重识信息收集
Posted tlbjiayou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重识信息收集相关的知识,希望对你有一定的参考价值。
0x00 前言
借着旺旺老师上的课,重新整理一下信息收集的思路。而且好久没写了,水一篇,最近太迷src了。
0x01 google hacking
常用:
--- “”:强制搜索包含关键字内的内容
--- site: 在特定的域名里搜索
--- site:cuit.edu.cn 默认密码为
--- inurl: 在url中搜索指定的关键字
--- inurl:oa.*.edu.cn 通达
--- inurl:index.php.bak
--- inurl:conf OR inurl:config OR inurl:cfg
--- inurl:log
--- filetype: 指定文件后缀
---:filetype:php (百度不支持)
---: filetype:log
--- intext: 网页中搜索
---: site:edu.cn intext:默认密码
---: inurl:login intext:版权信息 / 登陆说明
--- intitle:
---: intitle:index.of
---: intitle:index.of
---: intitle:index.of “Apache/1.3.27 Server at” (寻找特定服务器)
--- link:搜索与该连接有关的连接
--- link:cuit.edu.cn
0x02 shodan常用命令
此处为引用:https://blog.csdn.net/fly_hps/article/details/80610990
hostname——————————搜索指定的主机或域名,例如 hostname:baidu
port——————————————搜索指定的端口或服务,例如 port:80
country———————————搜索指定的国家,例如 country:US
city——————————————搜索指定的城市,例如 city:Chengdu
org———————————————搜索指定的组织或公司,例如 org:"Google"
isp———————————————搜索指定的ISP供应商,例如 isp:"China Telecom"
product———————————搜索指定的操作系统/软件/平台,例如 product:"Apache httpd"
version———————————搜索指定的软件版本,例如 version:"1.6.2"
geo———————————————搜索指定的地理位置,参数为经纬度,例如 geo:"31.8639, 117.2808"
before/after——————搜索指定收录时间前后的数据,格式为dd-mm-yy,例如 before:"11-11-15"
net———————————————搜索指定的IP地址或子网,例如 net:"210.45.240.0/24"
0x03 fofa 常用命令
此处引用:https://www.cnblogs.com/dgjnszf/p/11318319.html
title="后台管理" --标题中搜索
header="thinkphp" --响应头中搜索body="管理后台" --html正文搜索domain="itellyou.cn" --域名中带有host="login" -- 差不多也是域名带有的意思port="3388" && country=CN --端口与指定国家cert="phpinfo.me" --证书ports="3306,443,22" --端口
0x04 信息收集流程
---真实ip
---是否有cnd?是否有waf?
---有cdn后如何绕过?
--- cms
---是否有cms?
--- 基本信息采集
---服务器 linux|windows
---脚本 php|jsp|asp|aspx
---数据库 mysql|access|mssql|Oracle
---中间件(容器) apache|ngnix|tomcat|iss
--- 敏感信息采集
---whois
---电话
---邮箱
---社工库
--- 子域名采集
---通过搜索语法
Site:cuit.edu.cn (注意百度,谷歌收录不一样,可以多尝试)
---工具
-Layer子域名挖掘机
-subDomainBrute
-Sublist3r
-JSFinder (肖师傅写的。。tql)
-burp(爬虫提取)
--- 目录采集
---通过搜索语法
Site:cuit.edu.cn intitle:index.of (太多了,需要积累)
---工具
-dirsearch (强推)
-御剑
-dirb
-DirBuster (强推)
-7kbscan
--- 端口采集
-nmap (端口扫描之王)
0x04 工具学习
网上教程太多,写几款自己平时最喜欢用的。
#Diebuster
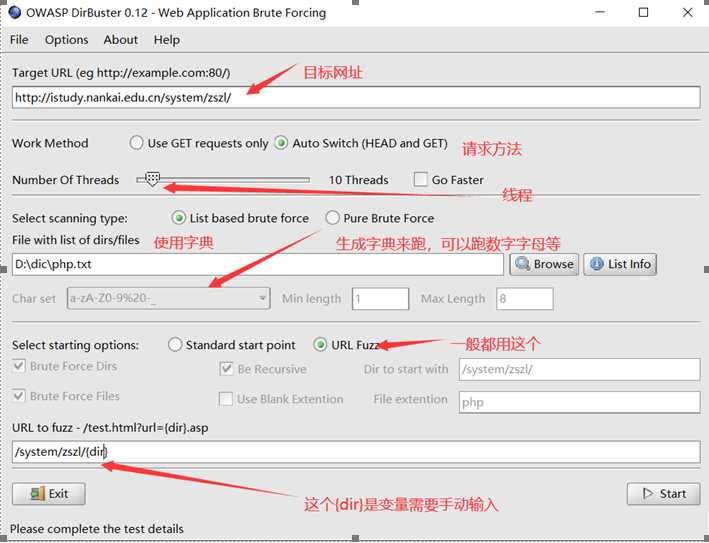
然后start就好。
用了用感觉不是很棒!最重要的还是自己收集的字典。这款工具我的用法就是用来测试越权修改什么的。
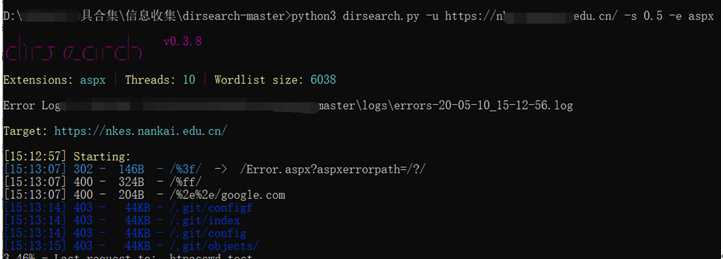
#dirsearch
基于python3开发,很强的一款工具,说几个常用的功能点
几个命令:
-u 指定网址
-L url字典
-e 指定语言
-w可以自己指定字典
-s 延时扫描 也可 --delay=
-random-agents 随机UA
用例:
延时扫描:(速度太快可能要ban ip)
python3 dirsearch.py -u http://www.baidu.com -s 0.5 -e *
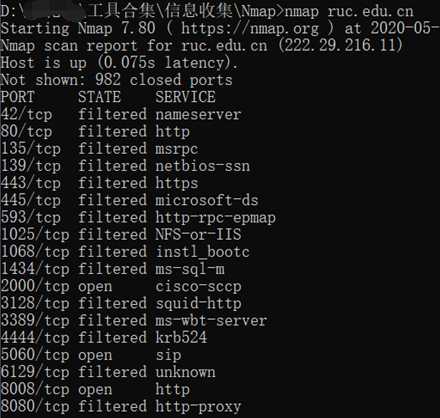
#nmap
没什么说的,端口扫描之王,神奇。。网上教程太多,这里写几个自己常用的命令
-F 扫描100个常见的端口
-p a-b 指定端口范围,扫描a到b
-p a,b 端口列表,扫描a和b
-A 详细扫描
-Pn 不探测扫描,默认主机存活
-sP 探测主机在线情况
-sV 服务版本扫描
-O 操作系统识别
-oA 生成文件 a.xml
当不加参数时,会探测主机是否存活,并且扫描常见端口。
nmap ruc.edu.cn
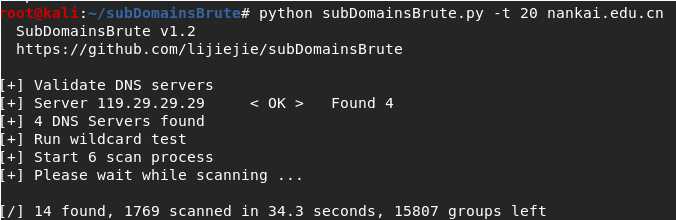
#subDomainBrute
最强大的子域名爆破工具(其实挖掘机也行)
Options:
-h, –help show this help message and exit
-t THREADS_NUM, –threads=THREADS_NUM --- 线程. default = 10
-f NAMES_FILE, –file=NAMES_FILE --- 字典 // 如果没有设置此参数就用默认字典
-o OUTPUT, –output=OUTPUT --- 输出结果 //没设置参数则会默认保存为 {target}.txt
Python subDomainBrute.py -t 10 nankai.edu.cn -o nankai.txt
即使没有保存,他也会再tmp文件中有

跑了两百条,当然,里面的域名不全对,有的域名访问不是200,这时候简单的写个脚本过滤一下就好。
import requests import re fp = open(‘nankai.txt‘, ‘r‘) f = open(‘naikai_200.txt‘, ‘a‘) content = fp.read() pattern = re.compile(‘(S+).*? ‘) results = re.findall(pattern, content) for result in results: url="http://"+result try: if requests.get(url, timeout = 0.5).status_code == 200: f.write(url) except: print("请求失败") fp.close() f.close()
经过过滤,找到60条有效url
0x05 写在最后
未完待续,欢迎补充。
以上是关于重识信息收集的主要内容,如果未能解决你的问题,请参考以下文章