SAM -- Chap 8 提升方法 自我梳理
Posted ms-jin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SAM -- Chap 8 提升方法 自我梳理相关的知识,希望对你有一定的参考价值。
Chap 8 提升方法
Boosting
将多个弱的分类器合成为一个强分类器,且各分类器有关联
怎么得到各分类器呢,就是靠不断resample 和 reweighting你的training data 来形成一个新的数据:
(source:https://www.youtube.com/watch?v=tH9FH1DH5n0)

AdaBoost
-
Idea of AdaBoost: training f2(x) on the new training set that fails f1(x)
-
AdaBoost with trees is also referred to as the “best off-the-shelf classifier in the world”.
-
Kearns and Valiant: Strongly learnable 还是 weakly learnable. 在概率近似正确(probably approximately correct, PAC)学习的框架中,一个概念(一个类),如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么就称这个概念是强可学习的。一个概念,如果存在一个多项式的学习算法能够学习它,学习正确率仅比随机猜测略好,那么就称这个概念是弱可学习的。
-
那么对于一个学习问题,若是找到“弱学习算法”(毕竟比较粗糙的分类规则很容易找到),那么就可以将弱学习方法变成“强学习算法” (组合这些弱分类)。So 如何提升 就可以用这个很经典的adaboost了
-
大部分的提升方法中两大问题:1)如何在每一轮改变训练数据的概率分布(也就是针对不同分布调用弱分类进行学习);2)如何组合
-
Adaboost对应方案:1)首先学习初始化权值分布的训练数据 得到基本分类器并计算其在该轮的分类误差率及权值, 如果分类误差较小的 就降低ta们的权值,反之误差较大的权值就提高,更新权值分布,不断迭代,所谓分而治之 即误分类样本在下一轮学习中更起作用;2)加权多数表决,加大分类误差率小的弱分类器的权值 (基本分类器的线性组合构建最终分类器):
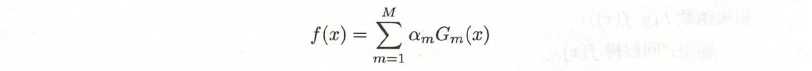
- 最基本性质是能在学习中不断减少训练误差(指数下降),有一个证明+推论,直接上推论:
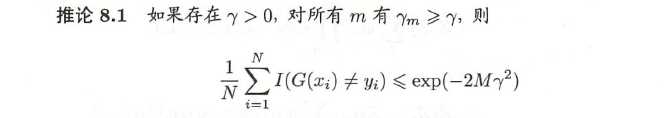
- 算法解释:模型为加法,损失函数指数,学习算法为前向分布算法时的二类分类学习方法。
前向分步法
首先是一个很general 的form:
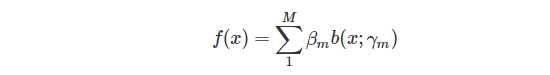
这里 b 是一个基函数(也就是第m个弱分类器),r是基函数的参数,β为基函数的系数,最终的结果是所有学习器的weighted sum:

基本算法:

前向分布和AdaBoost
简而言之 coefficient and weight update from AdaBoost can be derived from Forward Stagewise Boosting using exponential loss function.
Boosting tree
以分类树或回归树为基本分类器的提升方法,采用前向分布+加法模型

梯度提升
当然损失函数有时就很难求,所以有Freidman提出的 gradient boosting,即利用最速下降法的近似

Gradient boosting
Gradient Boosting method tries to fit the new predictor to the residual errors made by the previous predictor.
XGboost
focused on computational speed and model performance
以上是关于SAM -- Chap 8 提升方法 自我梳理的主要内容,如果未能解决你的问题,请参考以下文章