基于httpclient与jsoup的抓取当当图书页面数据简单Demo
Posted liyanglin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于httpclient与jsoup的抓取当当图书页面数据简单Demo相关的知识,希望对你有一定的参考价值。
一.httpclient
来自Apache,可以通过Java代码发起HTTP请求
下载:http://hc.apache.org/downloads.cgi
HttpClient是基于HttpCore的HTTP / 1.1兼容HTTP代理实现。它还为客户端身份验证,HTTP状态管理和HTTP连接管理提供了可重用的组件。

二.jsoup
html解析工具,可以解析本地资源与在线资源
官网地址: https://jsoup.org/
JAR下载: https://jsoup.org/download
Jsoup封装并实现了DOM里面常用的元素遍历方法:
- 根据id查找元素:
getElementById(String id) - 根据标签查找元素:
getElementsByTag(String tag) - 根据class查找元素:
getElementsByClass(String className) - 根据属性查找元素:
getElementsByAttribute(String key) - 兄弟遍历方法:
siblingElements(),firstElementSibling(),lastElementSibling();nextElementSibling(),previousElementSibling() - 层级之间遍历:
parent(),children(),child(int index)
这些方法会返回Element或者Elements节点对象,这些对象可以使用下面的方法获取一些属性:
attr(String key): 获取某个属性值attributes(): 获取节点的所有属性id(): 获取节点的idclassName(): 获取当前节点的class名称classNames(): 获取当前节点的所有class名称text(): 获取当前节点的textNode内容html(): 获取当前节点的 inner HTMLouterHtml(): 获取当前节点的 outer HTMLdata(): 获取当前节点的内容,用于script或者style标签等tag(): 获取标签tagName(): 获取当前节点的标签名称
三.DEMO
1.导入JAR
2.简单实现Demo
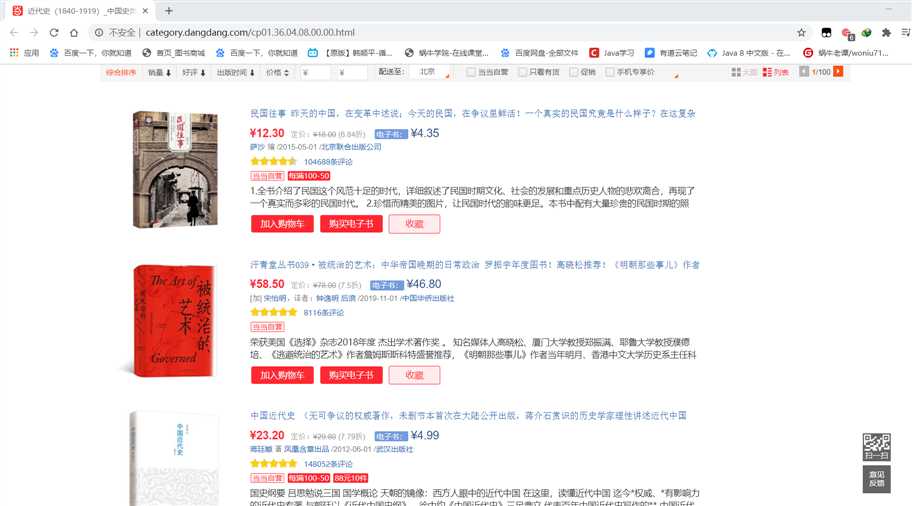

原理:通过HttpClient发起请求,经过处理后得到页面源码,通过Jsoup解析源码,获取其中的元素,从而获得其中的值
注意:得到源码后,在整个页面中需要什么信息要人为去找代码中的Class属性,Id属性,这里举例了几个简单的图书信息
public class Test { /** * *简单抓取当当图书分类中某一页指定信息输出到控制台并保存到文件中 */ public static void main(String[] args) throws IOException { CloseableHttpClient httpclient = HttpClients.createDefault(); //创建一个文件,用来保存信息 BufferedWriter writer=new BufferedWriter(new FileWriter("D:\\book.csv")); try { //发送请求URL填入当当网图书分类某一页面的地址 HttpGet httpget = new HttpGet("http://category.dangdang.com/cp01.36.04.08.00.00.html"); System.out.println("Executing request " + httpget.getRequestLine()); // Create a custom response handler ResponseHandler<String> responseHandler = response -> { int status = response.getStatusLine().getStatusCode(); if (status >= 200 && status < 300) { HttpEntity entity = response.getEntity(); return entity != null ? EntityUtils.toString(entity) : null; } else { throw new ClientProtocolException("Unexpected response status: " + status); } }; //得到请求体也就是页面源码responseBody String responseBody = httpclient.execute(httpget, responseHandler); System.out.println("----------------------------------------"); //使用Jsoup解析得到一个document对象,代表这个页面 Document document= Jsoup.parse(responseBody); //这是人为分析源码中的数据后,取docunment中需要的元素 Element pos=document.getElementsByClass("bigimg").get(0); Elements list=pos.children(); for(Element e:list){ Element name = e.getElementsByClass("pic").get(0); Element detail = e.getElementsByClass("detail").get(0); Element author= e.getElementsByAttributeValue("name","itemlist-author").get(0); Element press= e.getElementsByAttributeValue("name","P_cbs").get(0); Element market= e.getElementsByClass("search_pre_price").get(0); Element sale= e.getElementsByClass("search_now_price").get(0); System.out.println("图书名:"+name.attr("title")); System.out.println("简介:"+detail.text()); System.out.println("作者:"+author.text()); System.out.println("出版社:"+press.text()); System.out.println("市场价:"+market.text()); System.out.println("惊喜价:"+sale.text()); System.out.println("--------------------"); //添加要写入文件的信息 writer.write(name.attr("title")+","+detail.text()+","+author.text()+","+press.text()); writer.newLine(); } } finally { writer.close(); httpclient.close(); } } }
以上是关于基于httpclient与jsoup的抓取当当图书页面数据简单Demo的主要内容,如果未能解决你的问题,请参考以下文章