分布式任务调度平台 → XXL-JOB 初探
Posted youzhibing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式任务调度平台 → XXL-JOB 初探相关的知识,希望对你有一定的参考价值。
开心一刻
旁边的女乘客太吵,我实在忍无可忍,便对她说:“你能不能让我睡会儿?”
她挥手就给了我一个耳光:“你个臭流氓!”
我顿时就清醒了,理论到:“你让我睡一会怎么了吗”
她害羞的低下了头,说道:“人家不是随便的人”
我:“我也不是随便的人,下一站我们下车把话说清楚”

任务调度
相信大家对任务调度都不陌生,说的通熟一点就是定时任务;这个在我们的项目中或多或少都存在,我们可以用 JDK 自带的(Timer、ScheduledExecutor)来实现,也可以用 Spring 的 Scheduler 来实现,不管用以上哪种方式,我们都是在单机上跑,如果我们以集群的方式部署,会不会出现什么问题 ?
集群中的各个节点都会执行定时调度,会有重复执行的问题,那怎么办? 我们可以加配置,只启动某个节点的定时任务,但是这时候又会出现单点问题
那有没有什么办法,既能避免重复执行,又不会出现单点问题呢? 分布式调度应运而生,常见的分布式任务调度框架有:quartz 、cronsun、Elastic-job、saturn、lts、TBSchedule、xxl-job 等
quartz 我已经简单讲过,有兴趣的可以去看看:请点我,你们会发现:楼主压根就没讲 quartz 的集群模式。你们发现的很对,我就是没讲,就问你气不气 ?

既然你们对 quartz 已经有了一定的了解了 ,那么它的集群模式交给你们自己了
今天我们就一起来了解下另外一个分布式调度平台:xxl-job
关于 xxl-job 是什么、有什么特性、发展历程、接入了哪些公司、各个版本的新特性等等问题,我都不会去讲,因为官方文档已经说的非常清楚了。xxl-job 是国产的,如果文档还看不懂,那就需要回学校再造了。但是我还是想强调下它的架构图
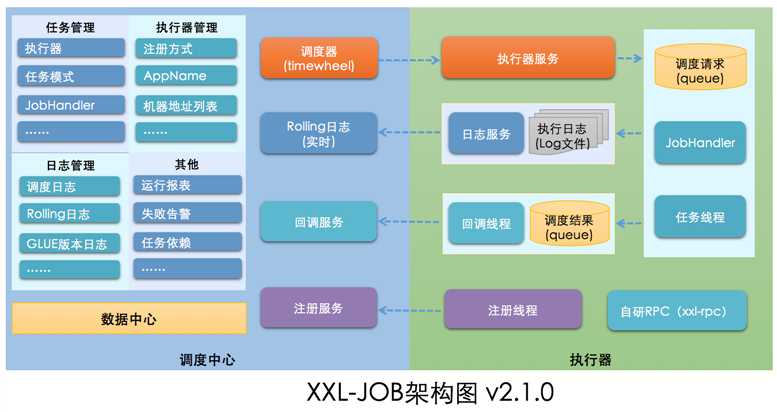
通过这个架构图,我们可以对其有个大致的了解;大体上分为调度中心 和 执行器,调度中心通过调度规则(cron表达式)对执行器中的任务进行调度,执行器收到调度后,执行具体的任务(Job)
既然官方文档都说的非常细致了,那我还能讲什么呢 ? 好像确实么什么可以说的了, 那今天就到这吧,大家散会!

大家先别急着走,虽然下面的内容在官方文档中已经存在,但是却很容易被我们忽略;我会在搭建的过程中来穿插着一些问题,来巩固我们容易忽略的点
单节点搭建
我们先搭一个简单的,调度中心 和 执行器 都先搭建成单节点
按照官方的文档来,一步一步很容易搭建成功
源码下载
源码地址:xxl-job,可以 git clone 也可以 Download ZIP ,不管何种方式,我们拿到了源码,导入到 IDEA,结构如下

初始化 “调度数据库”
SQL 脚本在源码中已存在,路径: xxl-job-masterdocdb ables_xxl_job.sql ,执行此脚本,创建数据库和表,如下图
配置&部署 调度中心
配置文件: appliction.properties ,内容如下


### web server.port=8080 server.servlet.context-path=/xxl-job-admin ### actuator management.server.servlet.context-path=/actuator management.health.mail.enabled=false ### resources spring.mvc.servlet.load-on-startup=0 spring.mvc.static-path-pattern=/static/** spring.resources.static-locations=classpath:/static/ ### freemarker spring.freemarker.templateLoaderPath=classpath:/templates/ spring.freemarker.suffix=.ftl spring.freemarker.charset=UTF-8 spring.freemarker.request-context-attribute=request spring.freemarker.settings.number_format=0.########## ### mybatis mybatis.mapper-locations=classpath:/mybatis-mapper/*Mapper.xml #mybatis.type-aliases-package=com.xxl.job.admin.core.model ### xxl-job, datasource spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai spring.datasource.username=root spring.datasource.password=root_pwd spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver ### datasource-pool spring.datasource.type=com.zaxxer.hikari.HikariDataSource spring.datasource.hikari.minimum-idle=10 spring.datasource.hikari.maximum-pool-size=30 spring.datasource.hikari.auto-commit=true spring.datasource.hikari.idle-timeout=30000 spring.datasource.hikari.pool-name=HikariCP spring.datasource.hikari.max-lifetime=900000 spring.datasource.hikari.connection-timeout=10000 spring.datasource.hikari.connection-test-query=SELECT 1 ### xxl-job, email spring.mail.host=smtp.qq.com spring.mail.port=25 spring.mail.username=xxx@qq.com spring.mail.from=xxx@qq.com spring.mail.password=xxx spring.mail.properties.mail.smtp.auth=true spring.mail.properties.mail.smtp.starttls.enable=true spring.mail.properties.mail.smtp.starttls.required=true spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory ### xxl-job, access token xxl.job.accessToken= ### xxl-job, i18n (default is zh_CN, and you can choose "zh_CN", "zh_TC" and "en") xxl.job.i18n=zh_CN ## xxl-job, triggerpool max size xxl.job.triggerpool.fast.max=200 xxl.job.triggerpool.slow.max=100 ### xxl-job, log retention days xxl.job.logretentiondays=30
需要改的地方不多,端口号可能需要根据实际情况进行修改,然后就是数据库的地址、用户名和密码需要改成自己的,email服务器最好配上(告警用的上),调度中心与执行器之间的安全访问 token( xxl.job.accessToken ) 最好也配置上
出于演示,改下数据库的配置就好,其他的保持默认;我们启动调度中心,访问: http://localhost:8080/xxl-job-admin ,默认登录账号 “admin/123456”, 登录后运行界面如下图所示
“调度中心” 已经部署成功
配置&部署 执行器
配置文件: application.properties ,内容如下
# web port server.port=8081 # no web #spring.main.web-environment=false # log config logging.config=classpath:logback.xml ### xxl-job admin address list, such as "http://address" or "http://address01,http://address02" xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin ### xxl-job, access token xxl.job.accessToken= ### xxl-job executor appname xxl.job.executor.appname=xxl-job-executor-sample ### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null xxl.job.executor.address= ### xxl-job executor server-info xxl.job.executor.ip= xxl.job.executor.port=9999 ### xxl-job executor log-path xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler ### xxl-job executor log-retention-days xxl.job.executor.logretentiondays=30
端口号配置一个未被使用的端口,调度中心地址配置成我们之前部署的调度中心的地址即可;至于 xxl.job.accessToken ,和调度中心配置成一样即可
配置文件中各个配置的注释写的非常清楚,大家根据实际情况进行配置即可
执行器的示例有好几个,我们启动 springboot 版本的;启动不报错就行了,它会自动注册到调度中心,如下图

配置调度规则&任务
调度中心通过调度规则对执行器中的任务进行调度,现在调度中心和执行器都部署好了,就缺调度规则和任务了
任务在示例代码中已经存在了, SampleXxlJob.java :
package com.xxl.job.executor.service.jobhandler; import com.xxl.job.core.biz.model.ReturnT; import com.xxl.job.core.context.XxlJobContext; import com.xxl.job.core.handler.IJobHandler; import com.xxl.job.core.handler.annotation.XxlJob; import com.xxl.job.core.log.XxlJobLogger; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Component; import java.io.BufferedInputStream; import java.io.BufferedReader; import java.io.DataOutputStream; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.Arrays; import java.util.concurrent.TimeUnit; /** * XxlJob开发示例(Bean模式) * * 开发步骤: * 1、在Spring Bean实例中,开发Job方法,方式格式要求为 "public ReturnT<String> execute(String param)" * 2、为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。 * 3、执行日志:需要通过 "XxlJobLogger.log" 打印执行日志; * * @author xuxueli 2019-12-11 21:52:51 */ @Component public class SampleXxlJob { private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class); /** * 1、简单任务示例(Bean模式) */ @XxlJob("demoJobHandler") public ReturnT<String> demoJobHandler(String param) throws Exception { XxlJobLogger.log("XXL-JOB, Hello World."); for (int i = 0; i < 5; i++) { XxlJobLogger.log("beat at:" + i); TimeUnit.SECONDS.sleep(2); } return ReturnT.SUCCESS; } /** * 2、分片广播任务 */ @XxlJob("shardingJobHandler") public ReturnT<String> shardingJobHandler(String param) throws Exception { // 分片参数 int shardIndex = XxlJobContext.getXxlJobContext().getShardIndex(); int shardTotal = XxlJobContext.getXxlJobContext().getShardTotal(); XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal); // 业务逻辑 for (int i = 0; i < shardTotal; i++) { if (i == shardIndex) { XxlJobLogger.log("第 {} 片, 命中分片开始处理", i); } else { XxlJobLogger.log("第 {} 片, 忽略", i); } } return ReturnT.SUCCESS; } /** * 3、命令行任务 */ @XxlJob("commandJobHandler") public ReturnT<String> commandJobHandler(String param) throws Exception { String command = param; int exitValue = -1; BufferedReader bufferedReader = null; try { // command process Process process = Runtime.getRuntime().exec(command); BufferedInputStream bufferedInputStream = new BufferedInputStream(process.getInputStream()); bufferedReader = new BufferedReader(new InputStreamReader(bufferedInputStream)); // command log String line; while ((line = bufferedReader.readLine()) != null) { XxlJobLogger.log(line); } // command exit process.waitFor(); exitValue = process.exitValue(); } catch (Exception e) { XxlJobLogger.log(e); } finally { if (bufferedReader != null) { bufferedReader.close(); } } if (exitValue == 0) { return IJobHandler.SUCCESS; } else { return new ReturnT<String>(IJobHandler.FAIL.getCode(), "command exit value("+exitValue+") is failed"); } } /** * 4、跨平台Http任务 * 参数示例: * "url: http://www.baidu.com " + * "method: get " + * "data: content "; */ @XxlJob("httpJobHandler") public ReturnT<String> httpJobHandler(String param) throws Exception { // param parse if (param==null || param.trim().length()==0) { XxlJobLogger.log("param["+ param +"] invalid."); return ReturnT.FAIL; } String[] httpParams = param.split(" "); String url = null; String method = null; String data = null; for (String httpParam: httpParams) { if (httpParam.startsWith("url:")) { url = httpParam.substring(httpParam.indexOf("url:") + 4).trim(); } if (httpParam.startsWith("method:")) { method = httpParam.substring(httpParam.indexOf("method:") + 7).trim().toUpperCase(); } if (httpParam.startsWith("data:")) { data = httpParam.substring(httpParam.indexOf("data:") + 5).trim(); } } // param valid if (url==null || url.trim().length()==0) { XxlJobLogger.log("url["+ url +"] invalid."); return ReturnT.FAIL; } if (method==null || !Arrays.asList("GET", "POST").contains(method)) { XxlJobLogger.log("method["+ method +"] invalid."); return ReturnT.FAIL; } boolean isPostMethod = method.equals("POST"); // request HttpURLConnection connection = null; BufferedReader bufferedReader = null; try { // connection URL realUrl = new URL(url); connection = (HttpURLConnection) realUrl.openConnection(); // connection setting connection.setRequestMethod(method); connection.setDoOutput(isPostMethod); connection.setDoInput(true); connection.setUseCaches(false); connection.setReadTimeout(5 * 1000); connection.setConnectTimeout(3 * 1000); connection.setRequestProperty("connection", "Keep-Alive"); connection.setRequestProperty("Content-Type", "application/json;charset=UTF-8"); connection.setRequestProperty("Accept-Charset", "application/json;charset=UTF-8"); // do connection connection.connect(); // data if (isPostMethod && data!=null && data.trim().length()>0) { DataOutputStream dataOutputStream = new DataOutputStream(connection.getOutputStream()); dataOutputStream.write(data.getBytes("UTF-8")); dataOutputStream.flush(); dataOutputStream.close(); } // valid StatusCode int statusCode = connection.getResponseCode(); if (statusCode != 200) { throw new RuntimeException("Http Request StatusCode(" + statusCode + ") Invalid."); } // result bufferedReader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8")); StringBuilder result = new StringBuilder(); String line; while ((line = bufferedReader.readLine()) != null) { result.append(line); } String responseMsg = result.toString(); XxlJobLogger.log(responseMsg); return ReturnT.SUCCESS; } catch (Exception e) { XxlJobLogger.log(e); return ReturnT.FAIL; } finally { try { if (bufferedReader != null) { bufferedReader.close(); } if (connection != null) { connection.disconnect(); } } catch (Exception e2) { XxlJobLogger.log(e2); } } } /** * 5、生命周期任务示例:任务初始化与销毁时,支持自定义相关逻辑; */ @XxlJob(value = "demoJobHandler2", init = "init", destroy = "destroy") public ReturnT<String> demoJobHandler2(String param) throws Exception { XxlJobLogger.log("XXL-JOB, Hello World."); return ReturnT.SUCCESS; } public void init(){ logger.info("init"); } public void destroy(){ logger.info("destory"); } }
是一个任务集,里面每一个被 @XxlJob 修饰的都是一个任务,我们以名为: demoJobHandler 的任务来做演示
任务已经定好,目前就只差调度规则了,我们去调度中心管理界面进行配置;默认情况下,xxl-job 会帮我们自动配置好一个任务,如下
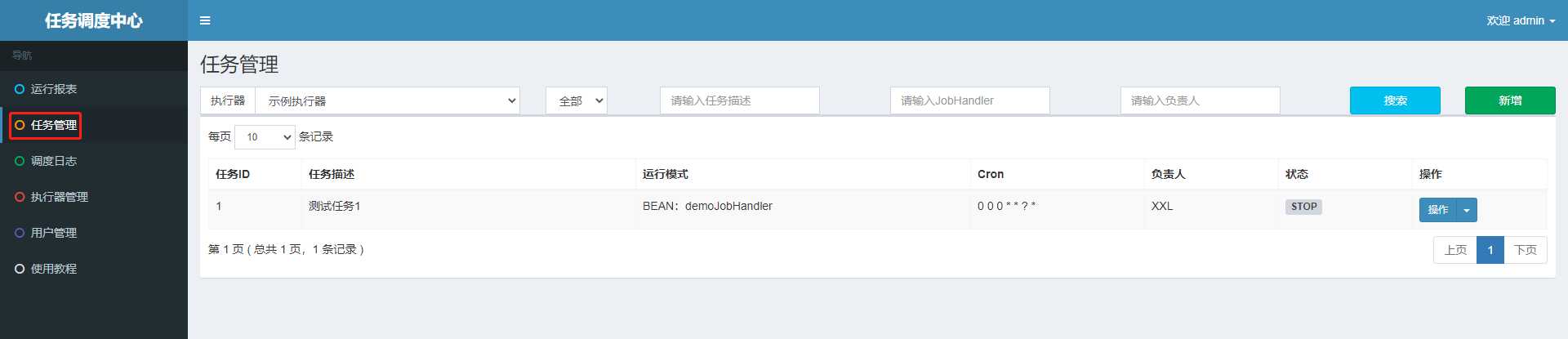
直接用它是可以的,但是为了清楚怎么配置,我们重新配置一个
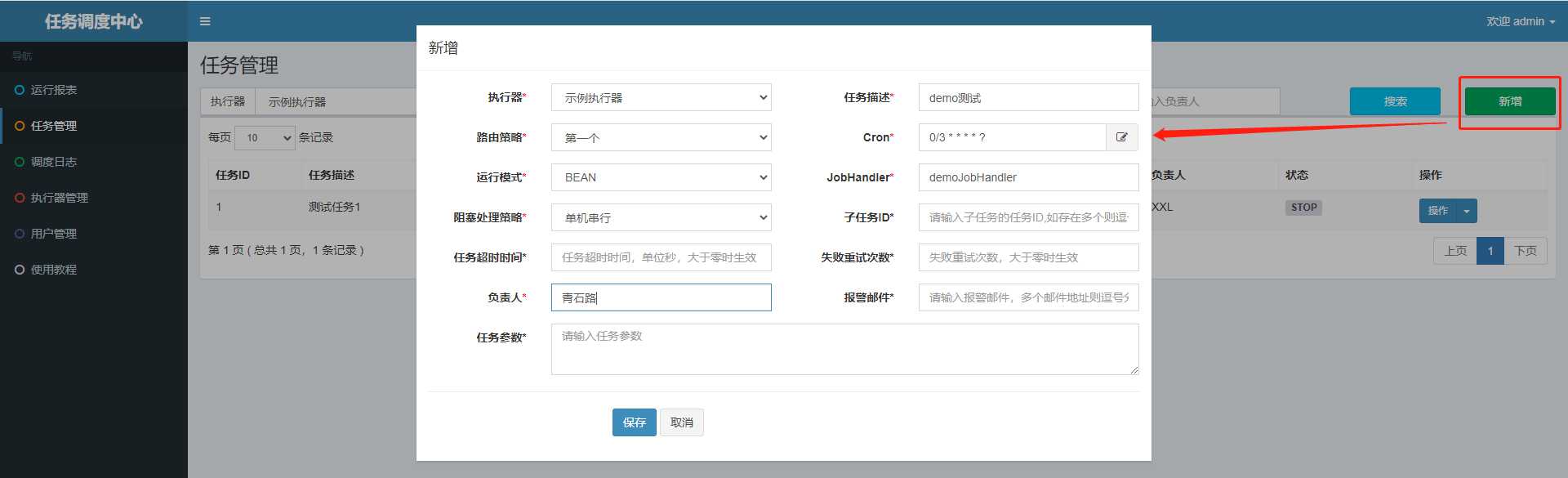
各个配置项的具体含义大家可以去看官方文档,里面都有详细的介绍;
简单点来说上图的配置,就是每隔 3 秒,调度中心会去调度 示例执行器 的 demoJobHandler 任务
启动调度
配置和部署都已完成,现在差的就是启动调度了,我们启动它
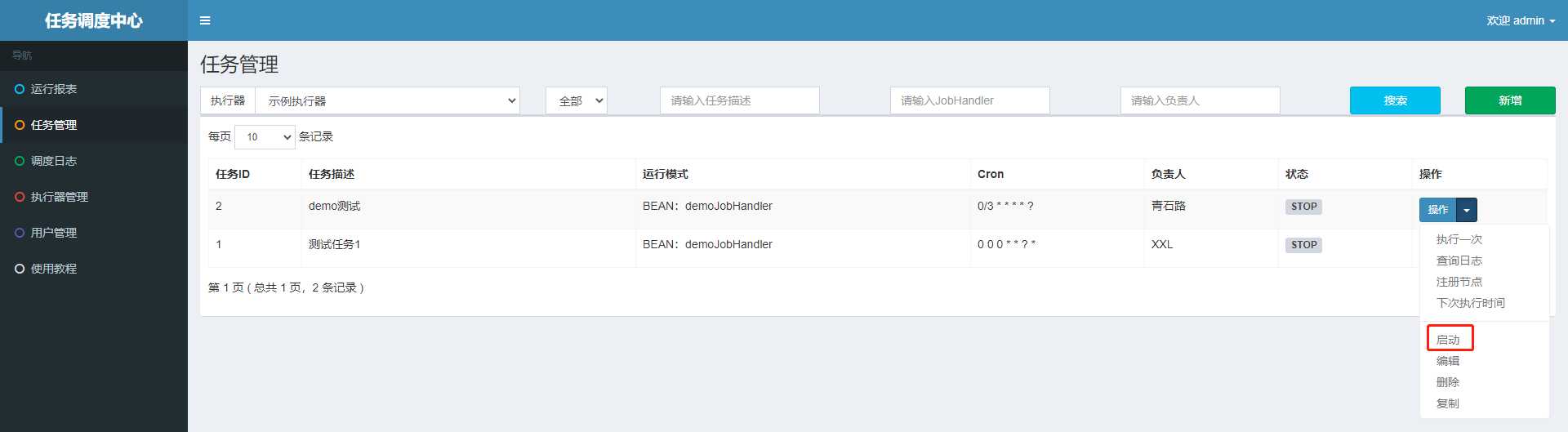
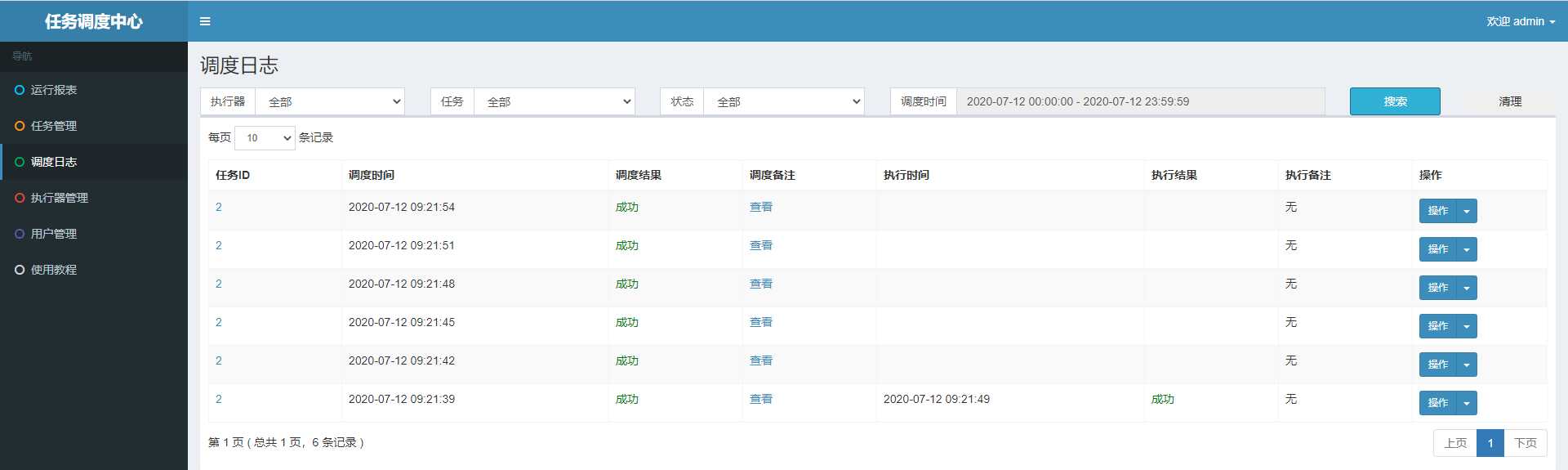
然后我们就可以在调度日志页面查看调度中心的调度日志了,如下所示
问题
现在不管是调度中心,还是执行器,都是单节点的,都存在单节点问题
那如何解决了,单节点的解决方案往往就是集群,我们可以将调度中心和执行器都部署成集群,而 xxl-job 又是支持的,而且集群部署非常简单、方便
集群搭建
集群架构图简单如下

nginx 只是对调度中心的请求(调度中心管理页面的操作)做负载均衡,它不涉及任务的调度与回调,这里就不配置 nginx 了, 我们重点来看下调度中心集群与执行器集群的搭建
调度中心集群
调度中心集群的搭建非常简单,只需要注意两点:DB配置保持一致,集群机器时钟保持一致(单机集群忽视)
出于演示,我们就做单机集群处理,那么我们只需要在 IDEA 中再启动一个调度中心节点就好,端口号配置不一样就好;调度中心共启动两个节点,之前的端口号是8080, 这个我们改成 8088
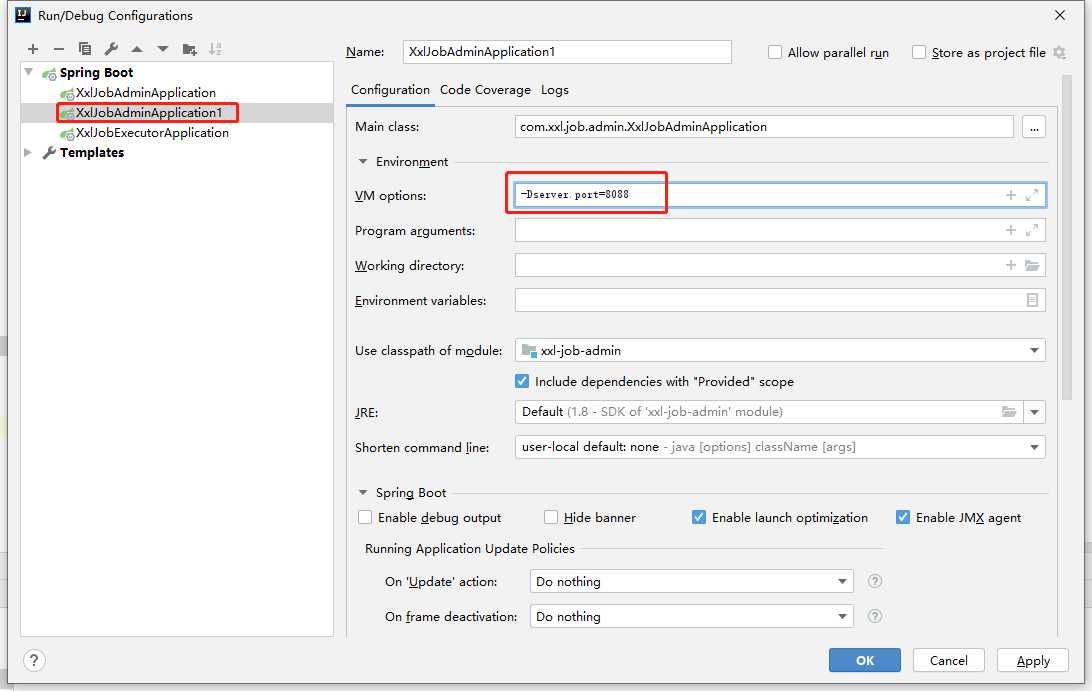
启动之后,我们就可以从http://localhost:8080/xxl-job-admin,http://localhost:8088/xxl-job-admin 对调度中心控制台进行访问了,具体就不演示了, 大家可以自行去操作
生产环境下,会通过 nginx 对外暴露唯一地址,由 nginx 对这两个(或者多个)进行负载均衡
执行器集群
搭建同样非常简单,只需要注意两点
1、执行器回调地址(xxl.job.admin.addresses)需要保持一致;执行器根据该配置进行执行器自动注册等操作。
2、同一个执行器集群内AppName(xxl.job.executor.appname)需要保持一致;调度中心根据该配置动态发现不同集群的在线执行器列表
由于是单机集群搭建,端口的唯一性也需要注意
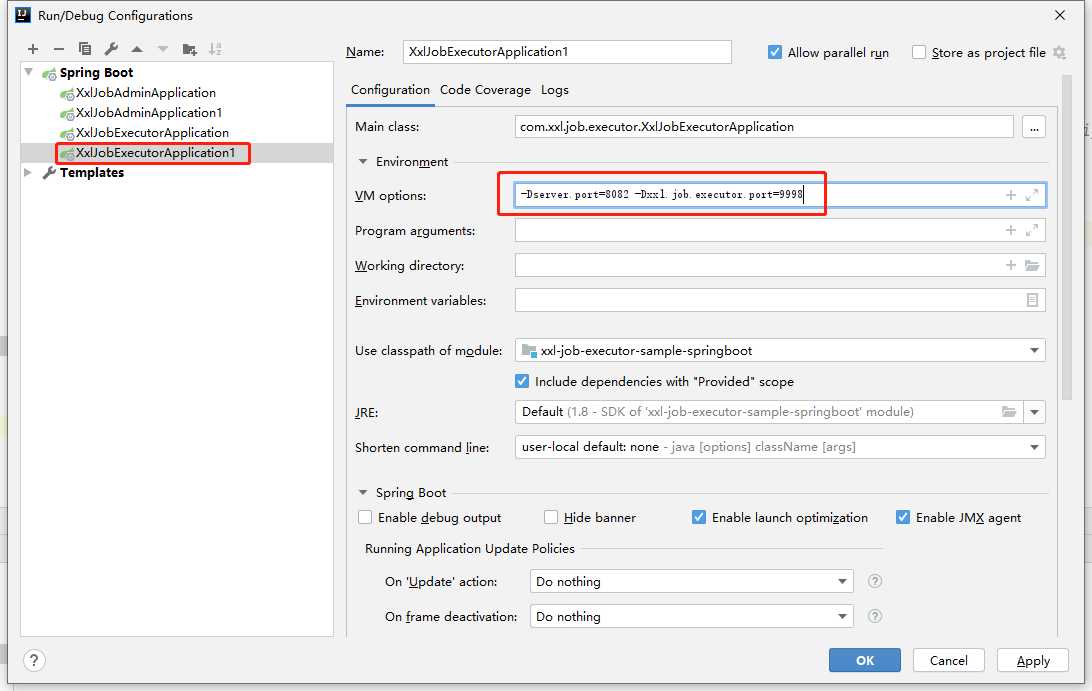
启动之后,去调度中心修改路由策略为轮训,再启动任务调度,然后就可以去查看调度日志了
宕机测试
这个就不演示了,大家自行去测试,停掉某个节点,整个调度是否能正常完成
疑问
1、调度中心集群部署,任务调度的时候,会不会每个节点都发起调度请求,从而产生重复调度的问题
这个问题在官方文档中有说明:基于数据库的集群方案,数据库选用Mysql;集群分布式并发环境中进行定时任务调度时,会在各个节点会上报任务,存到数据库中,执行时会从数据库中取出触发器来执行,如果触发器的名称和执行时间相同,则只有一个节点去执行此任务。
因此对同一个调度,不会产生重复调度问题
2、执行器集群收到调度请求后,会不会每个节点都去执行任务
这个问题不成立,我们不是配置了路由策略吗,调度中心会根据路由策略将调度请求发送给具体的某个执行器了,那何来每个执行器都执行任务呢 ?
如果官方文档看的细的话,我们会发现有如下一段话

不只异步调度和异步执行,其实还包括异步回调,xxl-job 中用到了大量的队列、异步处理
当然还有一些其他的疑问,绝大部分在官方文档都能找到答案,所以需要大家多读、细读
总结
1、单机模式,大家了解就好,生产环境肯定都是集群模式的;但 xxl-job 的集群部署也非常简单
2、xxl-job 的全异步化&轻量级设计,可以保证使用有限的线程支撑大量的JOB并发运行
3、通篇都是在 xxl-job 的源码上进行的,如何将它应用进我们的实战项目中了 ? 实战篇,我们下期见
参考
以上是关于分布式任务调度平台 → XXL-JOB 初探的主要内容,如果未能解决你的问题,请参考以下文章