MR计算框架
Posted coeus-p
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MR计算框架相关的知识,希望对你有一定的参考价值。
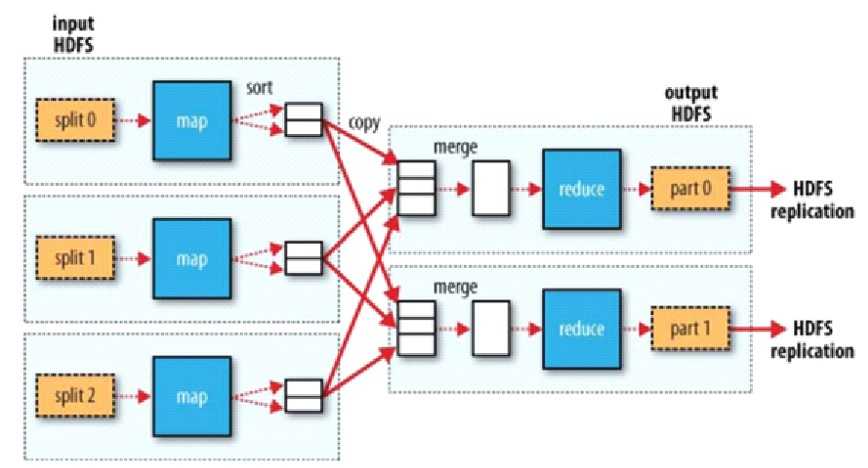
map数量
-
计算向数据移动,map计算框架移动到Block
-
map和Block不是一一对应,map与逻辑片(split)一一对应。原因:单个块可能过大,map处理时间长。所以block逻辑分块,多来几个map
reduce数量
-
按理说reduce应该和key数量一样,但是可能存在不同key对应的数据量不一样,有的太累有的太闲
-
一个reduce可以处理不同的key
-
死板:同一个key必须在一个reduce 上执行
四个阶段
-
切片
-
map
-
shuffle:相同的key成一组,交给同一个reduce处理
-
reduce
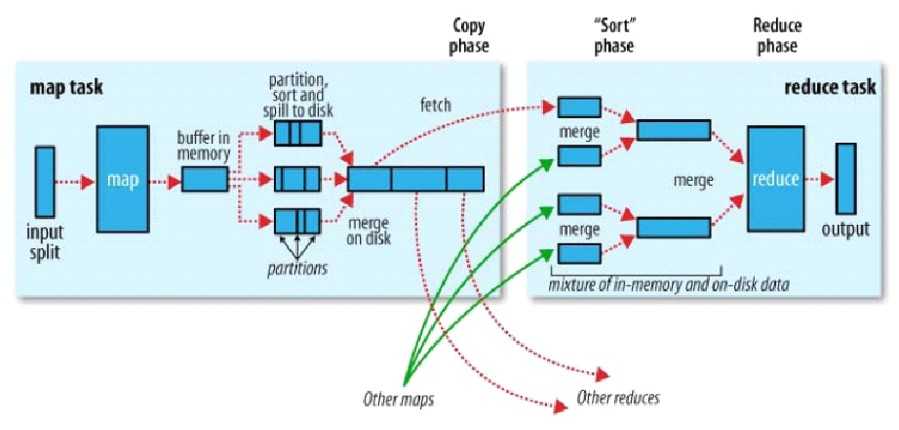
-
buffer in memory: 内存缓冲区
-
partition sort: 相同的key放在一起 第一次排序(分区排序)
-
key1 key2 交给同一个reduce,但是第一次排序完成了把key1 key2放在一个partion,但是内部是无序的
-
map阶段的 第二次排序, partion内部排序
-
buffer满了以后不是立即发到reduce,因为buffer size小,用一次传输不值得
-
所以buffer满了以后 先spill to disk 溢写到磁盘
-
多个溢写小文件merge to disk第三次排序
-
shuffle:多个map产生多个merge to disk,reduce不能说来一个map我处理一次,所以在这之前先第四次排序归并排序
以上是关于MR计算框架的主要内容,如果未能解决你的问题,请参考以下文章