ZAB协议
Posted edda
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZAB协议相关的知识,希望对你有一定的参考价值。
一、简介
ZAB ,Zookeeper Atomic Broadcast,zk原子消息广播协议,是专为ZooKeeper设计的一种支持崩溃恢复的原子广播协议,在 Zookeeper中,主要依赖 ZAB 协议来实现分布式数据一致性。
Zookeeper使用一个单一主进程来接收并处理客户端的所有事务请求,即写请求。当服务器数据的状态发生变更后,集群采用ZAB原子广播协议,以事务提案Proposal的形式广播到所有的副本进程上。ZAB协议能够保证一个全局的变更序列,即可以为每一个事务分配一个全局的递增编号xid。
当Zookeeper 客户端连接到 Zookeeper 集群的一个节点后,若客户端提交的是读请求,那么当前节点就直接根据自己保存的数据对其进行响应;如果是写请求且当前节点不是Leader,那么节点就会将该写请求转发给Leader,Leader会以提案的方式广播该写操作,只要有超过半数节点同意该写操作,则该写操作请求就会被提交。然后Leader会再次广播给所有订阅者,即Learner,通知它们同步数据。
红线:读请求, 绿线:写请求
二、ZAB三种模式
ZAB协议中对zkServer的状态描述有三种模式。这三种模式并没有十分明显的界线,它们相互交织在一起。
- 恢复模式
- 广播模式
- 同步模式
三、初始化同步
恢复模式具有两个阶段:Leader选举与初始化同步。当完成Leader选举后,此时的Leader还是一个准Leader,其要经过初始化同步后才能变为真正的Leader。
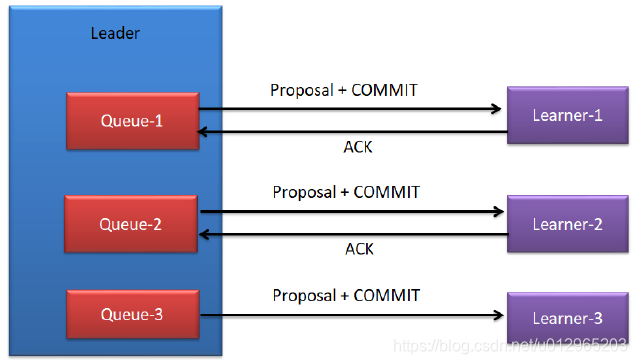
具体过程如下:
1> 为了保证Leader向Learner发送提案的有序,Leader会为每一个Learner服务器准备一个队列
2>Leader将那些没有被各个Learner同步的事务封装为Proposal
3> Leader将这些Proposal逐条发给各个Learner,并在每一个Proposal后都紧跟一个COMMIT消息,表示该事务已经被提交,Learner可以直接接收并执行
4> Learner接收来自于Leader的Proposal,并将其更新到本地
5> 当Follower更新成功后,会向准Leader发送ACK信息
6> Leader服务器在收到该来自Follower的ACK后就会将该Follower加入到真正可用的Follower列表。没有反馈ACK,或反馈了但Leader没有收到的Follower,Leader不会将其加入到Follower列表。
四、消息广播
当集群中已经有过半的Follower完成了初始化状态同步,那么整个zk集群就进入到了正常工作模式了。
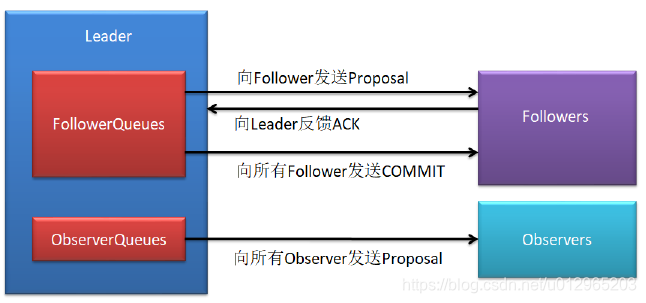
如果集群中的其他节点收到客户端的事务请求,那么这些Learner会将请求转发给Leader服务器。然后再执行如下的具体过程:
1> Leader 接收到事务请求后,为事务赋予一个全局唯一的 64 位自增 id,即zxid,通过 zxid 的大小比较即可实现事务的有序性管理,然后将事务封装为一个Proposal。
2> Leader根据Follower列表获取到所有Follower,然后再将Proposal通过这些Follower的队列将提案发送给各个Follower。
3> 当Follower 接收到提案后,会先将提案的zxid与本地记录的事务日志中的最大的zxid进行比较。若当前提案的zxid大于最大zxid,则将当前提案记录到本地事务日志中,并向Leader 返回一个ACK。
4> 当Leader 接收到过半的 ACKs 后,Leader 就会向所有Follower的队列发送 COMMIT消息,向所有Observer的队列发送Proposal。
5> 当 Follower收到 COMMIT 消息后,就会将日志中的事务正式更新到本地。当Observer收到Proposal后,会直接将事务更新到本地。
五、恢复模式的两个原则
当集群正在启动过程中,或Leader与超过半数的主机断连后,集群就进入了恢复模式。对于要恢复的数据状态需要遵循两个原则。
1>已被处理过的消息不能丢
当 Leader 收到超过半数Follower 的 ACKs 后,就向各个 Follower 广播 COMMIT消息,批准各个Server执行该写操作事务。当各个Server在接收到Leader的COMMIT消息后就会在本地执行该写操作,然后会向客户端响应写操作成功。
但是如果在非全部 Follower 收到 COMMIT 消息之前 Leader 就挂了,这将导致一种后果:部分Server已经执行了该事务,而部分Server尚未收到COMMIT消息,所以其并没有执行该事务。当新的Leader被选举出,集群经过恢复模式后需要保证所有Server上都执行了那些已经被部分Server执行过的事务。
1>被丢弃的消息不能再现
当 Leader 接收到事务请求并生成了Proposal,但还未向任何Follower发送时就挂了,因此,其他 Follower根本就不知道该Proposal的存在。当新的Leader选举出来,整个集群进入正常服务状态后,之前挂了的 Leader主机重新启动并注册成为了Follower。若那个别人根本不知道的Proposal还保留在那个主机,那么其数据就会比其它主机多出了内容,导致整个系统状态的不一致。所以,该Proposa应该被丢弃。类似这样应该被丢弃的事务,是不能再次出现在集群中的,应该被清除。
以上是关于ZAB协议的主要内容,如果未能解决你的问题,请参考以下文章