Pytorch-Visdom可视化工具
Posted cxq1126
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch-Visdom可视化工具相关的知识,希望对你有一定的参考价值。
Visdom相比TensorBoardX,更简洁方便一些(例如对image数据的可视化可以直接使用Tensor,而不必转到cpu上再转为numpy数据),刷新率也更快。
1.安装visdom
pip install visdom
2.开启监听进程
visdom本质上是一个web服务器,开启web服务器之后程序才能向服务器丢数据,web服务器把数据渲染到网页中去。
python -m visdom.server
但是很不幸报错了!ERROR:root:Error [Errno 2] No such file or directory while downloading https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.1/MathJax.js?config=TeX-AMS-MML_SVG,所以从头再来,先pip uninstall visdom卸掉visdom,再手动安装。
- 从网站下载visdom源文件https://github.com/facebookresearch/visdom并解压
- command进入visdom所在文件目录,比如我的是cd F:Chrome_Downloadvisdom-master
- 进入目录后执行pip install -e .
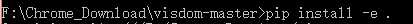
- 执行成功后,退回到用户目录,重新执行上面的python -m visidom.server
- 然后又报错了,一直提示Downloading scripts, this may take a little while,解决方案见https://github.com/casuallyName/document-sharing/tree/master/static
- 直到如图所示即启动成功

3.访问
用chrome浏览器访问url连接:http://localhost:8097
没想到又又报错了,页面加载失败(蓝色空白页面如下)

在visdom安装目录下(我的是F:AnacondaLibsite-packagesvisdom),将static文件夹换掉,下载地址为
链接:https://pan.baidu.com/s/1fZb-3GSZvk0kRpL73MBgcw
提取码:np04
直到出现横条框即visdom可用。

4.可视化训练
在之前定义网络结构(参考上一节)的基础上加上Visdom可视化。
- 在训练-测试的迭代过程之前,定义两条曲线,在训练-测试的过程中再不断填充点以实现曲线随着训练动态增长:
1 from visdom import Visdom 2 viz = Visdom() 3 viz.line([0.], [0.], win=‘train_loss‘, opts=dict(title=‘train loss‘)) 4 viz.line([[0.0, 0.0]], [0.], win=‘test‘, opts=dict(title=‘test loss&acc.‘,legend=[‘loss‘, ‘acc.‘]))
第二行Visdom(env="xxx")参数env来设置环境窗口的名称,这里什么都没传,在默认的main窗口下。
viz.line的前两个参数是曲线的Y和X的坐标(前面是纵轴后面才是横轴),设置了不同的win参数,它们就会在不同的窗口中展示,
第四行定义的是测试集的loss和acc两条曲线,所以在X等于0时Y给了两个初始值。
- 为了知道训练了多少个batch,设置一个全局的计数器:
1 global_step = 0
- 在每个batch训练完后,为训练曲线添加点,来让曲线实时增长:
1 global_step += 1 2 viz.line([loss.item()], [global_step], win=‘train_loss‘, update=‘append‘)
这里用win参数来选择是哪条曲线,用update=‘append‘的方式添加曲线的增长点,前面是Y坐标,后面是X坐标。
- 在每次测试结束后,并在另外两个窗口(用win参数设置)中展示图像(.images)和真实值(文本用.text):
1 viz.line([[test_loss, correct / len(test_loader.dataset)]], 2 [global_step], win=‘test‘, update=‘append‘) 3 viz.images(data.view(-1, 1, 28, 28), win=‘x‘) 4 viz.text(str(pred.detach().numpy()), win=‘pred‘, 5 opts=dict(title=‘pred‘))
附上完整代码:
1 import torch 2 import torch.nn as nn 3 import torch.nn.functional as F 4 import torch.optim as optim 5 from torchvision import datasets, transforms 6 from visdom import Visdom 7 8 #超参数 9 batch_size=200 10 learning_rate=0.01 11 epochs=10 12 13 #获取训练数据 14 train_loader = torch.utils.data.DataLoader( 15 datasets.MNIST(‘../data‘, train=True, download=True, #train=True则得到的是训练集 16 transform=transforms.Compose([ #transform进行数据预处理 17 transforms.ToTensor(), #转成Tensor类型的数据 18 transforms.Normalize((0.1307,), (0.3081,)) #进行数据标准化(减去均值除以方差) 19 ])), 20 batch_size=batch_size, shuffle=True) #按batch_size分出一个batch维度在最前面,shuffle=True打乱顺序 21 22 #获取测试数据 23 test_loader = torch.utils.data.DataLoader( 24 datasets.MNIST(‘../data‘, train=False, transform=transforms.Compose([ 25 transforms.ToTensor(), 26 transforms.Normalize((0.1307,), (0.3081,)) 27 ])), 28 batch_size=batch_size, shuffle=True) 29 30 31 class MLP(nn.Module): 32 33 def __init__(self): 34 super(MLP, self).__init__() 35 36 self.model = nn.Sequential( #定义网络的每一层, 37 nn.Linear(784, 200), 38 nn.ReLU(inplace=True), 39 nn.Linear(200, 200), 40 nn.ReLU(inplace=True), 41 nn.Linear(200, 10), 42 nn.ReLU(inplace=True), 43 ) 44 45 def forward(self, x): 46 x = self.model(x) 47 return x 48 49 50 net = MLP() 51 #定义sgd优化器,指明优化参数、学习率,net.parameters()得到这个类所定义的网络的参数[[w1,b1,w2,b2,...] 52 optimizer = optim.SGD(net.parameters(), lr=learning_rate) 53 criteon = nn.CrossEntropyLoss() 54 55 viz = Visdom() 56 viz.line([0.], [0.], win=‘train_loss‘, opts=dict(title=‘train loss‘)) 57 viz.line([[0.0, 0.0]], [0.], win=‘test‘, opts=dict(title=‘test loss&acc.‘, 58 legend=[‘loss‘, ‘acc.‘])) 59 global_step = 0 60 61 62 for epoch in range(epochs): 63 64 for batch_idx, (data, target) in enumerate(train_loader): 65 data = data.view(-1, 28*28) #将二维的图片数据摊平[样本数,784] 66 67 logits = net(data) #前向传播 68 loss = criteon(logits, target) #nn.CrossEntropyLoss()自带Softmax 69 70 optimizer.zero_grad() #梯度信息清空 71 loss.backward() #反向传播获取梯度 72 optimizer.step() #优化器更新 73 74 global_step += 1 75 viz.line([loss.item()], [global_step], win=‘train_loss‘, update=‘append‘) 76 77 78 if batch_idx % 100 == 0: #每100个batch输出一次信息 79 print(‘Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}‘.format( 80 epoch, batch_idx * len(data), len(train_loader.dataset), 81 100. * batch_idx / len(train_loader), loss.item())) 82 83 84 test_loss = 0 85 correct = 0 #correct记录正确分类的样本数 86 for data, target in test_loader: 87 data = data.view(-1, 28 * 28) 88 logits = net(data) 89 test_loss += criteon(logits, target).item() #其实就是criteon(logits, target)的值,标量 90 91 pred = logits.data.max(dim=1)[1] #也可以写成pred=logits.argmax(dim=1) 92 correct += pred.eq(target.data).sum() 93 94 95 viz.line([[test_loss, correct / len(test_loader.dataset)]], 96 [global_step], win=‘test‘, update=‘append‘) 97 viz.images(data.view(-1, 1, 28, 28), win=‘x‘) 98 viz.text(str(pred.detach().numpy()), win=‘pred‘, 99 opts=dict(title=‘pred‘)) 100 101 102 test_loss /= len(test_loader.dataset) 103 print(‘ Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%) ‘.format( 104 test_loss, correct, len(test_loader.dataset), 105 100. * correct / len(test_loader.dataset)))
Train Epoch: 0 [0/60000 (0%)] Loss: 2.307811
Train Epoch: 0 [20000/60000 (33%)] Loss: 2.051105
Train Epoch: 0 [40000/60000 (67%)] Loss: 1.513345
..atensrcATen
ativeBinaryOps.cpp:81: UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead.
Test set: Average loss: 0.0051, Accuracy: 7476/10000 (75%)
Train Epoch: 1 [0/60000 (0%)] Loss: 1.056841
Train Epoch: 1 [20000/60000 (33%)] Loss: 0.721334
Train Epoch: 1 [40000/60000 (67%)] Loss: 0.790637
Test set: Average loss: 0.0033, Accuracy: 8069/10000 (81%)
Train Epoch: 2 [0/60000 (0%)] Loss: 0.680886
Train Epoch: 2 [20000/60000 (33%)] Loss: 0.629937
Train Epoch: 2 [40000/60000 (67%)] Loss: 0.627497
Test set: Average loss: 0.0021, Accuracy: 8971/10000 (90%)
Train Epoch: 3 [0/60000 (0%)] Loss: 0.410005
Train Epoch: 3 [20000/60000 (33%)] Loss: 0.332373
Train Epoch: 3 [40000/60000 (67%)] Loss: 0.293972
Test set: Average loss: 0.0016, Accuracy: 9104/10000 (91%)
Train Epoch: 4 [0/60000 (0%)] Loss: 0.318976
Train Epoch: 4 [20000/60000 (33%)] Loss: 0.325024
Train Epoch: 4 [40000/60000 (67%)] Loss: 0.279787
Test set: Average loss: 0.0014, Accuracy: 9171/10000 (92%)
Train Epoch: 5 [0/60000 (0%)] Loss: 0.237663
Train Epoch: 5 [20000/60000 (33%)] Loss: 0.272126
Train Epoch: 5 [40000/60000 (67%)] Loss: 0.182882
Test set: Average loss: 0.0013, Accuracy: 9227/10000 (92%)
Train Epoch: 6 [0/60000 (0%)] Loss: 0.280532
Train Epoch: 6 [20000/60000 (33%)] Loss: 0.239808
Train Epoch: 6 [40000/60000 (67%)] Loss: 0.372246
Test set: Average loss: 0.0012, Accuracy: 9297/10000 (93%)
Train Epoch: 7 [0/60000 (0%)] Loss: 0.291511
Train Epoch: 7 [20000/60000 (33%)] Loss: 0.225020
Train Epoch: 7 [40000/60000 (67%)] Loss: 0.265182
Test set: Average loss: 0.0012, Accuracy: 9321/10000 (93%)
Train Epoch: 8 [0/60000 (0%)] Loss: 0.227891
Train Epoch: 8 [20000/60000 (33%)] Loss: 0.270453
Train Epoch: 8 [40000/60000 (67%)] Loss: 0.191862
Test set: Average loss: 0.0011, Accuracy: 9361/10000 (94%)
Train Epoch: 9 [0/60000 (0%)] Loss: 0.188959
Train Epoch: 9 [20000/60000 (33%)] Loss: 0.161353
Train Epoch: 9 [40000/60000 (67%)] Loss: 0.293424
Test set: Average loss: 0.0011, Accuracy: 9374/10000 (94%)
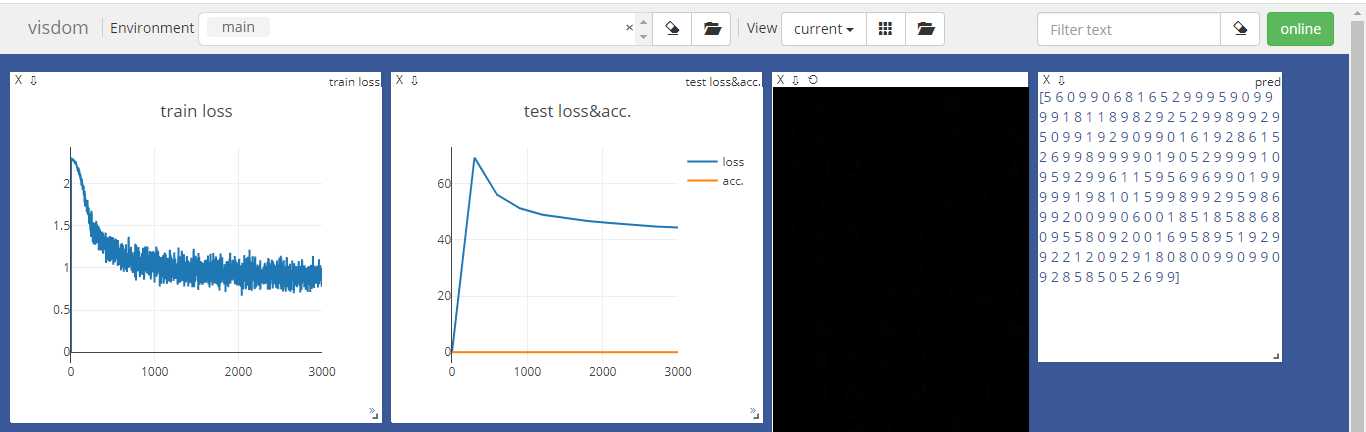
但是viz.images()那一句图片没有显示,没有找到原因,先放一放吧。
以上是关于Pytorch-Visdom可视化工具的主要内容,如果未能解决你的问题,请参考以下文章