Spark小实例(统计出日志中出现排行前10的IP地址)IDEA实现
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark小实例(统计出日志中出现排行前10的IP地址)IDEA实现相关的知识,希望对你有一定的参考价值。
首先创建好项目工程,如下图:
完善pom.xml文件,具体为:(依据自己的spark版本做修改)
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>准备数据:log.txt ,文本内容部分截图如下:(数据来源于网络,如有侵权,联系我删除)
文件下载地址:https://pan.baidu.com/s/1NE4pqqgJ-VvLZEW-6pQhxw 提取码:hq70
在src---mian---scala---cn.itcast下创建类:
代码具体为:
package cn.itcast
import org.apache.commons.lang3.StringUtils
import org.apache.spark.{SparkConf, SparkContext}
object LogCountSort {
def main(args: Array[String]): Unit = {
//1、生成
val conf = new SparkConf().setMaster("local[*]").setAppName("log-count")
val sc = new SparkContext(conf)
//2、读取
val data = sc.textFile("data/log.txt")
//3、取出IP, 赋予出现次数为1
val IPword = data.map(x => (x.split(" ")(0),1))
//4、清洗数据
val clearIP = IPword.filter(item => StringUtils.isNotEmpty(item._1))
//5、统计
val result = clearIP.reduceByKey(_+_)
//6、排序
val sort = result.sortBy(_._2,ascending = false)
//7. 取出结果, 打印结果
sort.take(10).foreach(println)
}
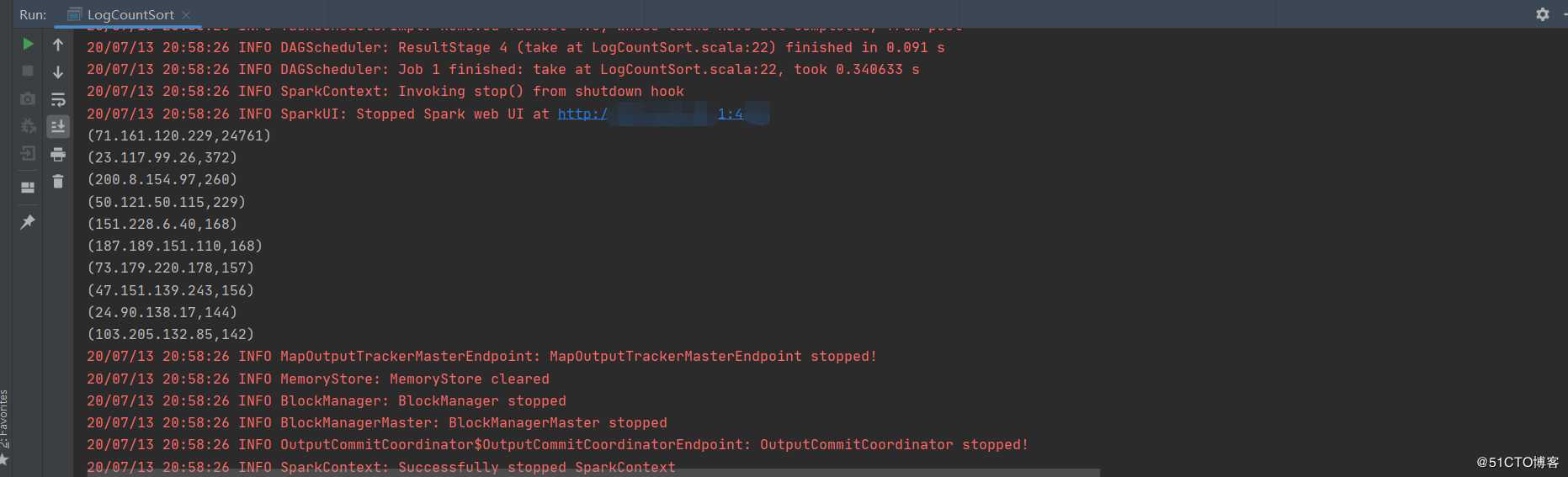
}运行主程序得出结果:
以上是关于Spark小实例(统计出日志中出现排行前10的IP地址)IDEA实现的主要内容,如果未能解决你的问题,请参考以下文章