drf序列化组件
Posted h1227
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了drf序列化组件相关的知识,希望对你有一定的参考价值。
1 序列化组件介绍
1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串
2. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型
3. 反序列化,完成数据校验功能
2 简单使用
1 写一个序列化的类,继承Serializer
2 在类中写要序列化的字段,想序列化哪个字段,就在类中写哪个字段
3 在视图类中使用,导入--》实例化得到序列化类的对象,把要序列化的对象传入
4 序列化类的对象.data 是一个字典
5 把字典返回,如果不使用rest_framework提供的Response,就得使用JsonResponse
#model.py
class Book(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5,decimal_places=2)
author = models.CharField(max_length=32)
publish = models.CharField(max_length=32)
# ser.py
class BookSerializer(serializers.Serializer):
# id=serializers.CharField()
name=serializers.CharField()
# price=serializers.DecimalField()
price=serializers.CharField()
author=serializers.CharField()
publish=serializers.CharField()
# views.py
class BookView(APIView):
def get(self,request,pk):
book=Book.objects.filter(id=pk).first()
#用一个类,毫无疑问,一定要实例化
#要序列化谁,就把谁传过来
book_ser=BookSerializer(book) # 调用类的__init__
# book_ser.data 序列化对象.data就是序列化后的字典
return Response(book_ser.data)
# urls.py
re_path(‘books/(?P<pk>d+)‘, views.BookView.as_view()),
注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在。
3 序列化类的字段类型
常用字段类型:
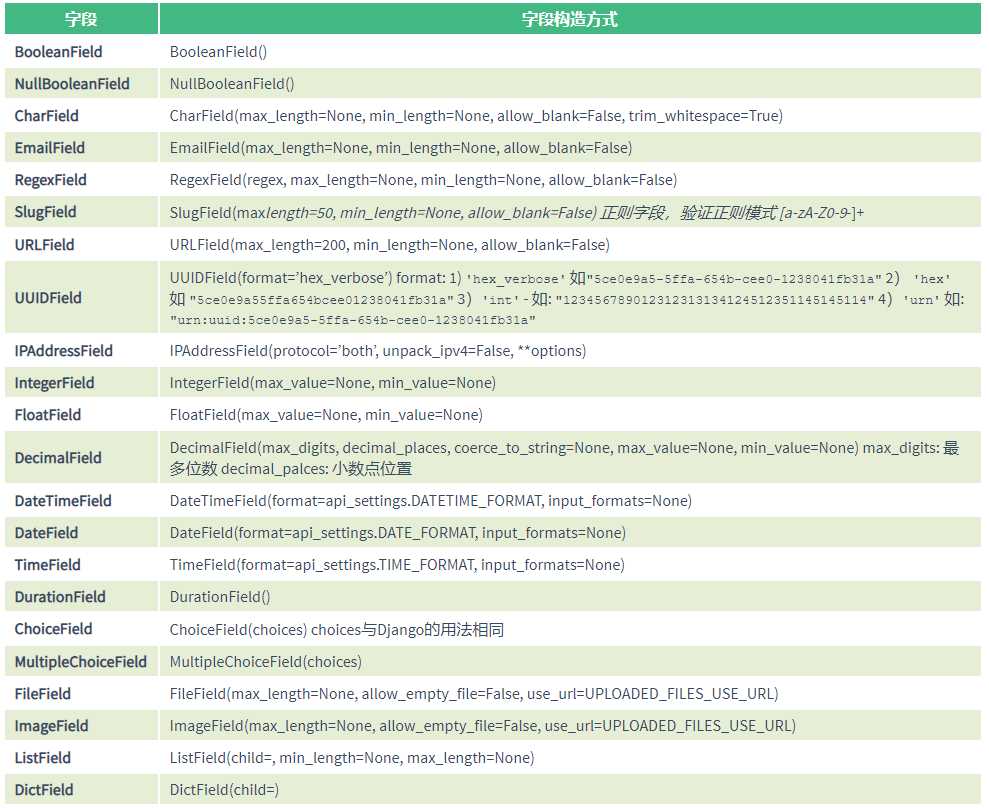
4 序列化字段选项
选项参数:
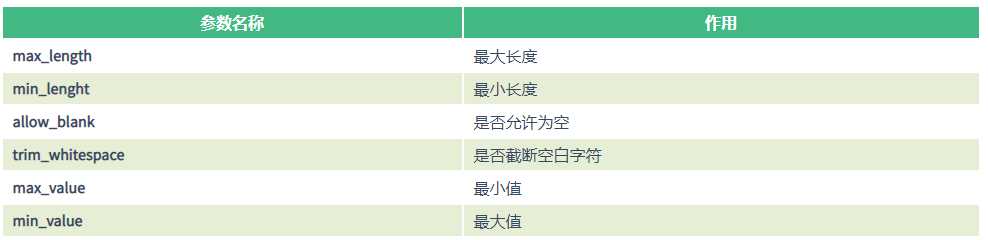
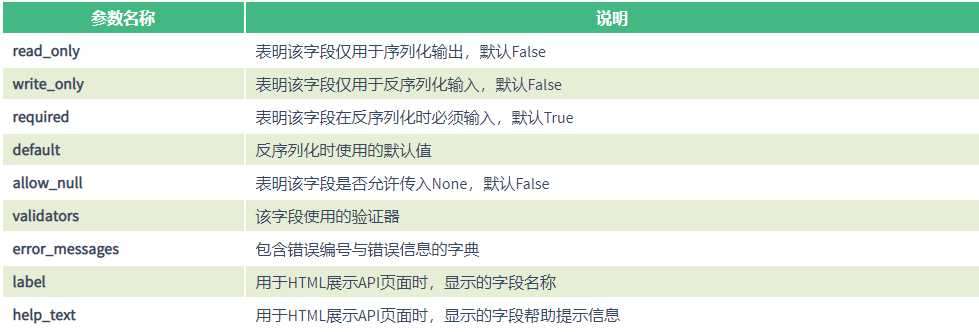
通用参数:
5 序列化组件修改数据
1 写一个序列化的类,继承Serializer
2 在类中写要反序列化的字段,想反序列化哪个字段,就在类中写哪个字段,字段的属性(max_lenth......)
max_length 最大长度
min_lenght 最小长度
allow_blank 是否允许为空
trim_whitespace 是否截断空白字符
max_value 最小值
min_value 最大值
3 在视图类中使用,导入--》实例化得到序列化类的对象,把要要修改的对象传入,修改的数据传入
boo_ser=BookSerializer(book,request.data)
boo_ser=BookSerializer(instance=book,data=request.data)
4 数据校验 if boo_ser.is_valid()
5 如果校验通过,就保存
boo_ser.save() # 注意不是book.save()
6 如果不通过,逻辑自己写
7 如果字段的校验规则不够,可以写钩子函数(局部和全局)
# 局部钩子
def validate_price(self, data): # validate_字段名 接收一个参数
#如果价格小于10,就校验不通过
# print(type(data))
# print(data)
if float(data)>10:
return data
else:
#校验失败,抛异常
raise ValidationError(‘价格太低‘)
# 全局钩子
def validate(self, validate_data): # 全局钩子
print(validate_data)
author=validate_data.get(‘author‘)
publish=validate_data.get(‘publish‘)
if author == publish:
raise ValidationError(‘作者名字跟出版社一样‘)
else:
return validate_data
8 可以使用字段的author=serializers.CharField(validators=[check_author]) ,来校验
-写一个函数
def check_author(data):
if data.startswith(‘sb‘):
raise ValidationError(‘作者名字不能以sb开头‘)
else:
return data
-配置:validators=[check_author]
# models.py
class Book(models.Model):
id=models.AutoField(primary_key=True)
name=models.CharField(max_length=32)
price=models.DecimalField(max_digits=5,decimal_places=2)
author=models.CharField(max_length=32)
publish=models.CharField(max_length=32)
# ser.py
# from rest_framework.serializers import Serializer # 就是一个类
from rest_framework import serializers
from rest_framework.exceptions import ValidationError
# 需要继承 Serializer
def check_author(data):
if data.startswith(‘sb‘):
raise ValidationError(‘作者名字不能以sb开头‘)
else:
return data
class BookSerializer(serializers.Serializer):
# id=serializers.CharField()
name=serializers.CharField(max_length=16,min_length=4)
# price=serializers.DecimalField()
price=serializers.CharField()
author=serializers.CharField(validators=[check_author]) # validators=[] 列表中写函数内存地址
publish=serializers.CharField()
def validate_price(self, data): # validate_字段名 接收一个参数
#如果价格小于10,就校验不通过
# print(type(data))
# print(data)
if float(data)>10:
return data
else:
#校验失败,抛异常
raise ValidationError(‘价格太低‘)
def validate(self, validate_data): # 全局钩子
print(validate_data)
author=validate_data.get(‘author‘)
publish=validate_data.get(‘publish‘)
if author == publish:
raise ValidationError(‘作者名字跟出版社一样‘)
else:
return validate_data
def update(self, instance, validated_data):
#instance是book这个对象
#validated_data是校验后的数据
instance.name=validated_data.get(‘name‘)
instance.price=validated_data.get(‘price‘)
instance.author=validated_data.get(‘author‘)
instance.publish=validated_data.get(‘publish‘)
instance.save() #book.save() django 的orm提供的
return instance
#views.py
class BookView(APIView):
def get(self,request,pk):
book=Book.objects.filter(id=pk).first()
#用一个类,毫无疑问,一定要实例化
#要序列化谁,就把谁传过来
book_ser=BookSerializer(book) # 调用类的__init__
# book_ser.data 序列化对象.data就是序列化后的字典
return Response(book_ser.data)
# return JsonResponse(book_ser.data)
def put(self,request,pk):
response_msg={‘status‘:100,‘msg‘:‘成功‘}
# 找到这个对象
book = Book.objects.filter(id=pk).first()
# 得到一个序列化类的对象
# boo_ser=BookSerializer(book,request.data)
boo_ser=BookSerializer(instance=book,data=request.data)
# 要数据验证(回想form表单的验证)
if boo_ser.is_valid(): # 返回True表示验证通过
boo_ser.save() # 报错
response_msg[‘data‘]=boo_ser.data
else:
response_msg[‘status‘]=101
response_msg[‘msg‘]=‘数据校验失败‘
response_msg[‘data‘]=boo_ser.errors
return Response(response_msg)
# urls.py
re_path(‘books/(?P<pk>d+)‘, views.BookView.as_view()),
6 read_only和write_only
read_only 表明该字段仅用于序列化输出,默认False,如果设置成True,postman中可以看到该字段,修改时,不需要传该字段
write_only 表明该字段仅用于反序列化输入,默认False,如果设置成True,postman中看不到该字段,修改时,该字段需要传
# 以下的了解
required 表明该字段在反序列化时必须输入,默认True
default 反序列化时使用的默认值
allow_null 表明该字段是否允许传入None,默认False
validators 该字段使用的验证器
error_messages 包含错误编号与错误信息的字典
7 查询所有
# views.py
class BooksView(APIView):
def get(self,request):
response_msg = {‘status‘: 100, ‘msg‘: ‘成功‘}
books=Book.objects.all()
book_ser=BookSerializer(books,many=True) #序列化多条,如果序列化一条,不需要写
response_msg[‘data‘]=book_ser.data
return Response(response_msg)
#urls.py
path(‘books/‘, views.BooksView.as_view()),
8 新增数据
# views.py
class BooksView(APIView):
# 新增
def post(self,request):
response_msg = {‘status‘: 100, ‘msg‘: ‘成功‘}
#修改才有instance,新增没有instance,只有data
book_ser = BookSerializer(data=request.data)
# book_ser = BookSerializer(request.data) # 这个按位置传request.data会给instance,就报错了
# 校验字段
if book_ser.is_valid():
book_ser.save()
response_msg[‘data‘]=book_ser.data
else:
response_msg[‘status‘]=102
response_msg[‘msg‘]=‘数据校验失败‘
response_msg[‘data‘]=book_ser.errors
return Response(response_msg)
#ser.py 序列化类重写create方法
def create(self, validated_data):
instance=Book.objects.create(**validated_data)
return instance
# urls.py
path(‘books/‘, views.BooksView.as_view()),
9 删除一个数据
# views.py
class BookView(APIView):
def delete(self,request,pk):
ret=Book.objects.filter(pk=pk).delete()
return Response({‘status‘:100,‘msg‘:‘删除成功‘})
# urls.py
re_path(‘books/(?P<pk>d+)‘, views.BookView.as_view()),
10 模型类序列化器
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
model=Book # 对应上models.py中的模型
fields=‘__all__‘
# fields=(‘name‘,‘price‘,‘id‘,‘author‘) # 只序列化指定的字段
# exclude=(‘name‘,) #跟fields不能都写,写谁,就表示排除谁
# read_only_fields=(‘price‘,)
# write_only_fields=(‘id‘,) #弃用了,使用extra_kwargs
extra_kwargs = { # 类似于这种形式name=serializers.CharField(max_length=16,min_length=4)
‘price‘: {‘write_only‘: True},
}
# 其他使用一模一样
#不需要重写create和updata方法了
11 源码分析
# 序列化多条,需要传many=True
#
book_ser=BookModelSerializer(books,many=True)
book_one_ser=BookModelSerializer(book)
print(type(book_ser))
#<class ‘rest_framework.serializers.ListSerializer‘>
print(type(book_one_ser))
#<class ‘app01.ser.BookModelSerializer‘>
# 对象的生成--》先调用类的__new__方法,生成空对象
# 对象=类名(name=lqz),触发类的__init__()
# 类的__new__方法控制对象的生成
def __new__(cls, *args, **kwargs):
if kwargs.pop(‘many‘, False):
return cls.many_init(*args, **kwargs)
# 没有传many=True,走下面,正常的对象实例化
return super().__new__(cls, *args, **kwargs)
12 Serializer高级用法
# source的使用
1 可以改字段名字 xxx=serializers.CharField(source=‘title‘)
2 可以.跨表publish=serializers.CharField(source=‘publish.email‘)
3 可以执行方法pub_date=serializers.CharField(source=‘test‘) test是Book表模型中的方法
# SerializerMethodField()的使用
1 它需要有个配套方法,方法名叫get_字段名,返回值就是要显示的东西
authors=serializers.SerializerMethodField() #它需要有个配套方法,方法名叫get_字段名,返回值就是要显示的东西
def get_authors(self,instance):
# book对象
authors=instance.authors.all() # 取出所有作者
ll=[]
for author in authors:
ll.append({‘name‘:author.name,‘age‘:author.age})
return ll
补充
自己封装Respons对象
class MyResponse():
def __init__(self):
self.status=100
self.msg=‘成功‘
@property
def get_dict(self):
return self.__dict__
if __name__ == ‘__main__‘:
res=MyResponse()
res.status=101
res.msg=‘查询失败‘
# res.data={‘name‘:‘lqz‘}
print(res.get_dict)
以上是关于drf序列化组件的主要内容,如果未能解决你的问题,请参考以下文章