计网自顶向下--深入理解传输层
Posted zhpisnotphz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计网自顶向下--深入理解传输层相关的知识,希望对你有一定的参考价值。
传输层
可靠传输层模型
RDT1.0
-
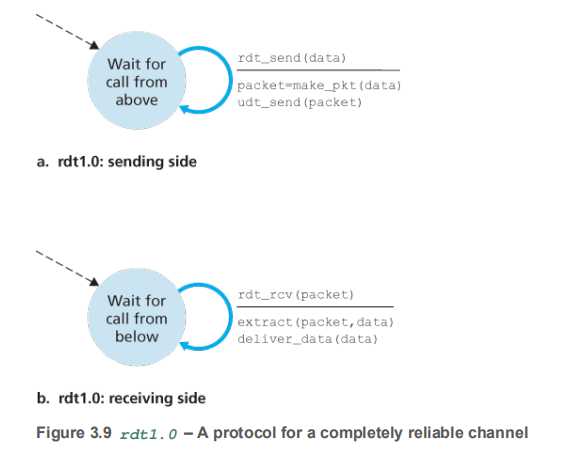
-
信赖底层协议,认为底层协议是可靠的,但是实际上底层协议IP层是不可靠协议
RDT 2.0
-
在1.0的基础上加上了
ARQ (Automatic Repeat reQuest) protocolsACK :positive acknowledgments
NCK :negative acknowledgments
-
ARQ包括:
-
错误校验(Error detection.):
和UDP的checksum一样,需要额外的位(extra bits)来做校验
-
接受者的回复(Receiver feedback)
a 0 value could indicate a NAK and a value of 1 could indicate an ACK. -
重新发送(Retransmission)
接受有错的包将会重新由sender发送
-
-
有限状态机分析(FSM)
-
sender:
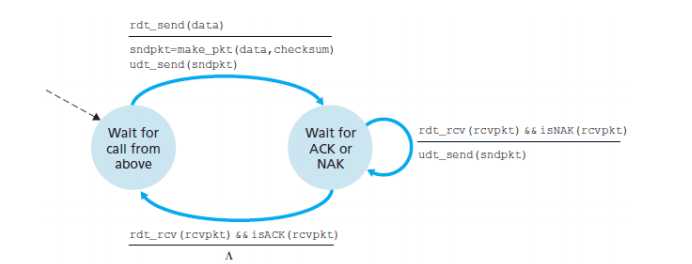
两个状态,一个是等待上层唤起(rdt_send(data))
接着制作发送的包(sndpkt=make_pkt(data,checksum))
最后发送该包(udt_send(sndpkt))
这里的udt是指的UDP-based Data Transfer Protocol吗?
接着进入第二个状态,等待ACK和NAK的状态
收到received packet并且检验是否为NAK(rdt_rcv(rcvpkt)&&isNAK(rcvpkt))
如果是就重复该状态
否则回到第一个状态(rdt_rcv(rcvpkt)&&isACK(rcvpkt))
-
receiving side

一个状态
如果有错,就制作一个NAK的包发过去

否则就解析、传递数据给对应进程,并且制作一个ACK的包发过去

-
-
特点:
-
sender只有在确认接收方得到了数据包之后才会发一下个,所以这种发送方式也被称为
stop-and-wait协议(Thus, the sender will not send a new piece of data until it is sure that the receiver has correctly received the current packet. Because of this behavior, protocols such as rdt2.0 are known as stop-and-wait protocols.)
-
RDT2.0依然有问题,主要在于没有考虑到ACK和NCK包也可能会出问题
哪怕是加了校验位也很难,因为你只知道有问题,但不知道怎么复原
(The more difficult question is how the protocol should recover from errors in ACK or NAK packets.)
解决方式有几种:
-
加入一种新的包来让对方重新发送(即,“我妹听清楚”)
(thus introducing a new type of sender-to-receiver packet to our protocol)
-
加入足够多的校验位,让我们不仅能够知道错了,还能知道哪里错了
-
第三种就是发送方收到一个错误的ACK包或NAK包(garbled ACK or NAK)时,只是重新发送当前数据包。这样做会引发新的问题,接收方不知道这个是新的包还是旧的包,可能会有数据的冗余出现
-
第四种方法,就是在基于stop-and-wait协议上用一个1-bit的序列号(sequence number)来标记是否为重复发送,这就是RDT2.1
-
-
RDT2.1
-
有限状态机分析(FSM)
-
sender
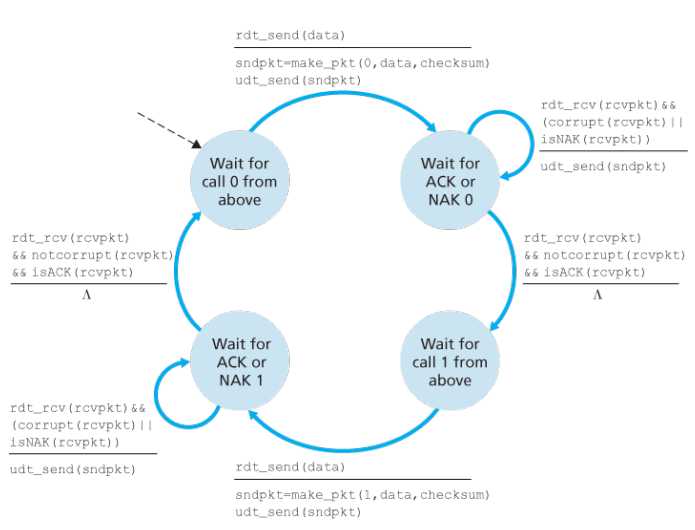
- 先等待上层协议唤起一个等待0 的状态,制作一个带有序列号0 ,数据data,校验和checksum的包,用udt_send 发送【第一个状态】
- 接着转为一个等待0序列的ACK和NAK【第二个状态】
- 如果是ACK包或NAK包有corrupt或返回的是一个NAK包,就重新发送原来的sndpkt
- 否则就进入一个等待上层协议唤起等待1的状态,唤起后制作一个带有序列号1,数据data,校验和checksum的包,用udt_send发送【第三个状态】
- 接着转为一个等待序列1的ACK或NAK【第四个状态】
- 反复重复
-
receiver
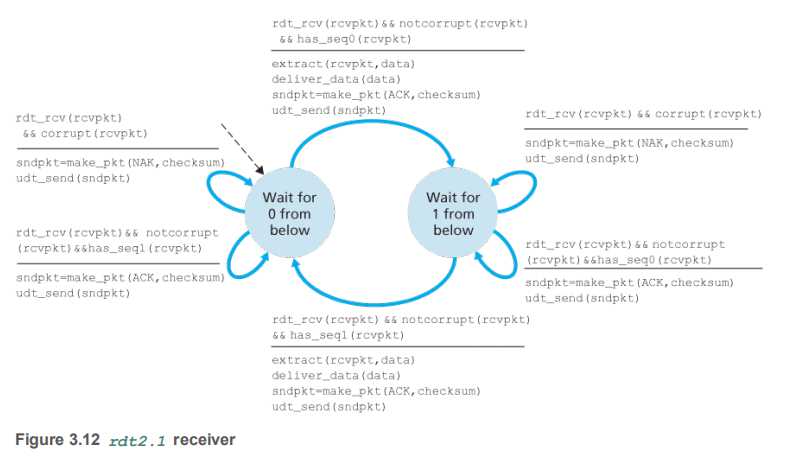
-
【状态一】接收方有两个状态,接收方先等待一个0序列包,
如果是包有错误,就发送一个NAK消息给sender
如果是包没有错误,但是收到的是一个1序列包,就说明sender是没有听清楚我的确认消息,重新发送了之前的包,由于stop-and-wait,我一定是接收到正确的包之后才会发生状态转换,所以这个1序列包已经是我接收过的了,所以我发送一个ACK包回去,并且继续等待我的0号包
如果包没有错误,并且收到的是一个0序列包,就解析,传递数据,并且返回ACK包
进入第二个等待1的状态
-
【状态二】对称地重复上面的内容
-
-
RDT2.2
-
RDT2.2是一种不用NAK的协议(NAK-free protocol),使用ACK+序列号来解决问题(duplicate ACK at sender results in same action as NAK :retransmit current pkt)
-
有限状态机分析(FSM)
-
sender
-
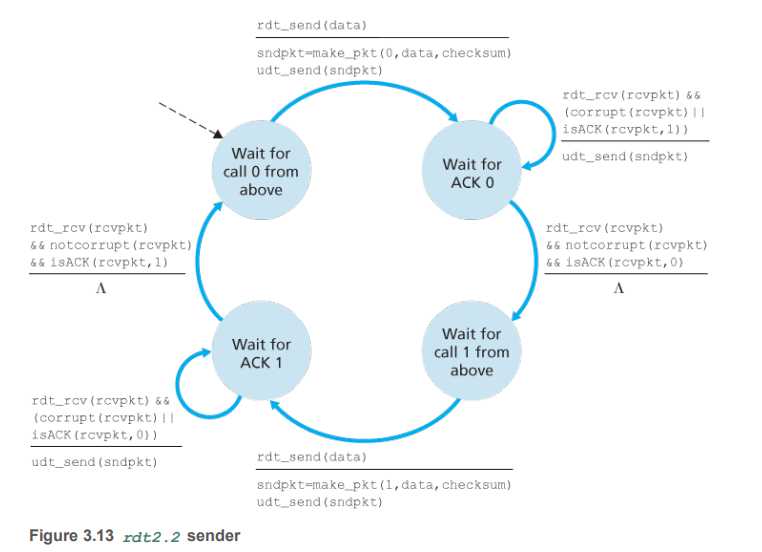
淦,差不多的,不想写了
-
-
RDT3.0
-
RDT 2.* 只考虑了数据包出现位错误的问题( corrupting bits),没有考虑丢包的(lose packets)问题(虽然不常见)
-
RDT 3.0引入了timer,一个计时器来解决丢包的问题
-
也被叫做交替位协议(alternating-bit protocol)
-
有限状态机分析
-
sender
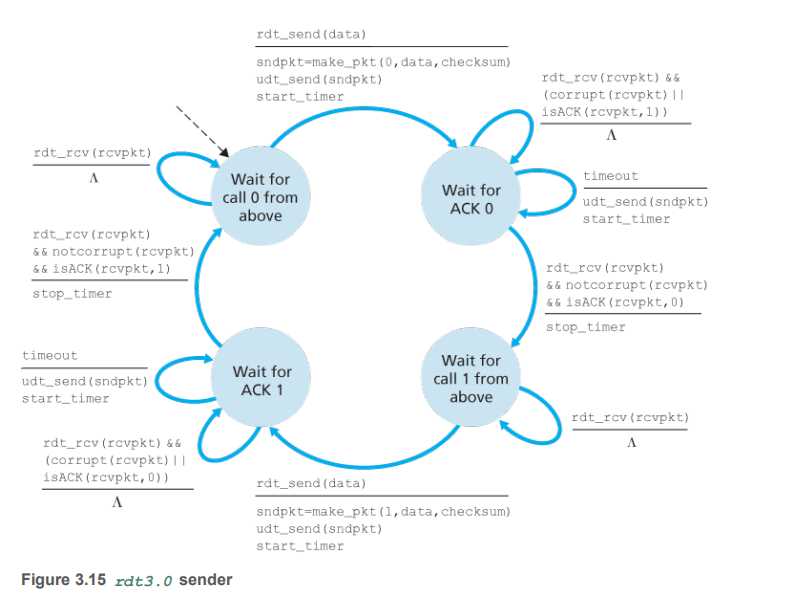
主要改进就是,在发送了一个sndpkt之后,会有一个start_timer 的动作,设置一个计时器
如果收到的确认包有错或者是ACK+不期待的序列号,那么就继续等待,直到timeout超时了还没有的话,就重新发送,并且同时重置start_timer,即每次发送了sndpkt之后都会重置计时器的。
-
receiver和RDT2.2就是一样的了
-
-
RDT3.0存在的问题
-
这是一个功能上完善但是性能上不能令人满意的协议,主要就是他的stop-and-wait的协议
-
书上的图:
-
没有出问题时的情况:
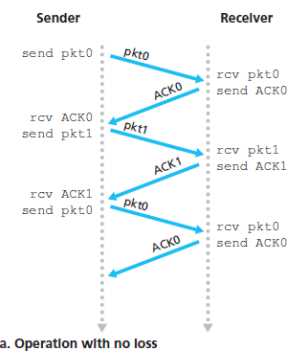
-
出问题了:
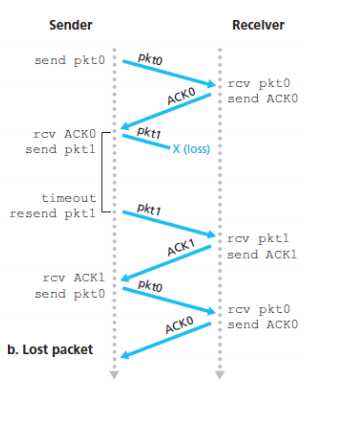
【lost packet】发送的包在中途丢失,接收方自然不会发送确认信息,发送方等到超时后重发
【lost ACK】发送方收不到确认ACK包,就等到超时之后重发原包,因为和接收方的序列号不一致,接收方知道是已经收到过的,就丢弃
【premature timeout】接收方的ACK包延时了,收到的时候已经超时了,但是因为序列号的缘故,乱序并不会影响
-
-
pipelined sending
-
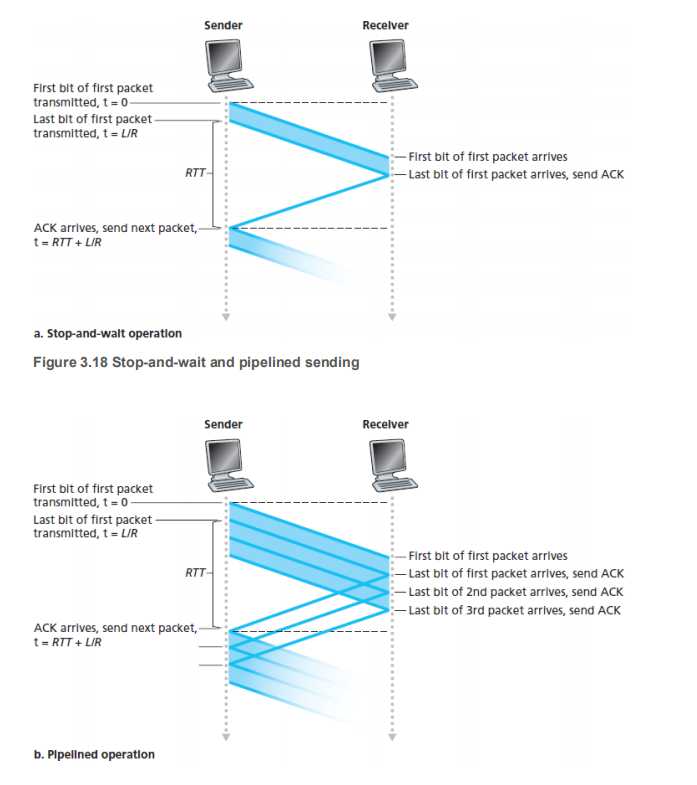
-
上图是pipeline和阻塞式的对比
可以看到,阻塞式的信道利用率是
$$
(L/R)/(L/R+RTT)
$$
而pipeline的利用率是阻塞式的三倍
$$
(L/R)*3/(L/R+RTT)
$$ -
为了做到pipeline,我们需要在这RDT3.0的基础上继续添加内容
- 增加序列号
- 实现缓存
Go-Back-N (GBN)
-
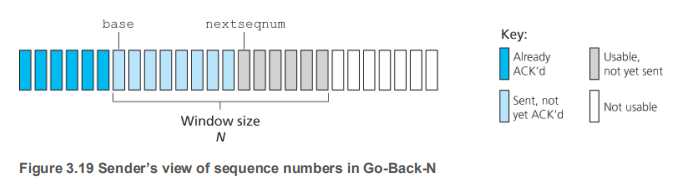
从左往右:
已经ACK了的,
已经发送,但是没ACK的,
准备好了,还没发送的,
还没准备好的
即:base是最老的那个发了还没ACK的
? nextseqnum是即将发送的
-
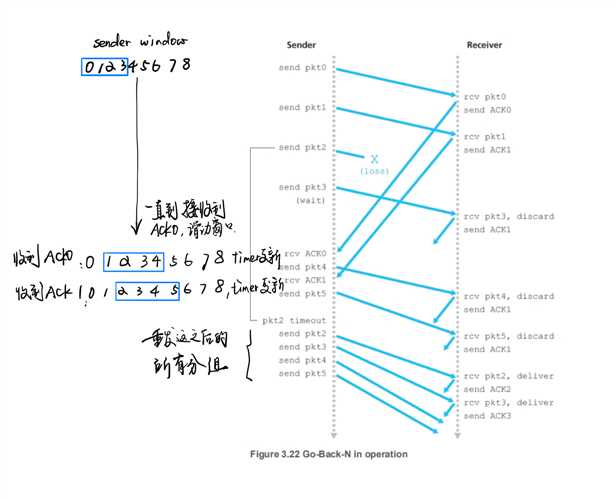
-
GBN的问题
- 主要是累计确认和全部重发,会在当窗口大小和带宽延迟都比较大的时候,很多包可能在管道中,因此,一个数据包错误就可能导致GBN重新传输大量的数据包,这是不必要的
- 于是我们又引入了
selective-repeat来解决这一问题
-
selective-repeat(SR) -
TCP详解
连接的具体含义(The TCP Connection)
- the connection is a logical one
- 【客户端】套接字刚刚创建完成的时候,里面并没有存放任何数据,也不知道通 信的对象是谁。在这个状态下,即便应用程序要求发送数据,协议栈也不 知道数据应该发送给谁。浏览器可以根据网址来查询服务器的 IP 地址,而 且根据规则也知道应该使用 80 号端口,但只有浏览器知道这些必要的信息 是不够的,因为在调用 socket 创建套接字时,这些信息并没有传递给协议 栈。因此,我们需要把服务器的 IP 地址和端口号等信息告知协议栈,这是连接操作的目的之一
- 【服务器端】那么,服务器这边又是怎样的情况呢?服务器上也会创建套接字 A,但 服务器上的协议栈和客户端一样,只创建套接字是不知道应该和谁进行通 信的。而且,和客户端不同的是,在服务器上,连应用程序也不知道通信 对象是谁,这样下去永远也没法开始通信。于是,我们需要让客户端向服 务器告知必要的信息,比如“我想和你开始通信,我的 IP 地址是 xxx.xxx. xxx.xxx,端口号是 yyyy。”可见,客户端向服务器传达开始通信的请求, 也是连接操作的目的之一。
- 【连接的具体含义】
- 连接实际上是通信双方交换控制信息,在套接字中记 录这些必要信息并准备数据收发的一连串操作
- 此外,当执行数据收发操作时,我们还需要一块用来临时存放 要收发的数据的内存空间,这块内存空间称为缓冲区,它也是在连接操作 的过程中分配的。上面这些就是“连接”B 这个词代表的具体含义。
- A TCP connection provides a
full-duplex service:
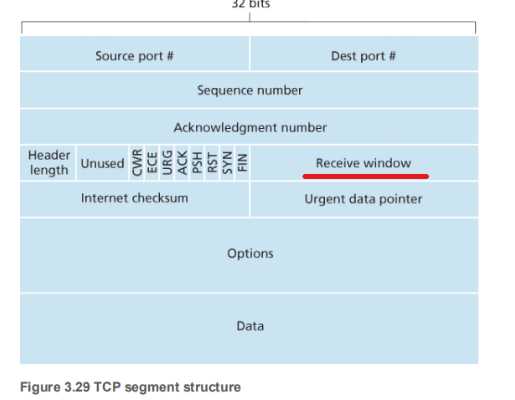
TCP 结构(TCP Segment Structure)
-
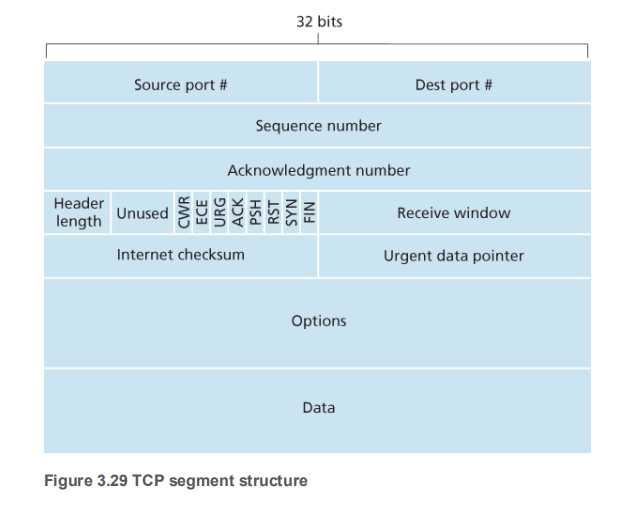
-
从上到下,从左到右:
-
发送方端口号:16bits
-
接收方端口号:16bits
-
序列号【发送数据的序列编号】:32bits(发送方告知接收方该网络包发送的数据相当于所有发送数据的第几个字节)
-
ACK号【接受数据的顺序编号】:32bits(接收方告知发送方已经收到了所有数据的第几个字节)
-
数据偏移量【头部的长度】:4bits
-
保留位:4bits
-
控制位:6bits
-
窗口号:16bits【接收方告知发送方窗口大小(即无需等待确认可一起发送的数据量)
-
校验和:16bits
-
紧急指针:16bits
-
可选字段:可变长度
-

TCP Sequence Numbers and Acknowledgment Numbers
- 每一个TCP段的序列号是该段的第一个字节占字节流的第几个字节(The sequence number for a segment is therefore the byte-stream number of the first byte in the segment.)
- TCP is
full-duplex这意味着,主机A到主机B可能在同一个TCP连接上,同时有发送数据和接收数据, - 所以发送的ACK号,是希望收到的一下个序列号(The acknowledgment number that Host A puts in its segment is the sequence number of the next byte Host A is expecting from Host B.)
- TCP只接收自己希望的,所以TCP是累计确认(cumulative acknowledgments)
TCP 的重传机制(Round-Trip Time Estimation and Timeout)
-
估计RTT时间
-
先通过统计学采样获取sampleRTT
-
之后用权值,将其和历史sampleRTT结合得到estimateRTT
EstimatedRTT=(1-α)*EstimatedRTT +α * SampleRTT
α通常取值为0.25
-
为了不让RTT变化过于剧烈,加上一个偏差:
DevRTT= (1- β)*DevRTT + β * |SampleRTT -EstimatedRTT |
通畅来说,β取值为0.25
-
最后得到的延时时间应该为:
$$
TimeoutInterval = EstimatedRTT +4 * DevRTT
$$
-
-
思考:
We have discussed TCP‘s estimation of RTT, Why do you think TCP avoid measuring the SampleRTT for retransmitted segments?
【答】:重传情况下,RTT可能会有很大的偏差,比如,0号段的ACK在路上堵车了,超时没有收到,sender重发,然后这时之前堵车的ACK来了,在sender看来,他是无法区分这个ACK到底是之前发的,还是重发返回的ACK,在sender眼里,就是我刚刚重发,马上就有响应了,所以RTT会大幅度的缩短。所以没有意义。
书上作者认为的一些“有趣的场景”(┗( ▔, ▔ )┛)
-
【返回包丢失的情况】
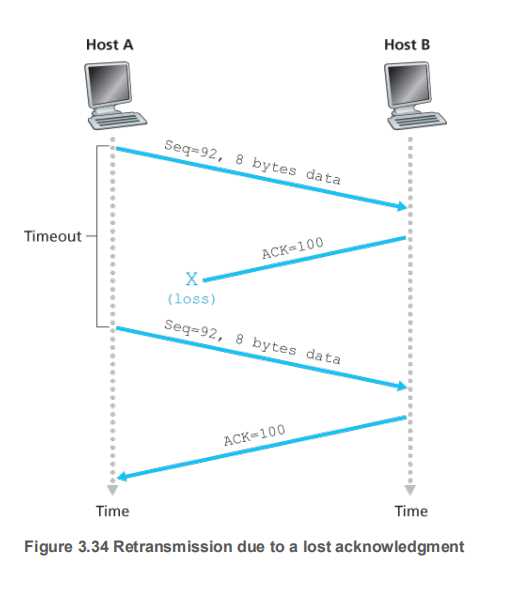
上图中,A向B发送了一个序列号为92,长度为8的TCP段:
92 93 94 95 96 97 98 99 主机B向A确认,并返回期望拿到的序列号:ACK100,这个包在路上走丢了
主机A等待超时之后重传该包即可
-
【两次超时】
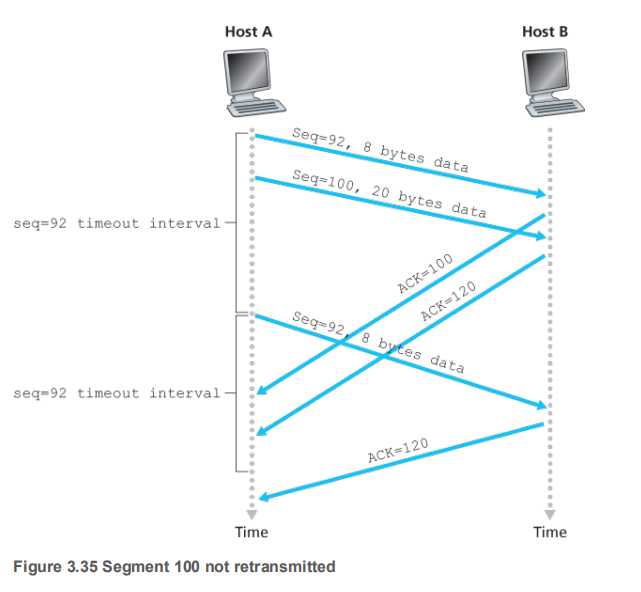
上图中主要的特殊在于,在sender重发了第一个段(92)之后,接收方没有返回ACK100,而是返回的ACK120,因为receiver的base指针已经累计增加到了120,他知道自己120之前的都已经接受了,只需要孜孜不倦的向sender问后面的内容即可。
-
【没有名字】
在上图中,receiver始终孜孜不倦的请求自己认为自己需要的,而不管sender到底怎么理解,
sender接收到ACK120之后,sender心里明白,receiver是一定拿到了92-99,才会发给自己ACK120的,【TCP的累计确认】。所以sender就直接将base滑动到120。避免了冗余的重复包发送。
TCP的快速重传
-
接收方发送ACK,更实际的情况下,有四种情况:
事件 TCP接收方的处理方式 正常情况,接收到顺序收到的TCP段,并且之前的都acknowledged了 接收方会delayed ACK,将其挂起500ms,之后再发送。这样的好处是少发点ACK包,假设在这段时间里有其他正常收到的TCP段,根据刚刚说的,sender心里明白receiver是累计接收的,所以只需要发最后一个ACK包即可 收到一个正常的TCP段,并且有一个正常的ACK在挂起 直接发送ACK包 有比期望序号更大的段到达 马上发送一个我期望的ACK包过去(为什么) 有能部分或者完全填充gap的段到达 如果该报段是间隔的低端,就立刻发送ACK -
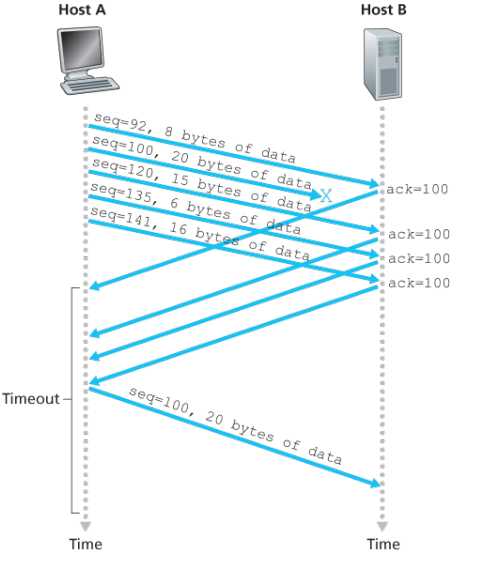
上图说明了上表中的第三种情况。一旦有乱序的段送过来,就立刻反复唠叨自己真正想要的包
一旦sender接受到三个重复的包,就会立马重传。
【为什么快速重传是选择3次ACK?】
分包的丢失要看是链路故障还是乱序
两次duplicate ACK时,要让sender立马重发,(而不是等到timeout了之后),那得是丢包了
接收方叽叽喳喳的duplicate ACK越多,就说明越可能是丢包,但是还是要考虑一个响应策略的速度,不能等到接收方苦口婆心喊了你妈几十次才反应
根据统计规律,三次duplicate ACK时立刻重新发送是极好的。
TCP的流量控制(flow control)
-
流量控制根本原因在于,接收方的应用层不会一直搁这儿处理这个进程,如果人家半天没理睬你,然后发送方还一直发送一直发送,接收方就只能受不了了。(??へ??╬)
(Recall that the hosts on each side of a TCP connection set aside a receive buffer for the connection. When the TCP connection receives bytes that are correct and in sequence, it places the data in the receive buffer. The associated application process will read data from this buffer, but not necessarily at the instant the data arrives. Indeed, the receiving application may be busy with some other task and may not even attempt to read the data until long after it has arrived. If the application is relatively slow at reading the data, the sender can very easily overflow the connection’s receive buffer by sending too much data too quickly.)
-
处理方法就是在两边交流,接收方告知发送方,我的缓存还剩多少
-
区分流量控制(flow control)与拥塞控制(congestion control)
(As noted earlier, a TCP sender can also be throttled due to congestion within the IP network; this form of sender control is referred to as congestion control, a topic we will explore in detail in Sections 3.6 and 3.7. Even though the actions taken by flow and congestion control are similar (the throttling of the sender), they are obviously taken for very different reasons.)
-
细节:
-
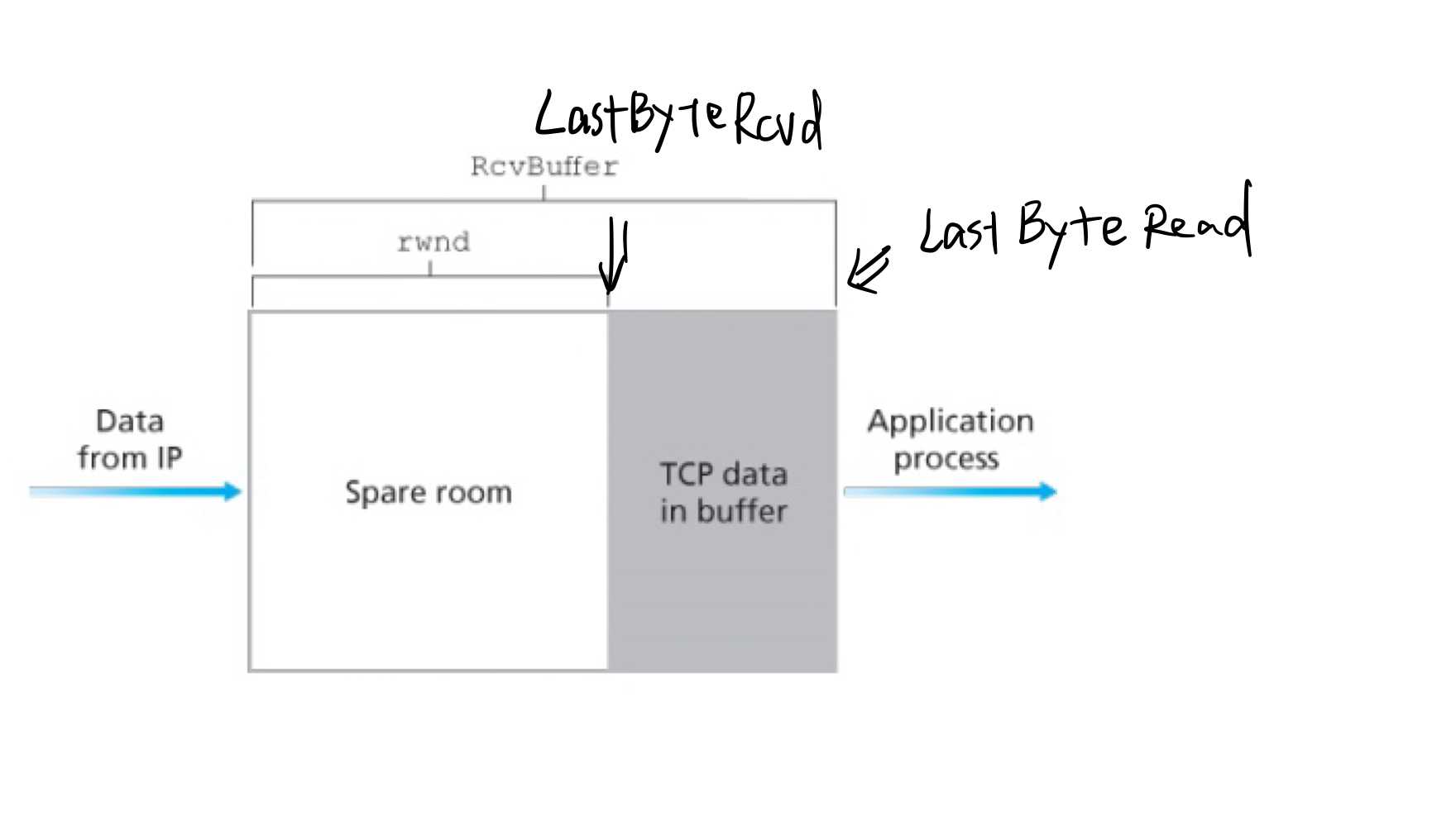
在receiver的应用层,定义了两个变量:
LastByteRead:应用层读取的最后一个字节的序号LastByteRcvd从网络层读取的最后一个字节,放在缓冲区的什么地方为了不让缓冲区溢出,我们需要:
$$
LastByteRcvd?LastByteRead≤RcvBuffer
$$ -
而TCP报文中的receive window,则表示了接收方的缓冲区还剩了多少空间:
$$
rwnd=RcvBuffer?[LastByteRcvd?LastByteRead]
$$? 如果我妹搞错的话,应该就像这样:
?
-
而发送端则需要保证:
$$
LastByteSent?LastByteAcked≤rwnd
$$ -
最后讨论一个问题:
如果在某次通讯中,接收方给发送方告知,rwnd=0,那sender如何重启发送呢?
【答】: 当rwnd=0时,sender会有两种情况继续发送数据:
- 紧急数据( urgent data )
- 试探性的发送一个字节的数据过去,看receiver返回的ACK中的rwnd是多少
-
TCP连接管理(TCP Connection Management)
-
TCP两次握手
【为什么TCP两次握手不行的情况】
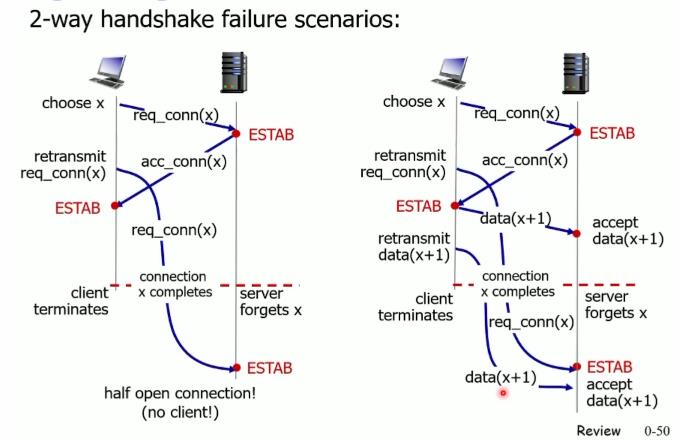
归根结底,就是你不知道对面是否建立连接了,没有确认这一个部分
-
TCP三次握手
-
第一步:client host sends TCP SYN segment to server
- 发送一个初始的序列号
- 没有带数据
- 第二步:server host receives SYN,replies with SYNACK segment
- 服务器创建buffers
- 发送自己的初始序列号
- 如果没有什么反馈,就重传,如果重传多次(一般三次)害不理我,就毁掉套接字
- 第三步: client receives SYNACK ,replies with ACK segment
- 可带数据也可以不带数据
-
过程
?
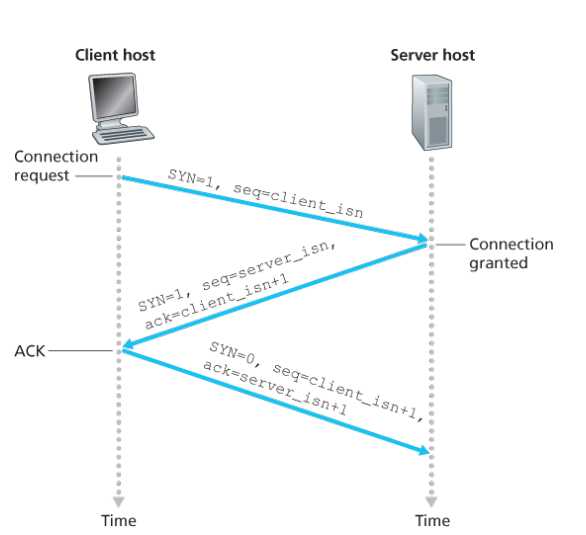
【问题】
-
为什么服务器返回的ack=client_isn+1?
【答】:因为当SYNbit=1时,TCP默认为收到一个字节
-
为什么要用随机序列号?
> 【答】: TCP是一个有状态协议,A与B之间有一个TCP连接,C想搞破坏,于是想伪造A的IP给B发一个Reset,要分两种情景: > > **情景一:C处于A与B之间流量的路径上** > C可以捕获到A、B的IP包,伪造是小菜一碟,比如大防火墙reset用户连接 > > **情景二:C不在A与B之间流量的路径上** > C可以在世界的任何角落,伪造一个合法TCP报文,最关键是TCP字段里的sequence number 、acknowledged number,只要这两项位于接收者滑动窗口内,就是合法的,对方可以接收并Reset A、B之间的TCP连接。 > > 而TCP握手采用随机序列号(**不完全随机,而是随着时间流逝而线性增长,到了2^32尽头再回滚**),为的就是让攻击者更难以猜测sequence number,因为伪造的sequence number不在合法范围内,而被接收方丢弃,增加安全性。 -
-
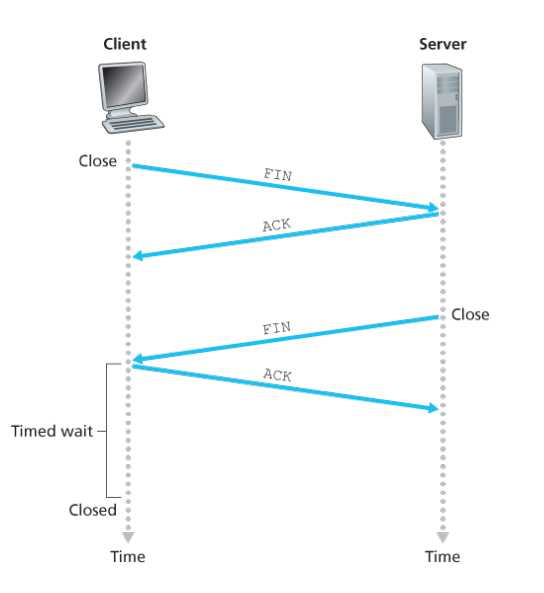
TCP四次挥手
-
第一步:client end system sends TCP FIN control segment to server
-
第二步:server receives FIN ,replies with ACK ,Closes connection ,sends FIN
-
第三步: client receives FIN ,replies with ACK
-
第四步: server,receives ACK ,connection closed
-
注意下图,一个是关闭时间,貌似和书上上面的图不太一样,但是应该是server等到接收到最后一个ack再close,client等到wait完了之后再close
还有一个就是server在发送FIN之前依然能够接收数据的
-
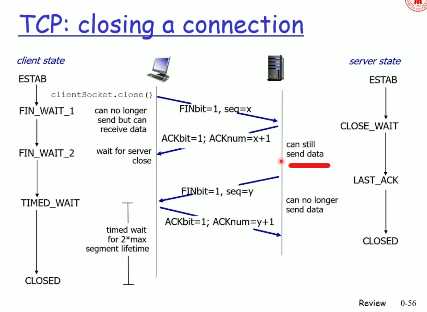
? 【同样还有一个问题,为什么要等待两个segment 的life time?】
> 这最主要是因为两个理由:
>
> 1、为了保证客户端发送的最后一个ACK报文段能够到达服务器。因为这个ACK有可能丢失,从而导致处在LAST-ACK状态的服务器收不到对FIN-ACK的确认报文。服务器会超时重传这个FIN-ACK,接着客户端再重传一次确认,重新启动时间等待计时器。最后客户端和服务器都能正常的关闭。假设客户端不等待2MSL,而是在发送完ACK之后直接释放关闭,一但这个ACK丢失的话,服务器就无法正常的进入关闭连接状态。
>
> 2、他还可以防止已失效的报文段。客户端在发送最后一个ACK之后,再经过经过2MSL,就可以使本链接持续时间内所产生的所有报文段都从网络中消失。从保证在关闭连接后不会有还在网络中滞留的报文段去骚扰服务器。
>
> 注意:在服务器发送了FIN-ACK之后,会立即启动超时重传计时器。客户端在发送最后一个ACK之后会立即启动时间等待计时器。
-
上课讲的一道题

TCP拥塞控制( Principles of Congestion Control)
-
发生拥塞的几种情况
-
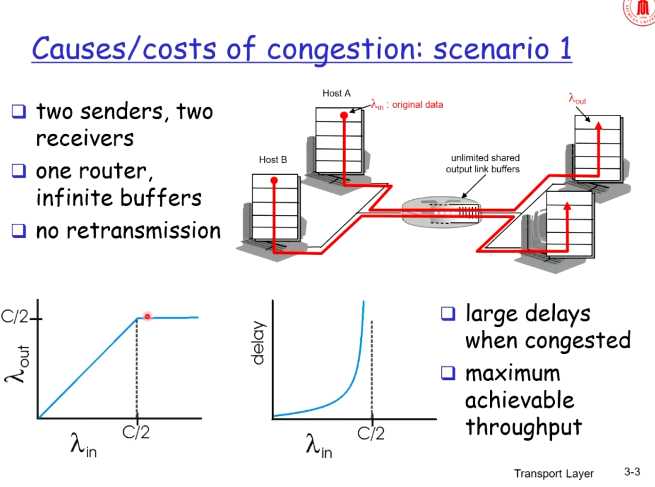
【场景一】
-
假设路由器buffer无限
-
因为路由器buffer无限,所以不会有数据丢失,所以在C/2之前,λ(in)和λ(out)程线性
-
到C/2之后,之前学过,
$$
queuing delay=La/R
$$
所以queuing delay会很大
-
-
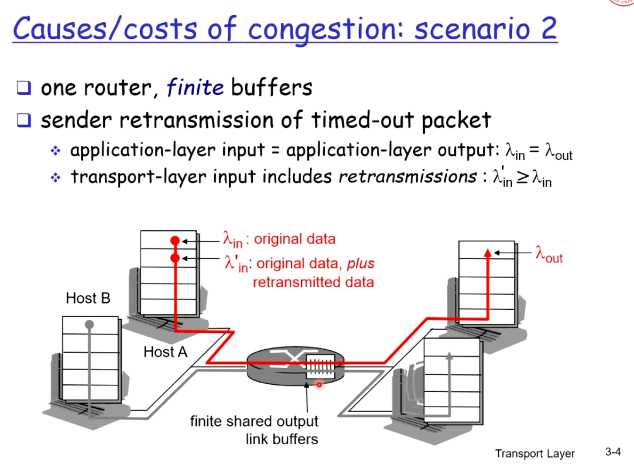
【场景二】
-
路由器buffer变成了有限的
-
所以有TCP的重传,所以真实进入网络的是λ‘
-
我们继续分两种情况讨论
-
第一种情况,理想情况,主机能够知道路由器的buffer情况 ,就和上面场景一差不多
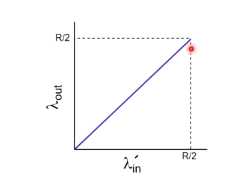
-
第二种情况,知道包丢失了,TCP才重传,不会出现早熟
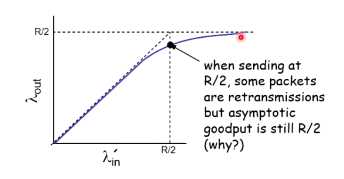
在接近R/2时,就可能会出现分组丢失了,所以out就开始大于in
-
第三种情况,真实情况,也可能会出现早熟
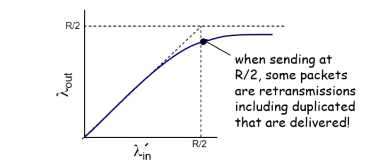
-
-
能得到拥塞的另外的一些坏处:
- 会导致更多的、不必要的重传
-
-
【场景三】
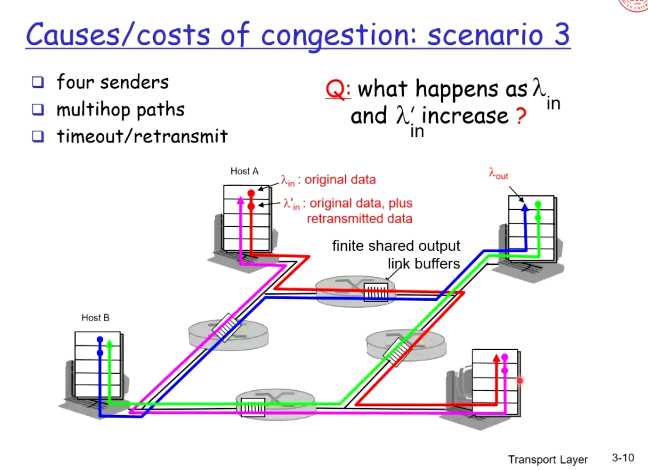
-
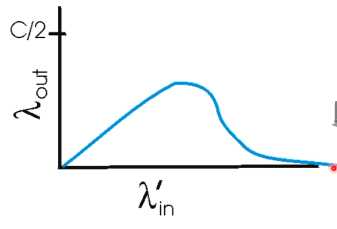
-
拥塞的其他危害:
下游路由器丢弃分组,导致上游白发送了,浪费了带宽
-
-
-
拥塞控制的方法:
-
端到端控制,(end-end congestion control)
通过端系统对丢包,重发的观察,猜测中间节点的情况,进行控制
TCP采用的这种控制方法
-
网络辅助控制(network-assisted congestion control)
路由器会给终端以反馈
single bit indicating congestion (SNA, DECbit , TCP/IP ECN ATM)
explicit rate sender
-
-
拥塞控制的例子
- ATM。。。TMD 不听了
书上的TCP拥塞控制
-
没听课了,看下书就是了
-
【拥塞控制和流量控制的区别】
流量控制:如果发送方把数据发送得过快,接收方可能会来不及接收,这就会造成数据的丢失。
TCP的流量控制是利用滑动窗口机制实现的,接收方在返回的数据中会包含自己的接收窗口的大小,以控制发送方的数据发送。
拥塞控制:拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。
两者的区别:流量控制是为了预防拥塞。如:在马路上行车,交警跟红绿灯是流量控制,当发生拥塞时,如何进行疏散,是拥塞控制。流量控制指点对点通信量的控制。而拥塞控制是全局性的,涉及到所有的主机和降低网络性能的因素。
-
TCP流量控制的方法:
have eachsenderlimit the rate at which it sends traffic into itsconnection as a function of perceived network congestion.这样会带来三个问题:
- First, how does a TCP sender limit the rate at which it sends traffic into its connection? (如何限制速率)
- Second, how does a TCP sender perceive that there is congestion on the
path between itself and the destination?发送方如何感知到拥塞 - third, what algorithm should the sender use to change its send rate as a function of perceived end-to-end congestion?如何通过感知到的拥塞来改变发送
-
问题一:如何限制速率
以上是关于计网自顶向下--深入理解传输层的主要内容,如果未能解决你的问题,请参考以下文章