天池nlp文本分类新人赛 Task.1md
Posted zuotongbin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了天池nlp文本分类新人赛 Task.1md相关的知识,希望对你有一定的参考价值。
赛题解读:
https://tianchi.aliyun.com/notebook-ai/detail?spm=5176.12586969.1002.6.6406111aIKCSLV&postId=118252
赛题报名:
https://tianchi.aliyun.com/competition/entrance/531810/introduction
注意下提交时间和提交次数。
第一阶段(7月15日-9月7日)每天提供2次的评测机会,提交后将进行实时评测;排行榜每小时更新,按照评测指标得分从高到低排序;(排行榜将选择选手在本阶段的历史最优成绩进行排名展示,不做最终排名计算)
第二阶段(9月7日~9月8日)系统将在7日11:00提供新测试数据,并清空排行榜进行重新排名,参赛团队需要再次下载数据文件,每天提供2次的评测机会,提交后将进行实时评测;排行榜每小时更新
因为是学习的心态,所以想把常用的方案都尝试以下。
今天实现思路一,并分析其中的问题。
思路一:TF-IDF + 机器学习分类器
TF-IDF。TF表示词条在文本中出现的概率。一般会归一化。
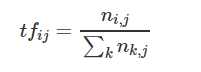
IDF是总文件数目处以包含该词语的文件的数目,再取对数。如果包含词条t的文档越少,则IDF越大,说明词条有很少的区分能力。
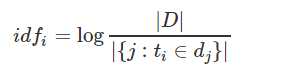
为了避免分母为0,分母+1。
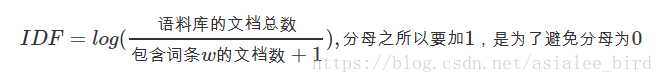
提取tf_idf代码:
def tf_idf(contents):
# 提取文本特征tf-idf
vectorizer = CountVectorizer(min_df=1e-5)
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(contents))
return tfidf
lgbm
# lgb
import lightgbm as lgb
from sklearn.model_selection import GridSearchCV
X_train_, X_val_, y_train_, y_val_ = train_test_split(X_train, y_train, test_size=0.2, shuffle=True, random_state=2020)
# cv_params = { ‘n_estimators‘:[100,150,200,250,300],
# ‘num_leaves‘:[15,20,25,30,35,40,45,50],
# ‘max_depth‘:[3,4,5,6,7,8,9],
# ‘min_data_in_leaf‘:[18,19,20,21,22],
# ‘min_sum_hessian_in_leaf‘:[0.001,0.002],
# ‘feature_fraction‘:[0.6,0.7,0.8,0.9,1.0],
# ‘bagging_fraction‘:[0.6,0.7,0.8,0.9,1.0],
# ‘bagging_freq‘:[2,4,6,8,10],
# ‘lambda_l1‘:[1e-3,1e-2,0.0,0.1,0.2,0.3,0.4,0.5],
# ‘lambda_l2‘:[1e-3,1e-2,0.0,0.1,0.2,0.3,0.4,0.5],
# ‘learning_rate‘:[0.01,0.02,0.05,0.07,0.09,0.1,0.15,0.2]
# }
model = lgb.LGBMClassifier(
boosting = ‘gbdt‘,
objective = ‘multiclass‘, #分类用binary,多分类用multi-class,回归用regression
num_class = 14,
metrics = ‘multi_logloss‘,
n_estimators = 100,
num_leaves = 30, #搭配max_septh使用,取值<=2^(max_depth),否则过拟合,单独调时可使得max_depth=-1,表示不限制树的深度
max_depth = 5,
min_data_in_leaf = 15,
min_sum_hession_in_leaf = 0.005,
feature_fraction = 0.8,
bagging_fraction = 0.8,
bagging_freq = 5,
lambda_l1 = 0.1,
lambda_l2 = 0.1,
learning_rate = 0.1
)
#optimized_lgb=GridSearchCV(estimator=model, param_grid=cv_params, scoring=‘f1‘, cv=3, verbose=20, n_jobs=-1)
# optimized_lgb.fit(X_train, y_train)
# y_test_preds = optimized_lgb.predicted(X_val)
# best_model = optimized_lgb.best_estimator_
# best_model.fit(X_train, y_train, val_set=None, eval_metric=‘f1‘, early_stopping_rounds=100)
# print(best_model.feature_importances_)
# best_params = optimized_lgb.best_params_
# best_score = optimized_lgb.best_score_
# y_test_preds = best_model.predict(X_test)
model.fit(X_train, y_train)
y_test_preds = model.predict(X_test)
xgboost
# xgb
from xgboost import XGBClassifier
class XGB():
def __init__(self, X_df, y_df):
self.X = X_df
self.y = y_df
def train(self, param):
self.model = XGBClassifier(**param)
self.model.fit(self.X, self.y, eval_set=[(self.X, self.y)],
eval_metric=[‘mlogloss‘],
early_stopping_rounds=10, # 连续N次分值不再优化则提前停止
verbose=True
)
# mode evaluation
train_result, train_proba = self.model.predict(self.X), self.model.predict_proba(self.X)
train_acc = accuracy_score(self.y, train_result)
train_auc = f1_score(self.y, train_proba, average=‘macro‘)
print("Train acc: %.2f%% Train auc: %.2f" % (train_acc*100.0, train_auc))
def test(self, X_test, y_test):
result, proba = self.model.predict(X_test), self.model.predict_proba(X_test)
acc = accuracy_score(y_test, result)
f1 = f1_score(y_test, proba, average=‘macro‘)
print("acc: %.2f%% F1_score: %.2f%%" % (acc*100.0, f1))
def grid(self, param_grid):
self.param_grid = param_grid
xgb_model = XGBClassifier(nthread=20)
clf = GridSearchCV(xgb_model, self.param_grid, scoring=‘f1_macro‘, cv=2, verbose=1)
clf.fit(self.X, self.y)
print("Best score: %f using parms: %s" % (clf.best_score_, clf.best_params_))
return clf.best_params_, clf.best_score_
param = {‘learning_rate‘: 0.05, # (xgb’s “eta”)
‘objective‘: ‘multi:softmax‘,
‘n_jobs‘: 16,
‘n_estimators‘: 300, # 树的个数
‘max_depth‘: 10,
‘gamma‘: 0.5, # 惩罚项中叶子结点个数前的参数,Increasing this value will make model more conservative.
‘reg_alpha‘: 0, # L1 regularization term on weights.Increasing this value will make model more conservative.
‘reg_lambda‘: 2, # L2 regularization term on weights.Increasing this value will make model more conservative.
‘min_child_weight‘ : 1, # 叶子节点最小权重
‘subsample‘:0.8, # 随机选择80%样本建立决策树
‘random_state‘:1 # 随机数
}
X_train_, X_val_, y_train_, y_val_ = train_test_split(X_train, y_train, test_size=0.2, shuffle=True, random_state=2020)
model = XGB(X_train_, y_train_)
model.train(param)
model.test(X_val_, y_val_)
贝叶斯
NB_model = MultinomialNB(alpha=0.01)
NB_model.fit(X_train, y_train)
Y_val_preds = NB_model.predict(X_val)
print(f1_score(y_val, Y_val_preds, average=‘macro‘))
LR
# 逻辑回归
from sklearn.linear_model import LogisticRegressionCV
lr_model = LogisticRegressionCV(solver=‘newton-cg‘, multi_class=‘multinomial‘, cv=5, n_jobs=-1, verbose = True)
lr_model.fit(X_train, y_train)
# Y_val_preds = lr_model.predict(X_val)
# print(f1_score(y_val, Y_val_preds, average=‘macro‘))
SVM
from sklearn.svm import SVC
svm_model = SVC(kernel="linear", verbose=True)
svm_model.fit(X_train, y_train)
Y_val_preds = svm_model.predict(X_val)
print(f1_score(y_val, Y_val_preds, average=‘macro‘))
KNN
# KNN
from sklearn.neighbors import KNeighborsClassifier
for x in range(1, 15):
knn_model = KNeighborsClassifier(n_neighbors=x)
knn_model.fit(X_train, y_train)
Y_val_preds = knn_model.predict(X_val)
print("n_neighbors = {}".format(n_neighbors), f1_score(y_val, Y_val_preds, average=‘macro‘))
TF-IDF优点是简单快速。
缺点:
- 没有考虑特征词的位置因素对文本的区分度
- 一些生僻字出现的很少,往往会被误认为文档关键词
- 简单的TF-IDF只考虑特征词与它文本数之间的关系,忽略了特征项在一个类别中不同的类别间的分布情况。
以上是关于天池nlp文本分类新人赛 Task.1md的主要内容,如果未能解决你的问题,请参考以下文章