
如果是8086的那么将段REG ASSUME DS:(某个数据段)
这样程序在使用这个数据段会用DS做段
Code段是不能指定段REG的 必须是CS:IP(EA)
快捷键
1. 按空格键切换反汇编窗口(列表视图《=====》图形视图)
反汇编窗口有两种显示格式:面向文本的列表视图和图形视图。不同视图在不同的场景下各有所长,按空格键可以快速切换。
2. 翻页 esc 和 Ctrl+Enter
当执行跳转功能后,需要返回时,只要在工具栏中点击 <- 或按Esc键,列表便会往后跳一页;
若要往前一页,点击 -> 或按”Ctrl+Enter”键.
3. 注释 “;”和”:”
按;号输入的注释,所有交叉参考处都会出现,
按:号键输入的注释只在该处出现
4. 使用小键盘“-”,“+”查看函数之间的关系
IDAView下使用小键盘“-”,“+”快捷方式可以在代码同关系图之间切换。
5. 使用[X]查看符号引用
IDA View下使用[X]快捷方式,定位引用了当前符号的代码。
6. 快捷键F5显示C伪代码
如果有[Main menu]->[View]->[Open SubViews]->[Pseudocode F5]菜单,说明你已经安装了Hex Rays decompiler插件,可以在查看汇编的时候,按[F5]打开伪代码子窗口。
7. 使用快捷键”*”把变量重定义为数组。
8. 快捷键Ctrl+S,打开搜索类型选择对话框–>双击Strings,跳到字符串段–>菜单项“Search–>Text”;
9. 快捷键Alt+T,打开文本搜索对话框,在String文本框中输入要搜索的字符串点击OK即可;
Open Subviews
| 窗口名称 | 快捷键 |
|---|---|
| Names Window | Shift+F4 |
| Functions Window | Shift+F3 |
| Strings Window | Shift+F12 |
| Segments | Shift+F7 |
| Segment registers | Shift+F8 |
| Signatures | Shift+F5 |
| Type libraries | Shift+F11 |
| Structures | Shift+F9 |
| Enumerations | Shift+F10 |
Data Format Options
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| ASCII strings style | Alt+A | |
| Setup data types | Alt+D |
File Operations
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Parse C header file | Ctrl+F9 | |
| Create ASM file | Alt+F10 | |
| Save database | Ctrl+W |
Navigation
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Jump to operand | Enter | |
| Jump in new window | Alt+Enter | |
| Jump to previous position | Esc | |
| Jump to next position | Ctrl+Enter | |
| Jump to address | G | |
| Jump by name | Ctrl+L | |
| Jump to function | Ctrl+P | |
| Jump to segment | Ctrl+S | |
| Jump to segment register | Ctrl+G | |
| Jump to problem | Ctrl+Q | |
| Jump to cross reference | Ctrl+X | |
| Jump to xref to operand | X | |
| Jump to entry point | Ctrl+E | |
| Mark Position | Alt+M | |
| Jump to marked position | Ctrl+M |
Debugger
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Start process | F9 | |
| Terminate process | Ctrl+F2 | |
| Step into | F7 | |
| Step over | F8 | |
| Run until return | Ctrl+F7 | |
| Run to cursor | F4 |
Breakpoints
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Breakpoint list | Ctrl+Alt+B |
Watches
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Delete watch | Del |
Tracing
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Stack trace | Ctrl+Alt+S |
Search
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Next code | Alt+C | |
| Next data | Ctrl+D | |
| Next explored | Ctrl+A | |
| Next unexplored | Ctrl+U | |
| Immediate value | Alt+I | |
| Next immediate value | Ctrl+I | |
| Text | Alt+T | |
| Next text | Ctrl+T | |
| Sequence of bytes | Alt+B | |
| Next sequence of bytes | Ctrl+B | |
| Not function | Alt+U | |
| Next void | Ctrl+V | |
| Error operand | Ctrl+F |
Graphing
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Flow chart | F12 | |
| Function calls | Ctrl+F12 |
Miscellaneous
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Calculator | ? | |
| Cycle through open views | Ctrl+Tab | |
| Select tab | Alt + [1…N] | |
| Close current view | Ctrl+F4 | |
| Exit | Alt+X | |
| IDC Command | Shift+F2 |
Edit (Data Types – etc)
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Copy | Ctrl+Ins | |
| Begin selection | Alt+L | |
| Manual instruction | Alt+F2 | |
| Code | C | |
| Data | D | |
| Struct variable | Alt+Q | |
| ASCII string | A | |
| Array | Num * | |
| Undefine | U | |
| Rename | N |
Operand Type
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Offset (data segment) | O | |
| Offset (current segment) | Ctrl+O | |
| Offset by (any segment) | Alt+R | |
| Offset (user-defined) | Ctrl+R | |
| Offset (struct) | T | |
| Number (default) | # | |
| Hexadecimal | Q | |
| Decimal | H | |
| Binary | B | |
| Character | R | |
| Segment | S | |
| Enum member | M | |
| Stack variable | K | |
| Change sign | Underscore (_) | |
| Bitwise negate | ~ | |
| Manual | _ Alt+F1 |
Comments
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Enter comment | : | |
| Enter repeatable comment | ; | |
| Enter anterior lines | Ins | |
| Enter posterior lines | Shift+Ins | |
| Insert predefined comment | Shift+F1 |
Segments
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Edit segment | Alt+S | |
| Change segment register value | Alt+G |
Structs
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Struct var | Alt+Q | |
| Force zero offset field | Ctrl+Z | |
| Select union member | Alt+Y |
Functions
| 窗口名称 | 快捷键 | 备注 |
|---|---|---|
| Create function | P | |
| Edit function | Alt+P | |
| Set function end | E | |
| Stack variables | Ctrl+K | |
| Change stack pointer | Alt+K | |
| Rename register | V | |
| Set function type | Y |
Note:
1. IDA不提供撤销功能,如果不小心按下某键,导致IDB数据库文件发生意外,是无法进行回退操作的。
PEID
扫描模式编辑
●正常扫描模式:可在PE文档的入口点扫描所有记录的签名;
●深度扫描模式:可深入扫描所有记录的签名,这种模式要比上一种的扫描范围更广、更深入;
●核心扫描模式:可完整地扫描整个PE文档,建议将此模式作为最后的选择。PEiD内置有差错控制的技术,所以一般能确保扫描结果的准确性。前两种扫描模式几乎在瞬间就可得到结果,最后一种有点慢,原因显而易见
转CSDN文章:原链接如下https://blog.csdn.net/baidu_39511645/article/details/78439730
以上是关于IDA使用技巧及大杂烩的主要内容,如果未能解决你的问题,请参考以下文章
《嵌入式 - 嵌入式大杂烩》一文搞懂CPUMPUMCUSOC的联系与区别