mapreduce参数记录
Posted zyanrong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mapreduce参数记录相关的知识,希望对你有一定的参考价值。
mapred-default.xml:
| 版本 | 参数位置 | 参数名 | 默认值 | 说明 |
| cdh5.0.1 | mapred-default.xml | mapred.reduce.tasks(mapreduce.job.reduces) | 1 | 默认启动的reduce数。通过该参数可以手动修改reduce的个数 |
| mapreduce.task.io.sort.factor | 10 | Reduce Task中合并小文件时,一次合并的文件数据,每次合并的时候选择最小的前10进行合并 | ||
| mapreduce.task.io.sort.mb | 100 | Map Task缓冲区所占内存大小 | ||
| mapred.child.java.opts | -Xmx200m | jvm启动的子线程可以使用的最大内存。建议值-XX:-UseGCOverheadLimit -Xms512m -Xmx2048m -verbose:gc -Xloggc:/tmp/@taskid@.gc | ||
| mapreduce.jobtracker.handler.count | 10 | JobTracker可以启动的线程数,一般为tasktracker节点的4% | ||
| mapreduce.reduce.shuffle.parallelcopies | 5 | reuduce shuffle阶段并行传输数据的数量。这里改为10。集群大可以增大 | ||
| mapreduce.tasktracker.http.threads | 40 | map和reduce是通过http进行数据传输的,这个是设置传输的并行线程数 | ||
| mapreduce.map.output.compress | FALSE | map输出是否进行压缩,如果压缩就会多耗cpu,但是减少传输时间,如果不压缩,就需要较多的传输带宽。配合 mapreduce.map.output.compress.codec使用,默认是 org.apache.hadoop.io.compress.DefaultCodec,可以根据需要设定数据压缩方式 | ||
| mapreduce.reduce.shuffle.merge.percent | 0.66 | reduce归并接收map的输出数据可占用的内存配置百分比。类似mapreduce.reduce.shuffle.input.buffer.percen属性 | ||
| mapreduce.reduce.shuffle.memory.limit.percent | 0.25 | 一个单一的shuffle的最大内存使用限制 | ||
| mapreduce.jobtracker.handler.count | 10 | 并发处理来自tasktracker的RPC请求数,默认值10 | ||
| mapred.job.reuse.jvm.num.tasks(mapreduce.job.jvm.numtasks) | 1 | 一个jvm可连续启动多个同类型任务,默认值1,若为-1表示不受限制 | ||
| mapreduce.tasktracker.tasks.reduce.maximum | 2 | 一个tasktracker并发执行的reduce数,建议为cpu核数 |
yarn-site.xml:
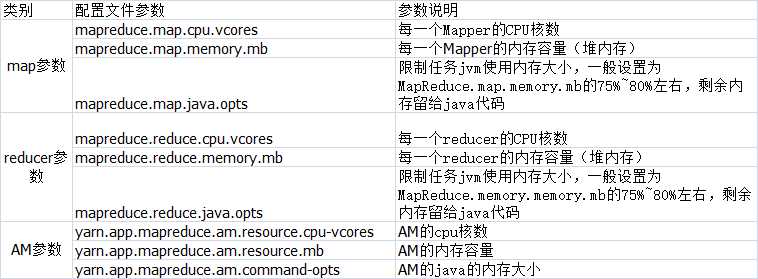

以上是关于mapreduce参数记录的主要内容,如果未能解决你的问题,请参考以下文章