sklearn实践:决策树
Posted fragrant-breeze
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sklearn实践:决策树相关的知识,希望对你有一定的参考价值。
sklearn实践(二):决策树
一、数据处理
继续上次聚类的练习,基于稍作处理的数据,在决策树中,只需划分一下训练集和测试集即可
这里用到的是 sklearn.model_selection.train_test_split()
函数原型:sklearn.model_selection.``train_test_split(**arrays*, **options)
函数实现的功能:Split arrays or matrices into random train and test subsets
Quick utility that wraps input validation and next(ShuffleSplit().split(X, y)) and application to input data into a single call for splitting (and optionally subsampling) data in a oneliner.
Parameter:***arrays* ** sequence of indexables with same length / shape[0]
Allowed inputs are lists, numpy arrays, scipy-sparse matrices or pandas dataframes.
可见train_test_split()的参数可以是list,numpy_array都可以。
官方案例:
>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> list(y)
[0, 1, 2, 3, 4]
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.33, random_state=42)
...
>>> X_train
array([[4, 5],
[0, 1],
[6, 7]])
>>> y_train
[2, 0, 3]
>>> X_test
array([[2, 3],
[8, 9]])
>>> y_test
[1, 4]
可见,我们还需要准备一个y
在这里投机取巧一下:
由于样本集中,前30个是患病,后30个不患病,由此:
y = [1 for i in range(30)] + [0 for j in range(30)]
这样就可以开始划分数据集了
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2)
test_size=0.2表示测试集占0.2。(虽然吴恩达推荐的是7:3,或者加上cross validation=0.2=test=(1-train)/2)
二、决策树可视化
接着是苦恼我很久的决策树可视化
clf = tree.DecisionTreeClassifier(criterion="entropy")# 载入决策树分类模型
clf = clf.fit(Xtrain, Ytrain)# 决策树拟合,得到模型
score = clf.score(Xtest, Ytest) #返回预测的准确度
print(score)
tree.plot_tree(clf)
feature_name = [‘FEA_a‘,‘FEA_b‘,‘FEA_c‘,‘FEA_d‘,‘FEA_e‘,‘FEA_f‘,‘FEA_g‘]
import graphviz
dot_data = tree.export_graphviz(clf,feature_names= feature_name,class_names=["healthy","unhealthy"],filled=True,rounded=True)
graph = graphviz.Source(dot_data)#画树
graph.render("C:\\Users\\Breeze\\Desktop\\matlab\\tree2.pdf")
graphviz是之前就安装好的,可能有路径需要配置,具体不记得了
主要是graph.render(),这个函数找了好久
没怎么看懂官方文档是怎么做的,碰巧让我试了出来
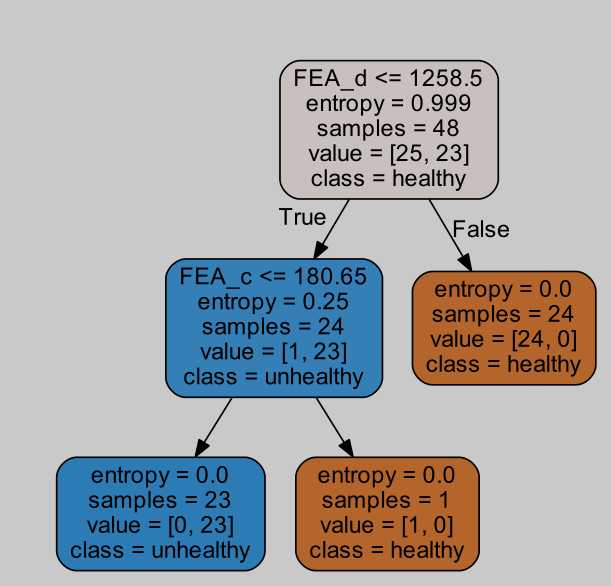
检验了一下,效果还是可以的,只是这图有点丑。
没想到这么多参数,实际上只有c,d是关键特征
三、总结
还是要多实践,理论上的知识在实践中可能只要一行代码,看上去是很简单的事,但是过程的数据处理,格式转换真的是很头疼的,有时候还会遇到版本的bug,多练习,多总结。
以上是关于sklearn实践:决策树的主要内容,如果未能解决你的问题,请参考以下文章