01 . 分布式存储之FastDFS简介及部署
Posted you-men
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了01 . 分布式存储之FastDFS简介及部署相关的知识,希望对你有一定的参考价值。
FastDFS
介绍
FastDFS 是一个 C 语言实现的开源轻量级分布式文件系统,作者余庆(happyfish100),支持 Linux、 FreeBSD、 AID 等 Unix 系统,解决了大数据存储和读写负载均衡等问题,适合存储 4KB~500MB 之间的小文件,如图片网站、短视频网站、文档、app 下载站等,UC、京东、支付宝、迅雷、酷狗 等都有使用,其中 UC 基于 FastDFS 向用户提供网盘、广告和应用下载的业务的存储服务 FastDFS 与 MogileFS、HDFS、TFS 等都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务.
架构
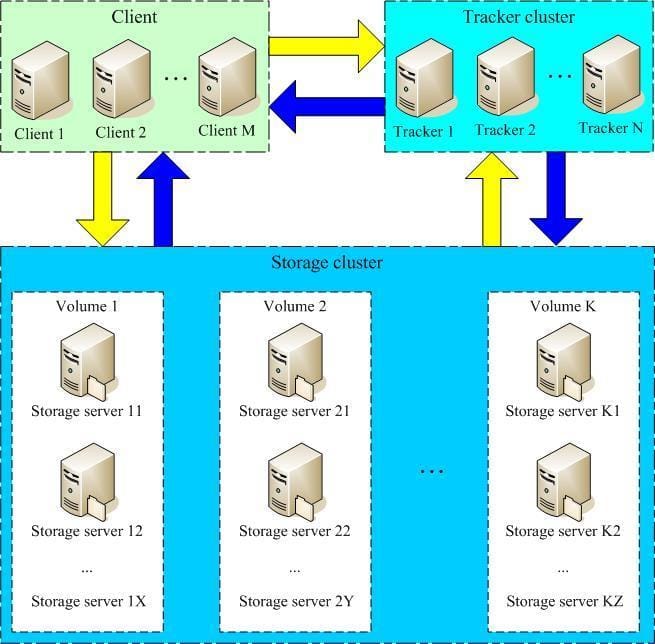
FastDFS 服务有三个角色:跟踪服务器(tracker server)、存储服务器(storage server)和 客户端(client)
tracker server:跟踪服务器,主要做调度工作,起到均衡的作用;负责管理所有的 storage server 和 group,每个 storage 在启动后会连接 Tracker, 告知自己所属 group 等信息,并保持周期性心跳, Tracker 根据 storage 心跳信息,建立 group--->[storage server list]的映射表;tracker 管理 的元数据很少,会直接存放在内存;tracker 上的元信息都是由 storage 汇报的信息生成的,本身 不需要持久化任何数据,tracker 之间是对等关系,因此扩展 tracker 服务非常容易,之间增加 tracker 服务器即可,所有 tracker 都接受 stroage 心跳信息,生成元数据信息来提供读写服务(与 其他 Master-Slave 架构的优势是没有单点,tracker 也不会成为瓶颈,最终数据是和一个可用的 Storage Server 进行传输的)
storage server:存储服务器,主要提供容量和备份服务;以 group 为单位,每个 group 内可以包 含多台 storage server,数据互为备份,存储容量空间以 group 内容量最小的 storage 为准;建 议 group 内的 storage server 配置相同;以 group 为单位组织存储能够方便的进行应用隔离、负 载均衡和副本数定制;缺点是 group 的容量受单机存储容量的限制,同时 group 内机器坏掉,数据 恢复只能依赖 group 内其他机器重新同步(坏盘替换,重新挂载重启 fdfs_storaged 即可)
多个 group 之间的存储方式有 3 种策略:round robin(轮询)、load balance(选择最大剩余空 间的组上传文件)、specify group(指定 group 上传)
group 中 storage 存储依赖本地文件系统, storage 可配置多个数据存储目录, 磁盘不做 raid, 直接分别挂载到多个目录,将这些目录配置为 storage 的数据目录即可
storage接受写请求时,会根据配置好的规则,选择其中一个存储目录来存储文件;为避免单 个目录下的文件过多,storage 第一次启时,会在每个数据存储目录里创建 2 级子目录,每级 256 个,总共 65536 个,新写的文件会以 hash 的方式被路由到其中某个子目录下,然后将文件数据直 接作为一个本地文件存储到该目录中
总结:1.高可靠性:无单点故障 2.高吞吐性:只要 Group 足够多,数据流量是足够分散的
FastDFS 提供基本的文件访问接口,如 upload、download、append、delete 等
选择 tracker server
集群中 tracker 之间是对等关系,客户端在上传文件时可用任意选择一个 tracker
选择存储 group
当 tracker 接收到 upload file 的请求时,会为该文件分配一个可以存储文件的 group,目前 支持选择 group 的规则为:
- Round robin,所有 group 轮询使用
- Specified group,指定某个确定的 group
- Load balance,剩余存储空间较多的 group 优先
选择 storage server
当选定 group 后,tracker 会在 group 内选择一个 storage server 给客户端,目前支持选择 server 的规则为:
- Round robin,所有 server 轮询使用(默认)
- 根据 IP 地址进行排序选择第一个服务器(IP 地址最小者)
- 根据优先级进行排序(上传优先级由 storage server 来设置,参数为 upload_priority)
选择 storage path(磁盘或者挂载点)
当分配好 storage server 后,客户端将向 storage 发送写文件请求,storage 会将文件分配一 个数据存储目录,目前支持选择存储路径的规则为:
round robin,轮询(默认)load balance,选择使用剩余空间最大的存储路径
选择下载服务器
目前支持的规则为:
- 轮询方式,可以下载当前文件的任一 storage server
- 从源 storage server 下载
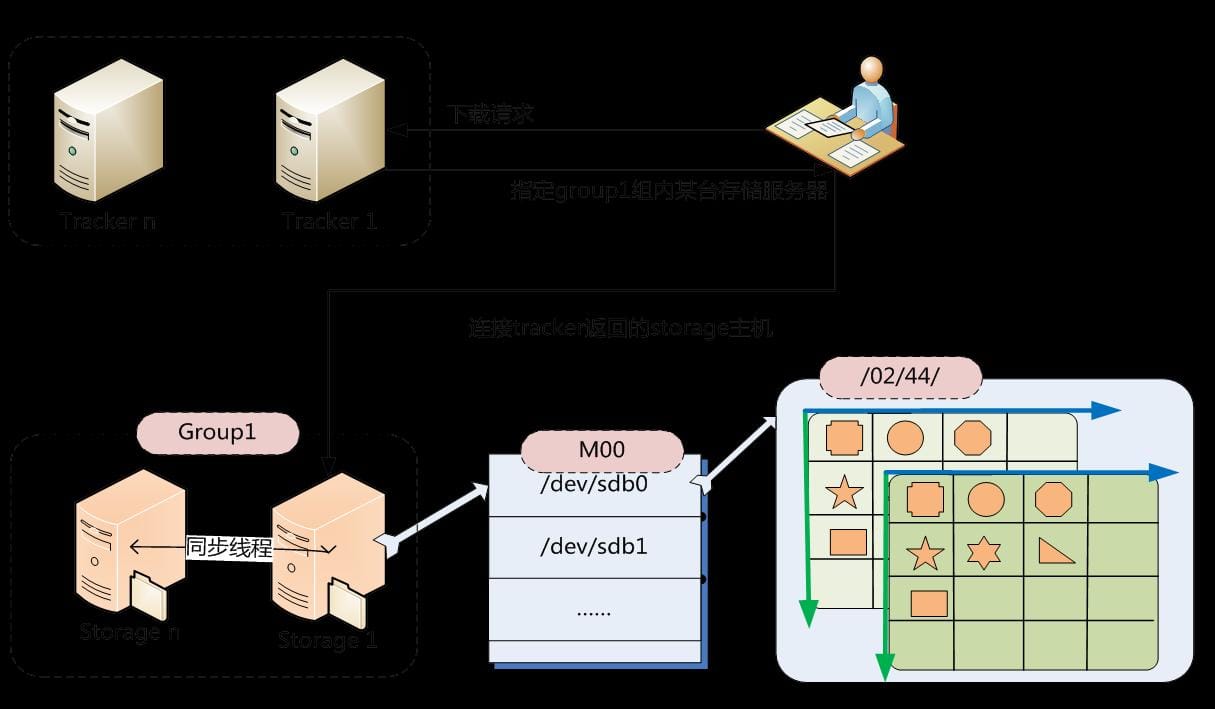
生成 file_id
选择存储目录后,storage 会生成一个 file_id,采用 Base64 编码,包含字段包括:storage server ip、文件创建时间、文件大小、文件 CRC32 校验码和随机数;每个存储目录下有两个 256*256 个子目录,storage 会按文件 file_id 进行两次 hash,路由到其中一个子目录,,然后将文件已 file_id 为文件名存储到该子目录下,最后生成文件路径:group 名称、虚拟磁盘路径、数据两级 目录、file_id

其中,组名:文件上传后所在的存储组的名称,在文件上传成功后由存储服务器返回,需要客户端 自行保存
虚拟磁盘路径:存储服务器配置的虚拟路径,与磁盘选项 store_path*参数对应
数据两级目录:存储服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件
同步机制
新增 tracker 服务器数据同步问题
由于 storage server 上配置了所有的 tracker server,storage server 和 tracker server 之间的通信是由 storage server 主动发起的,storage server 为每个 tracker server 启动一个线程进行通信;在通信过程中,若发现该 tracker server 返回的本组 storage server 列表比本机记录少,就会将该 tracker server 上没有的 storage server 同步给该 tracker,这样的机制使得 tracker 之间是对等关系,数据保持一致
新增 storage 服务器数据同步问题
若新增 storage server 或者其状态发生变化,tracker server 都会将 storage server 列表同步给该组内所有 storage server;以新增 storage server 为例,因为新加入的 storage server 会主动连接 tracker server,tracker server 发现有新的 storage server 加入,就会将该组内所有的 storage server 返回给新加入的 storage server,并重新将 该组的 storage server 列表返回给该组内的其他 storage server;
组内 storage 数据同步问题
组内 storage server 之间是对等的, 文件上传、 删除等操作可以在组内任意一台 storage server 上进行。文件同步只能在同组内的 storage server 之间进行,采用 push 方式, 即源服务器同步到目标服务器
- 只在同组内的 storage server 之间进行同步
- 源数据才需要同步,备份数据不再同步
- 特例:新增 storage server 时,由其中一台将已有所有数据(包括源数据和备份数
据)同步到新增服务器
storage server 的 7 种状态: 通过命令 fdfs_monitor /etc/fdfs/client.conf 可以查看 ip_addr 选项显示 storage server当前状态 INIT: 初始化,尚未得到同步已有数据的源服务器 WAIT_SYNC :等待同步,已得到同步已有数据的源服务器 SYNCING : 同步中 DELETED : 已删除,该服务器从本组中摘除 OFFLINE : 离线 ONLINE : 在线,尚不能提供服务 ACTIVE : 在线,可以提供服务
组内增加 storage serverA 状态变化过程
storage server A主动连接 tracker server,此时 tracker server 将 storage serverA 状态设置为 INITstorage server A向 tracker server 询问追加同步的源服务器和追加同步截止时间点(当前时间),若组内只有 storage server A 或者上传文件数为 0,则告诉新机器不需要数据同步,storage server A 状态设置为 ONLINE ;若组内没有 active状态机器,就返回错误给新机器,新机器睡眠尝试;否则 tracker 将其状态设置为WAIT_SYNC- 假如分配了 storage server B 为同步源服务器和截至时间点,那么 storage server B 会将截至时间点之前的所有数据同步给 storage server A,并请求 tracker 设置 storage server A 状态为 SYNCING;到了截至时间点后, storage server B 向 storage server A 的同步将由追加同步切换为正常 binlog 增量同步,当取不到更多的 binlog 时,请求 tracker 将 storage server A 设置为 OFFLINE 状态,此时源同步完成
storage server B向 storage server A 同步完所有数据,暂时没有数据要同步时,storage server B 请求 tracker server 将 storage server A 的状态设置为 ONLINE- 当 storage server A 向 tracker server 发起心跳时,tracker sercer 将其状态更改为 ACTIVE,之后就是增量同步(binlog)
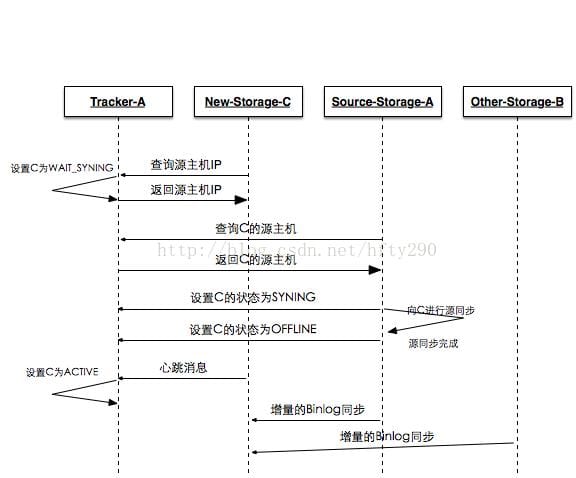
注释:
- 整个源同步过程是源机器启动一个同步线程,将数据 push 到新机器,最大达到一个磁盘的 IO,不能并发
- 由于源同步截止条件是取不到 binlog,系统繁忙,不断有新数据写入的情况,将会导致一直无法完成源同步过程
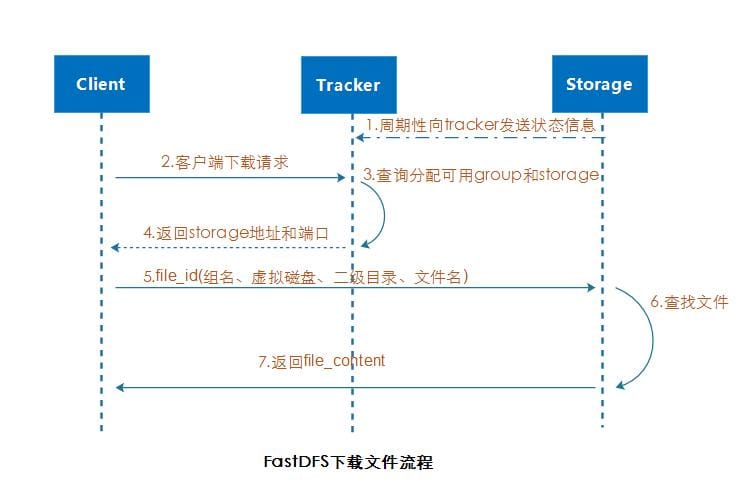
下载
client 发送下载请求给某个 tracker,必须带上文件名信息,tracker 从文件名中解析出文件的 group、大小、创建时间等信息,然后为该请求选择一个 storage 用于读请求;由于 group 内的文 件同步在后台是异步进行的,可能出现文件没有同步到其他 storage server 上或者延迟的问题, 后面我们在使用 nginx_fastdfs_module 模块可以很好解决这一问题
文件合并原理
小文件合并存储主要解决的问题:
- 本地文件系统 inode 数量有限,存储小文件的数量受到限制
- 多级目录+目录里很多文件,导致访问文件的开销很大(可能导致很多次 IO)
- 按小文件存储,备份和恢复效率低
FastDFS 提供合并存储功能,默认创建的大文件为 64MB,然后在该大文件中存储很多小文件; 大文件中容纳一个小文件的空间称作一个 Slot,规定 Slot 最小值为 256 字节,最大为 16MB,即小于 256 字节的文件也要占用 256 字节,超过 16MB 的文件独立存储;
为了支持文件合并机制, FastDFS 生成的文件 file_id 需要额外增加 16 个字节; 每个 trunk file 由一个 id 唯一标识,trunk file 由 group 内的 trunk server 负责创建(trunk server 是 tracker 选出来的),并同步到 group 内其他的 storage,文件存储合并存储到 trunk file 后,根据其文件 偏移量就能从 trunk file 中读取文件
FastDFS 安装部署
Install FastDfs shell
#!/bin/bash
#auther: kame
## Install fastdfs
FastDFS_DIR=/opt/fastdfs
yum makecache
yum -y install gettext gettext-devel libXft libXft-devel libXpm libXpm-devel automake autoconf libXtst-devel gtk+-devel gcc gcc-c++zlib-devel libpng-devel gtk2-devel glib-devel pcre* gcc git
mkdir -p $FastDFS_DIR
## create data1 data2
cd $FastDFS_DIR
git clone https://github.com/happyfish100/libfastcommon.git
cd libfastcommon
./make.sh
./make.sh install
echo "Finshed Install libfastcommon"
cd $FastDFS_DIR
git clone https://github.com/happyfish100/fastdfs.git
cd fastdfs
sed -i ‘s#/usr/local/bin/#/usr/bin/#g‘ init.d/fdfs_storaged
sed -i ‘s#/usr/local/bin/#/usr/bin/#g‘ init.d/fdfs_trackerd
./make.sh
./make.sh install
Install Fastdfs_nginx shell
#!/bin/bash
nginx=‘nginx-1.7.9‘
install_dir=/opt/nginx
fastdfs_dir=/opt/fastdfs
mkdir $install_dir
cd $install_dir
wget http://nginx.org/download/$nginx.tar.gz
git clone https://github.com/happyfish100/fastdfs-nginx-module.git
tar xf $nginx.tar.gz
cd $nginx
./configure --add-module=../fastdfs-nginx-module/src/ --prefix=/usr/local/nginx --user=nobody --group=nobody --with-http_gzip_static_module --with-http_gunzip_module
make -j8
make install
cp $install_dir/fastdfs-nginx-module/src/mod_fastdfs.conf /etc/fdfs/
cp $fastdfs_dir/fastdfs/conf/{anti-steal.jpg,http.conf,mime.types} /etc/fdfs/
touch /var/log/mod_fastdfs.log
chown nobody.nobody /var/log/mod_fastdfs.log
以上是关于01 . 分布式存储之FastDFS简介及部署的主要内容,如果未能解决你的问题,请参考以下文章