kafka的认识安装与配置
Posted keatscoder
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka的认识安装与配置相关的知识,希望对你有一定的参考价值。
认识Kafka
花费越少的精力在数据移动上,就能越专注于核心业务 --- 《Kafka:The Definitive Guide》
认识 Kafka 之前,先了解一下发布与订阅消息系统:消息的发送者不会直接把消息发送给接收者、发送者以某种方式对消息进行分类,接收者订阅它们,以便能接受特定类型的消息。发布与订阅系统一般会有一个 broker(n. 经纪人、中间商) 也就是发布消息的中心点。
Kafka 是一款基于发布与订阅的消息系统,一般被称为“分布式提交日志”或者“分布式流平台”。 Kafka 的数据单元被称作消息,可以看作是数据库中的一行数据,消息是由字节数组组成,故对 kafka 来说消息没有特别的意义,消息可以有一个可选的元数据,也就是键。键也是一个字节数组,同样对于 kafka 没有什么特殊意义。键可以用来将消息以一种可控的方式写入分区。最简单的例子就是为键生成一个一致性散列值,然后使用散列值对主题分区数进行取模,为消息选择分区。这样可以保证具有相同键的消息总是被写在相同的分区上。保证消息在一个主题中顺序读取。
为了提高效率,消息将被分批次写入 Kafka 。批次就是一组消息,类似于 redis 中的流水线(Pipelined)操作。
主题和分区
kafka 的消息通过主题进行分类,主题就相当于数据库中的表,主题可以被分成若干个分区,一个分区就是一个提交日志,消息以追加的形式被写入分区。然后按照先入先出的顺序读取。一个主题下的分区也可以在不同的服务器上,以此提供比单个服务器更加强大的性能
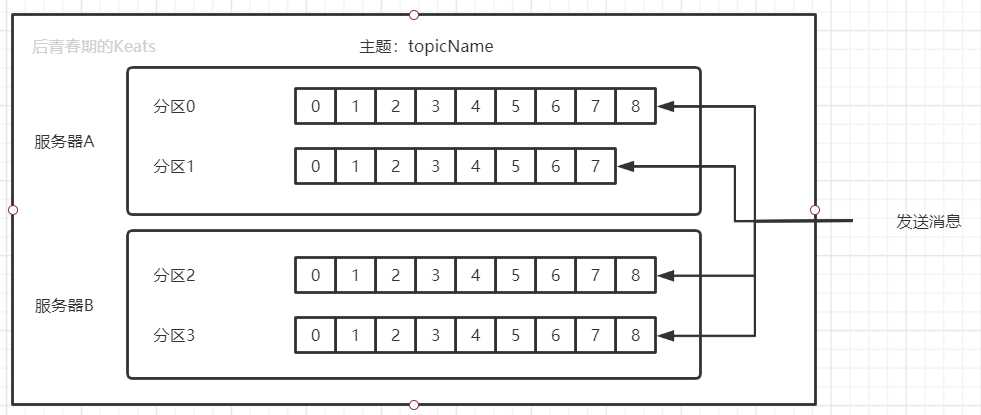
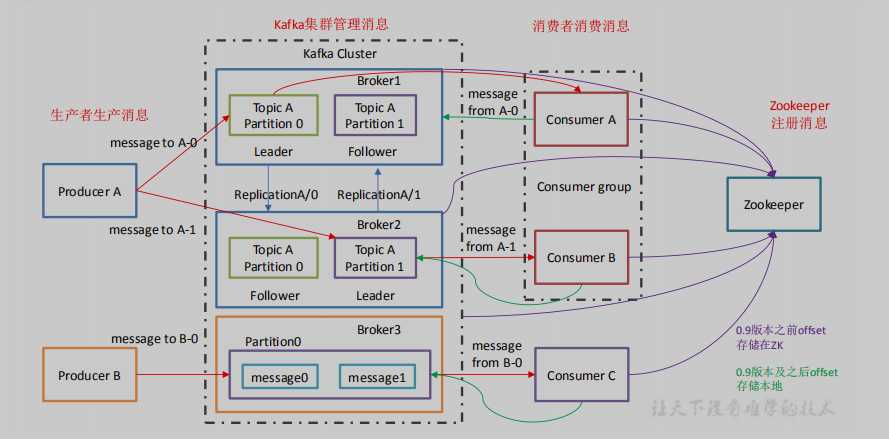
生产者和消费者
Kafka 的客户端就是 Kafka 系统的用户,一般情况下有两种基本类型:生产者和消费者
Producer 生产者创建消息,一般情况下,一个消息会被发布到一个特定的主题上。生产者在默认情况下将消息均分在主题的每个分区上
Consumer 消费者读取消息,消费者订阅一个或多个主题,并按照消息的生成顺序读取他们,消费者通过检查消息的偏移量来区分已经读过的消息。这个偏移量会被消费者在 zk 或者 kafka 上保存,如果消费者关闭或者重启,他的读取状态不会消失
消费者是消费者群组 Consumer group的一部分,群组可以保证每个分区被一个消费者消费(因此消费者数量不能大于分区数量,会造成消费者服务器的浪费),如果一个消费者失效,群组里的其他消费者可以接管失效消费者的工作。
Kafka的优点
- 无缝支持多个生产者
- 支持多个消费者从一条消息流读取数据、且各个消费者之间的偏移量不影响。也支持多个消费者共享一个消息流,并保证整个消费者群组对每个消息只消费一次
- 可以对每个主题设置保留规则,根据保留规则持久化数据到磁盘
- 高性能,高伸缩性
安装
Kafka 使用 Zookeeper(后面简称zk) 保存集群的元数据信息和消费者信息, Kafka 发行版本自带 zk,可以直接从脚本启动,不过安装一个完整版的 zk 也不难
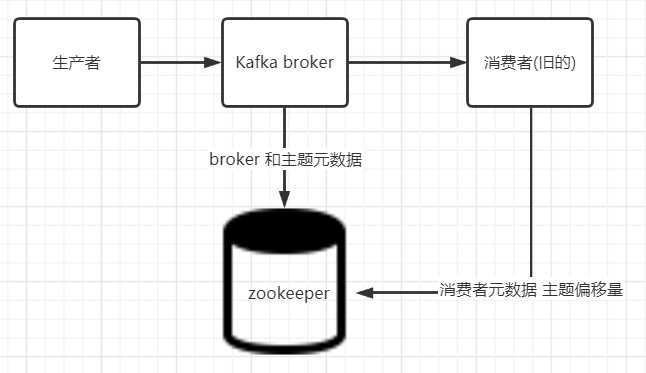
安装单节点 zk
官方下载地址:http://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/
如果下载速度不如意,可以使用我的蓝奏云:https://keats.lanzous.com/iMWi8dpi04f 提取码: keats
安装目录: /usr/local/zookeeper
数据目录: /var/lib/zookeeper
# tar -zxf zookeeper-3.4.6.tar.gz
# mv zookeeper-3.4.6 /usr/local/zookeeper
# mkdir -p /var/lib/zookeeper
# cat > /usr/local/zookeeper/conf/zoo.cfg << EOF
> tickTime=2000
> dataDir=/var/lib/zookeeper
> clientPort=2181
> EOF
# 接着设置一下环境变量中的 JAVA_HOME,可以先使用 export 命令查看是否已经设置
# export JAVA_HOME=/xxx
# 最后切换到 zk 安装目录,启动 zk
# /usr/local/zookeeper/bin/zkServer.sh start
接着通过四字命令 srvr 验证 zk 是否安装正确
# telnet localhost 2181
Trying ::1...
Connected to localhost.
Escape character is ‘^]‘.
srvr
Zookeeper version: 3.4.6-1569965, built on 02/20/2014 09:09 GMT
Latency min/avg/max: 0/0/0
Received: 1
Sent: 0
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: standalone
Node count: 4
Connection closed by foreign host.
[root@linux-keats bin]# pwd
/usr/local/zookeeper/bin
安装单节点 Kafka
下载: https://archive.apache.org/dist/kafka/0.9.0.1/kafka_2.11-0.9.0.1.tgz
蓝奏云:下载后将后缀名 zip 改为 tgz:https://keats.lanzous.com/iaZ9hdpj5bi
# tar -zxf kafka_2.11-0.9.0.1.tgz
# mv kafka_2.11-0.9.0.1 /usr/local/kafka
# mkdir /tmp/kafka-logs
# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
其中 -dadmon 表示 kafka 以守护线程的形式启动
配置 kafka
#broker 的全局唯一编号,集群中不能重复。int类型
broker.id=0
#是否允许删除 topic
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#处理磁盘 IO 的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志(此日志非常规意义的日志)存放的路径。用上一步创建的目录。
log.dirs=/tmp/kafka-logs
#topic 创建时默认的分区数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接 Zookeeper 地址。如果是 zk 集群,使用 , 隔开
zookeeper.connect=localhost:2181
集群
zk 集群的安装请度娘 zk 集群,kafka 可以按照末尾参考文献安装集群。我这里测试服务器性能不行还跑了几个 java 程序,就不装集群了
测试
主题相关操作
/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Created topic "test".
- --create 创建操作 还有 --list 查询,--describe 详情
- --zookeeper localhost:2181 配置 zk 的信息
- --partitions 1 分区数目 1
- --replication-factor 1 副本数 1。副本数不能大于 kafka broker 节点的数目
- --topic test 指定主题名称
创建好主题后,logs 文件夹内就会出现 主题名-分区名 的提交日志

往主题发送消息
# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Test Message 1
Test Message 2
^D
从测试主题读取消息
# /usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
Test Message 1
Test Message 2
^C
Processed a total of 2 messages
参考
《kafka权威指南》 --- 美国人著
以上是关于kafka的认识安装与配置的主要内容,如果未能解决你的问题,请参考以下文章