sklearn实践:kmeans聚类
Posted fragrant-breeze
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sklearn实践:kmeans聚类相关的知识,希望对你有一定的参考价值。
sklearn实践(一):kmeans聚类
实践往往比理论要经历更多的挫折。
一、数据处理
官方给的案例里用的都是sklearn自带的数据集,只要import之后便万事大吉,但实际中我们采用的数据往往没有那么规整,也不是可以一下就fit到模型里去的。经过这次经历,打算整理一下大致思路,关于更高级、深入的数据处理,这篇文章不会涉及。
官方案例如下:
>>> from sklearn.cluster import KMeans
>>> import numpy as np
>>> X = np.array([[1, 2], [1, 4], [1, 0],
... [10, 2], [10, 4], [10, 0]])
#其中,X即fit的参数可推断,应当是这种np.array
>>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
>>> kmeans.labels_
array([1, 1, 1, 0, 0, 0], dtype=int32)
#labels_表示样本集中所有样本所属类别(x=1->No.1;x=2->No.1;x=3->No.1;x=4->No.0)
>>> kmeans.predict([[0, 0], [12, 3]])
array([1, 0], dtype=int32)
#以二维数组格式[x,y]输入predict,可输出判断类别结果
>>> kmeans.cluster_centers_
array([[10., 2.],
[ 1., 2.]])
#cluster_center是两个cluster的中心点
我的数据:
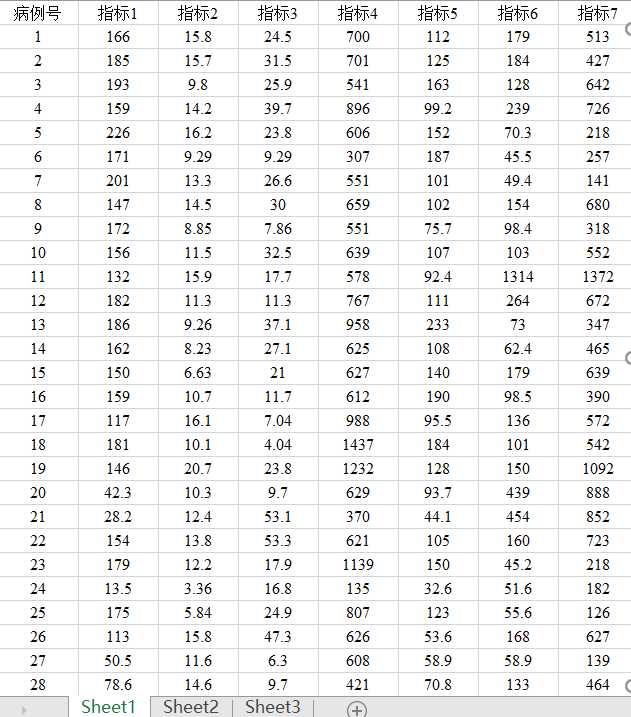
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 初始化数据集
dat = pd.read_csv("C:\\Users\\Breeze\\Desktop\\matlab\\data.csv")
# 指定簇的个数,即分成几类
print(data)
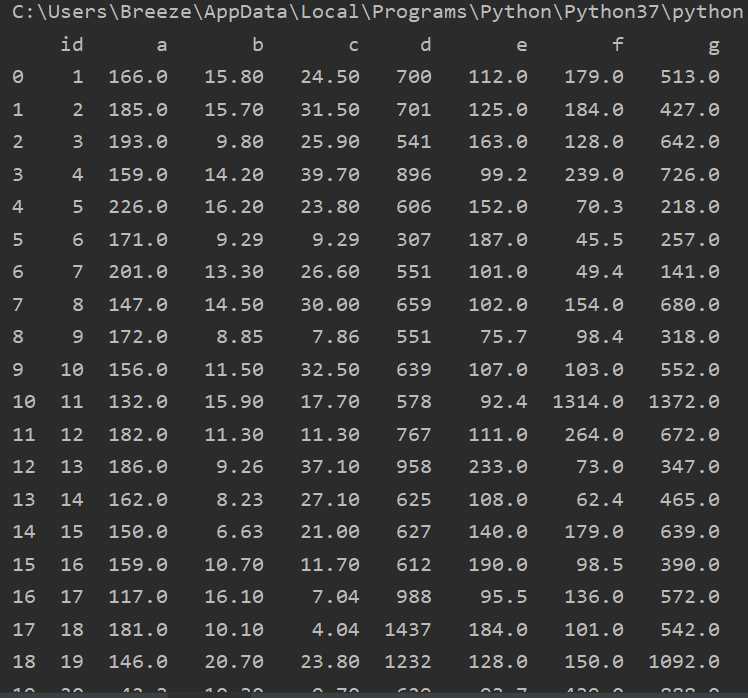
将dataframe转置
data = dat.T
print(data)
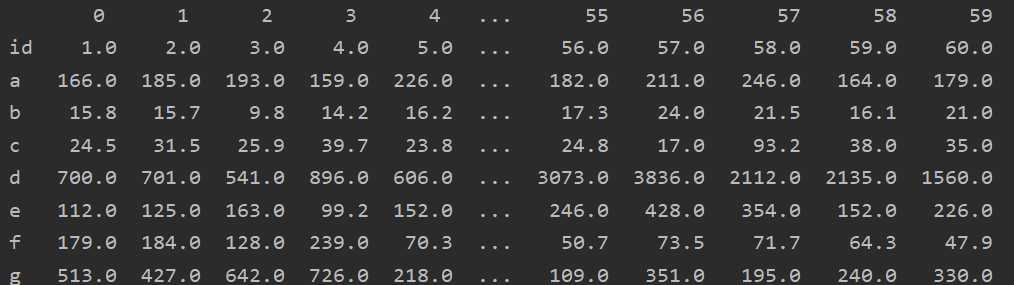
去掉id这一列:
data = data.drop([‘id‘])
将每一列依次读取出来,每一列都用列表形式存储,依次放到另一个空列表中:
x = []
for i in range(60):
x.append(data[i].values.tolist())
X = np.array(x)
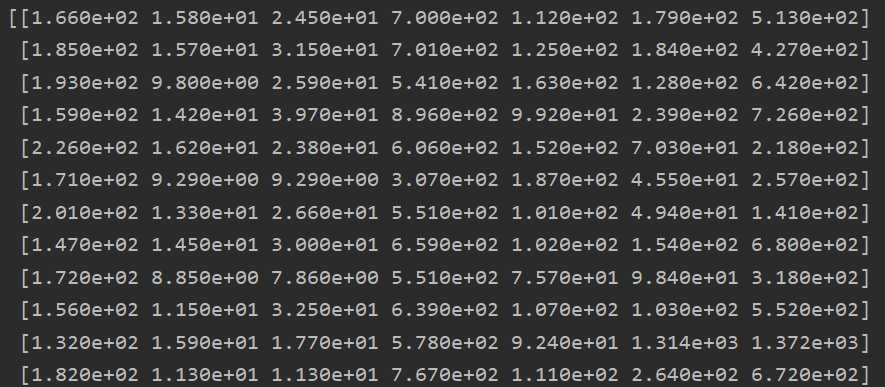
由此得到合适的数据集X
二、fit()开始聚类
fit(X):
km = KMeans(n_clusters=3).fit(X)
# 标签结果
rs_labels = km.labels_
# 每个类别的中心点
rs_center_ids = km.cluster_centers_
# 描绘各个点
plt.scatter(X[:, 0], X[:, 1], c=rs_labels, alpha=0.5)
# 描绘质心
# plt.scatter(rs_center_ids[:, 0], rs_center_ids[:, 1], c=‘red‘)
plt.show()
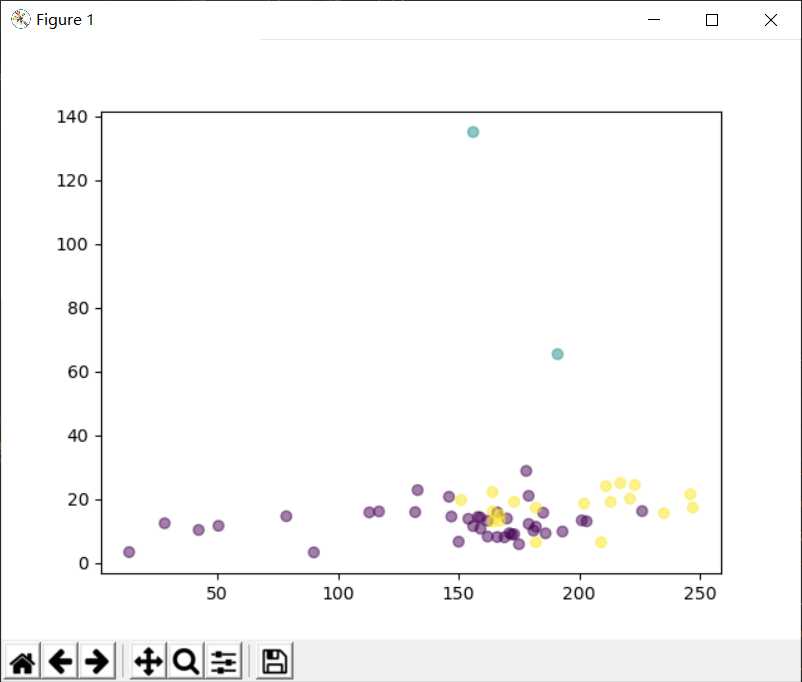
以上是关于sklearn实践:kmeans聚类的主要内容,如果未能解决你的问题,请参考以下文章