bert 编程入门--pytorch版本
Posted tfknight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了bert 编程入门--pytorch版本相关的知识,希望对你有一定的参考价值。
代码在最后面
前面是代码细节的内容讲解
## 前綴的 tokens 即為 wordpieces
以詞彙 fragment 來說,其可以被拆成 frag 與 ##ment 兩個 pieces,而一個 word 也可以獨自形成一個 wordpiece。wordpieces 可以由蒐集大量文本並找出其中常見的 pattern 取得。
除了一般的 wordpieces 以外,BERT 裡頭有 5 個特殊 tokens 各司其職:
[CLS]:在做分類任務時其最後一層的 repr. 會被視為整個輸入序列的 repr.[SEP]:有兩個句子的文本會被串接成一個輸入序列,並在兩句之間插入這個 token 以做區隔[UNK]:沒出現在 BERT 字典裡頭的字會被這個 token 取代[PAD]:zero padding 遮罩,將長度不一的輸入序列補齊方便做 batch 運算[MASK]:未知遮罩,僅在預訓練階段會用到
這樣的 word repr. 就是近年十分盛行的 contextual word representation 概念。跟以往沒有蘊含上下文資訊的 Word2Vec、GloVe 等無語境的詞嵌入向量有很大的差異。用稍微學術一點的說法就是:
Contextual word repr. 讓同 word type 的 word token 在不同語境下有不同的表示方式;而傳統的詞向量無論上下文,都會讓同 type 的 word token 的 repr. 相同。
直覺上 contextual word representation 比較能反映人類語言的真實情況,
fine tune BERT 來解決新的下游任務有 5 個簡單步驟:
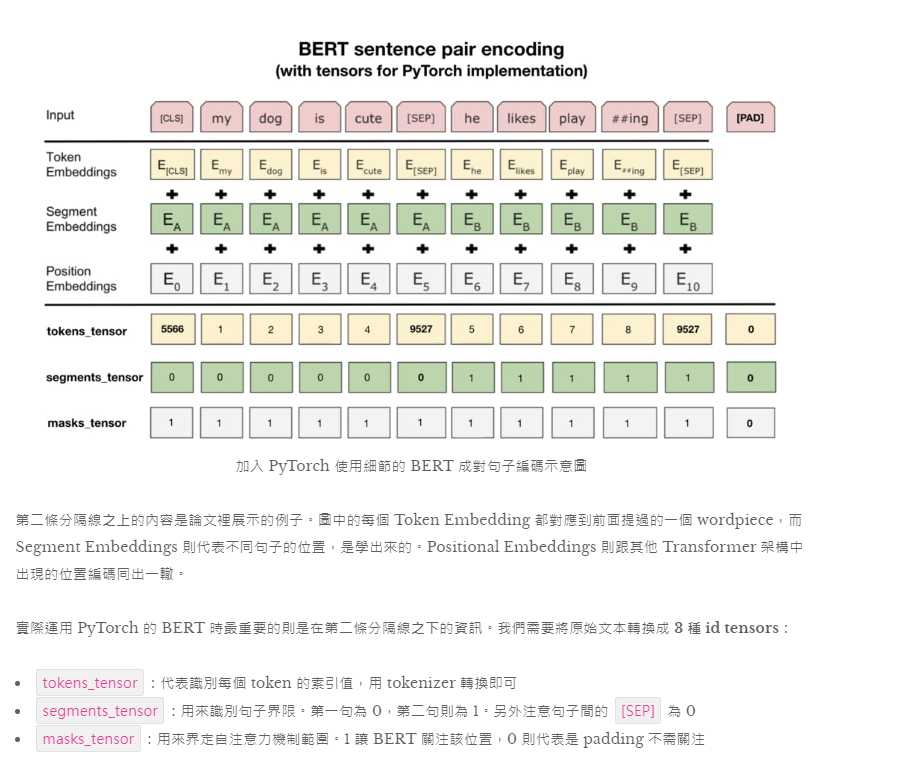
為了讓 GPU 平行運算我們需要將 batch 裡的每個輸入序列都補上 zero padding 以保證它們長度一致
以上是关于bert 编程入门--pytorch版本的主要内容,如果未能解决你的问题,请参考以下文章
一个很赞NLP入门代码练习库(含Pytorch和Tensorflow版本)
pytorch-pretrained-BERT:BERT PyTorch实现,可加载Google BERT预训练模型