假设检验
Posted cgmcoding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了假设检验相关的知识,希望对你有一定的参考价值。
假设检验问题时统计推断中的一类重要问题,在总体的分布函数完全未知或只知其形式,不知其参数的情况,为了推断总体的某些未知特性,提出某些关于总体的假设,这类问题被称为假设检验
一个假设检验问题可以分为5步,无论细节如果变化,都一定会遵循这4个步骤
1.陈述研究假设,包含原假设(null hypothesis)和备择假设(alternate hypothesis):
通常来说,我们会把原假设的描述写成变量之间不存在某种差异,
或不存在某种关联,原假设是被保护的假设, 如果没有确凿的证据不能推翻。备择假设则为存在某种差异或关联。
例如,原假设:男人和女人的平均身高没有差别, 备择假设男人和女人的平均身高存在显著差别。
2.为验证假设收集数据:
为了统计检验的结果真实可靠,需要根据实际的假设命题从总体中抽取样本,要求抽样的数据要具有代表性,
例如在上述男女平均身高的命题中,抽取的样本要能覆盖到各类社会阶级,各个国家等所有可能影响到身高的因素。
3.构造合适的统计测试量并测试:
统计检验量有很多种类,但是所有的统计检验都是基于组内方差和组间方差的比较,如果组间方差足够大,
使得不同组之间几乎没有重叠,那么统计量会反映出一个非常小的P值,意味着不同组之间的差异不可能是由偶然性导致的。
4.决定是接受还是拒绝原假设:
基于统计量的结果做出接受或拒绝原假设的判断,通常我们会以P=0.05作为临界值(单侧检验)。
统计检验
最常用的统计检验包括回归检验(regression test),比较检验(comparison test)和关联检验(correlation test)三类
回归检验:适用于预测变量是数值型的情况:
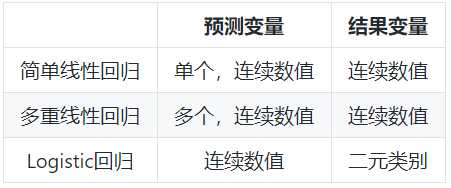
比较检验:适用于预测变量是类别型,结果变量是数值型的情况
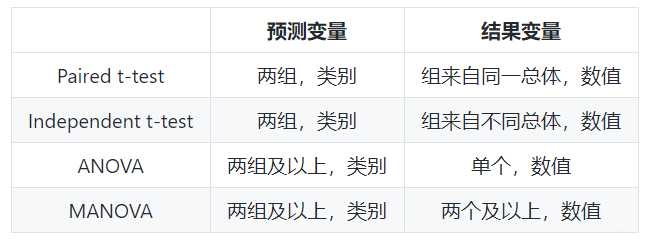
关联检验:常用的只有卡方检验一种,适用于预测变量和结果变量均为类别型的情况
1.t检验
检验两个独立样本集的均值是否具有显著差异
H0;均值相等
H1:均值不相等
from scipy.stats import ttest_ind import numpy as np data1 = np.random.normal(size=10) #data2 = np.random.normal(size=10) data2 = np.random.poisson(size=10) stat, p = ttest_ind(data1, data2) print(‘stat=%.3f, p=%.3f‘ % (stat, p)) if p > 0.05: print(‘Probably the same distribution‘) else: print(‘Probably different distributions‘) stat=-1.148, p=0.266 Probably the same distribution
p 值表示原假设发生概率大小。p 值越小说明原假设情况发生的概率就越小
2.F检验
t 检验是为检验均值是否有显著性差异,F 检验是为检验方差是否有显著性差异
car_a = np.array([28, 72, 73, 62, 27, 91, 76, 63, 95, 20]) car_b = np.array([86, 40, 60, 37, 64, 51, 39, 53, 26, 81]) def varf(a): return sum(np.power(a - np.mean(a),2)) / (len(a)-1) f = varf(car_a) / varf(car_b) f #1.9091713098080834
通过查表,在显著性上水平等于 0.05,样本个数都为 9 的情况下关键值为 3.18,统计值 f 小于 3.18,所以接收原假设 H0,即认为两种车型的方差无显著性差异
3.卡方检验
检验两组类别变量是相关的还是独立的(列联表的独立性角度)
H0: 两个样本是独立的
H1:两个样本不是独立的
from scipy.stats import chi2_contingency table = [[10, 20, 30],[6, 9, 17]] stat, p, dof, expected = chi2_contingency(table) print(‘stat=%.3f, p=%.3f‘ % (stat, p)) if p > 0.05: print(‘Probably independent‘) else: print(‘Probably dependent‘) ## 结果: stat=0.272, p=0.873 Probably independent
另一种卡方检验的方式是用于检测分类型变量是否符合期望频数。
例如,投掷一个 6 面筛子共 60 次,期望每一面出现的频次都为 10。但是不确定这个筛子是否动过手脚,于是投掷 60 次,得到实验数据如下:array([11, 8, 9, 8, 10, 14]), 使用卡方检验判断原假设 H0—未动过手脚,H1—动过手脚:
import scipy.stats as ss obs = np.array([11, 8, 9, 8, 10, 14]) exp = np.repeat(10, 6) #拒绝域 5% 的显著水平,自由度 5 jjy=ss.chi2.isf(0.05,5) # 卡方 kf = ss.chisquare(obs, exp).statistic print(jjy, kf) # 11.070497693516355 2.6 #5% 的显著水平,自由度 5 的拒绝域为大于 11.1,卡方检验计算的卡方值为 2.6,不在拒绝域内, #所以接收原假设,即筛子未动过手脚。
4.正态检验
Shapiro-Wilk Test是一种经典的正态检验方法
H0: 样本总体服从正态分布
H1: 样本总体不服从正态分布
import numpy as np from scipy.stats import shapiro data_nonnormal = np.random.exponential(size=100) data_normal = np.random.normal(size=100) def normal_judge(data): stat, p = shapiro(data) if p > 0.05: return ‘stat={:.3f}, p = {:.3f}, probably gaussian‘.format(stat,p) else: return ‘stat={:.3f}, p = {:.3f}, probably not gaussian‘.format(stat,p) # output normal_judge(data_nonnormal) # ‘stat=0.850, p = 0.000, probably not gaussian‘ normal_judge(data_normal) # ‘stat=0.987, p = 0.415, probably gaussian‘
5.ANOVA
目的:与t-test类似,ANOVA可以检验两组及以上独立样本集的均值是否具有显著差异
from scipy.stats import f_oneway import numpy as np data1 = np.random.normal(size=10) data2 = np.random.normal(size=10) data3 = np.random.normal(size=10) stat, p = f_oneway(data1, data2, data3) print(‘stat=%.3f, p=%.3f‘ % (stat, p)) if p > 0.05: print(‘Probably the same distribution‘) else: print(‘Probably different distributions‘) # output # stat=0.189, p=0.829 # Probably the same distribution
6.Mann-Whitney U Test
目的:检验两个样本集的分布是否相同
from scipy.stats import mannwhitneyu data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869] data2 = [1.142, -0.432, -0.938, -0.729, -0.846, -0.157, 0.500, 1.183, -1.075, -0.169] stat, p = mannwhitneyu(data1, data2) print(‘stat=%.3f, p=%.3f‘ % (stat, p)) if p > 0.05: print(‘Probably the same distribution‘) else: print(‘Probably different distributions‘) # output # stat=40.000, p=0.236 # Probably the same distribution
以上是关于假设检验的主要内容,如果未能解决你的问题,请参考以下文章