pandas -- numpy++
Posted rowry
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas -- numpy++相关的知识,希望对你有一定的参考价值。
为什么要学习pandas
数据处理基本就是使用pandas, pandas就是numpy++
pandas是一个强大的数据分析工具集
1. numpy能够帮我们处理数值型数据,但是这还不够,很多时候我们除了数值之外,还有字符串,时间序列等
(1) 我们通过俺从获取到了存储在数据库中的数据
(2) youtube的例子中除了数值之外还有国家的信息,视频的分类信息,标题信息等
2. numpy可以帮助我们处理数值,但是pandas除了处理数值(基于numpy),还能帮我处理其他类型的数据
pandas的常用数据类型
(1) Series (2) Dataframe
1. 要想学好Pandas,前提是要对pandas的数据结构有所了解.
2. pandas中有两个主要的数据结构: Series和DataFrame
(1) Series是一维的数据结构(带标签(索引)的数组)
(2) DataFrame是二维的数据结构(Series容器)
Series
Series是一种类似于一维数组的对象,由一组数据(各种numpy的数据类型)以及一组与之对应的索引(数据标签)组成
(1) 类似一维数组的对象
(2) 由数据和索引组成
1) 索引(index)在左,数据(values)在右
2) 索引是自动创建的

Series创建
1. Pandas的Series类对的构造方法:
class pandas.Series(data=None,index=None,dtype=None,copy=False,...)
(1) data: 传入的数据,可以是ndarray,list等序列,还可以通过字典来创建
(2) index: 索引序列,必须是唯一的,且与数据的长度相同. 如果没有传入索引参数,则默认会自动创建一个从0~N的整数索引
(3) dtype: 数据类型
(4) copy: 是否复制数据,默认为False
通过序列来创建Series对象
# code01_通过序列创建Series.py
import pandas as pd
# pd.Series()的构造方法如下
# _init__(self, data: Any = None, index: Any = None, dtype: Any = None, name: Any = None, copy: Any = False, fastpath: bool = False) -> Any
ser_obj01 = pd.Series([1, 2, 3, 4, 5, 6]) # 通过列表创建Series对象
print(ser_obj01)
print(‘-‘ * 30)
ser_obj02 = pd.Series(range(1, 7), [x for x in "abcdef"]) # 按索引(标签)也给指定了
print(ser_obj02)
通过字典来创建Series对象
# code02_通过字典创建Series.py
import pandas as pd
# 字典创建Series, key就是索引, value就是value => 刚好一一对应
temp_dic = dict(name="张三", age=23, job="程序员")
ser_obj01 = pd.Series(temp_dic)
print(ser_obj01)
属性 index 和 values
index 是 Index类的一个对象
values是ndarray
# code03_属性index和values.py
import pandas as pd
# 字典创建Series, key就是索引, value就是value => 刚好一一对应
temp_dic = dict(name="张三", age=23, job="程序员")
ser_obj01 = pd.Series(temp_dic)
# 获得 index 和 values两个属性
ser_index = ser_obj01.index
ser_values = ser_obj01.values
print(type(ser_index)) # <class ‘pandas.core.indexes.base.Index‘>
print(ser_index) # 输出index属性
print(type(ser_values)) # <class ‘numpy.ndarray‘>
print(ser_values) # 输出values属性
print(‘-‘ * 30)
# 可以直接通过索引值来获取属性
print("ser_obj01["name"]:", ser_obj01["name"])
print("ser_obj01["age"]:", ser_obj01["age"])
print("ser_obj01["job"]:", ser_obj01["job"])
# 即使Series进行了运算,运算后的values依然和index一一对应
print(‘-‘ * 30)
print(ser_obj01 * 3) # 让每个values都*3
DataFrame
1. DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同类型的值.
2. DataFrame既有行索引也有列索引,它可以被看做是由Series组成的字典(共用一个索引),数据是以二维结构存放的.
(1) 类似多维数组/表格数据(如 excel,R中的data.frame)
(2) 同一列数据必须是相同的类型(相当于一竖列就是一个Series)
(3) 索引包括列索引和行索引
3. Pandas的DataFrame类对象的构造方法:
pands.DataFrame(data=None,index=Noen,columns=None,dtype=None,copy=False)
(1) index: 行标签,如果没有传入索引参数,则默认创建一个从0~N的整数索引 => 0轴,axis=0
(2) columns: 列标签,如果没有传入索引参数,则默认创建一个0~N的整数索引 => 1轴,axis=1
(3) data: 这里传入的data是二维的序列
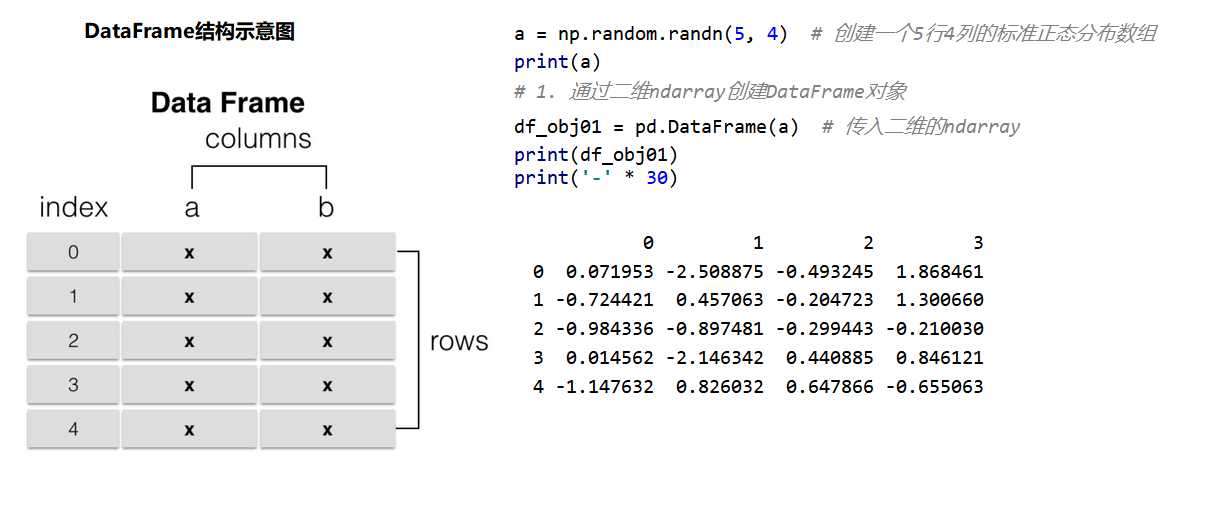
通过二维序列创建DataFrame
# code05_通过二维序列创建DataFrame.py
import numpy as np
import pandas as pd
a = np.random.randn(5, 4) # 创建一个5行4列的标准正态分布数组
print(a)
print(‘-‘ * 30)
# pd.DataFrame()
# __init__(self, data=None, index=None, columns=None, dtype=None, copy=False)
# 1. 通过二维ndarray创建DataFrame对象
df_obj01 = pd.DataFrame(a) # 传入二维的ndarray
print(df_obj01)
print(‘-‘ * 30)
# 2. 其实通过二维序列也是一样的道理
# 这里同时传入行索引和列索引
index = list("abcde")
columns = ["No{}".format(i) for i in range(1, 5)]
b = np.arange(20).reshape(5, 4)
df_obj02 = pd.DataFrame(b, index=index, columns=columns) # 传入二维的ndarray
print(df_obj02)
print(‘-‘ * 30)
通过字典创建DataFrame
# code06_通过字典创建DataFrame.py
import numpy as np
import pandas as pd
d1 = dict(name=["张三", "李四", "王五", "赵六"], age=[23, 24, 25, 26], score=[93, 94, 95, 96])
df_obj01 = pd.DataFrame(d1) # 传入了字典,其实也就相当于指定指定了columns
print(df_obj01)
通过列索引获取列数据(Series类型)
(1) df_obj.列索引的名称 (2) df_obj[列索引的名称]
一般推荐使用后者,使用索引的方式而不是使用属性的方式来获取列数据
# code07_DataFrame通过列索引获得列数据.py
import numpy as np
import pandas as pd
# 一列数据就是一个Series (1) 列索引位置 (2) 列索引名称
d1 = dict(name=["张三", "李四", "王五", "赵六"], age=[23, 24, 25, 26], score=[93, 94, 95, 96])
df_obj01 = pd.DataFrame(d1) # 传入了字典,其实也就相当于指定指定了columns
element01 = df_obj01["name"] # 通过列索引名称获得一列数据
print(element01)
print(type(element01)) # <class ‘pandas.core.series.Series‘>
print(‘-‘ * 30)
element02 = df_obj01.name # 通过列索引这个属性获得一列数据
print(element02)
print(type(element02)) # <class ‘pandas.core.series.Series‘>
增加列数据和删除列数据
增加一列相当于增加了一个字段
1. DataFrame增加列数据类似于Python给字典添加一个键值对,如: df_obj[‘No4‘]=[‘g‘,‘h‘]
2. DataFrame删除一列列数据,使用del关键字实现,如: del df_obj[‘No3‘]
# code08_DataFrame增加列和删除列.py
import numpy as np
import pandas as pd
d1 = dict(name=["张三", "李四", "王五", "赵六"], age=[23, 24, 25, 26], score=[96, 95, 94, 93])
df01 = pd.DataFrame(d1)
print(df01)
print(‘-‘ * 30)
# 1. 给DataFrame增加列,操作和Python给字典增加新的键值对一致
df01[‘gender‘] = [‘男‘, ‘男‘, ‘女‘, ‘女‘] # 增加一列属性
df01[‘school‘] = [‘广西大学‘, ‘广东工业大学‘, ‘广西师范大学‘, ‘广东财经大学‘]
print(df01)
print(‘-‘ * 30)
# 2. 删除DataFrame中的列, 使用del关键字 del df[‘列索引名称‘]
del df01[‘gender‘] # 删除性别属性
print(df01)
print(‘-‘ * 30)
DataFrame基本使用
1. DataFrame的基础属性
(1) df.shape # 行数 列数
(2) df.dtypes # 列数据类型 (注意,是dtypes不是dtype)
(3) df.ndim # 数据维度
(4) df.index # 行索引
(5) df.columns # 列索引
(6) df.values # 对象值,二维ndarray数组
2. DataFrame整体情况查询
(1) df.head(3) # 显示头部几行,默认5行
(2) df.tail(3) # 显示末尾几行,默认5行
(3) df.info() # 相关信息查看: 行数,列数,列非空值个数,列类型,内存占用
(4) df.describe() # 快速综合统计结果: 计数,均值,标准差,最大值,四分位数,最小值
# code09_DataFrame基本使用.py
import numpy as np
import pandas as pd
d1 = dict(name=["张三", "李四", "王五", "赵六"], age=[23, 24, 25, 26], score=[93, 94, 95, 96])
df = pd.DataFrame(d1)
# DataFrame的基本属性
# (1) df.shape
print("df.shape: ", df.shape)
print(‘-‘ * 30)
# (2) df.dtypes
print("df.dtypes: ", df.dtypes)
print(‘-‘ * 30)
# (3) df.ndmin
print("df.ndim: ", df.ndim)
print(‘-‘ * 30)
# (4) df.index
print("df.index: ", df.index)
print(‘-‘ * 30)
# (5) df.columns
print("df.columns: ", df.columns)
print(‘-‘ * 30)
# (6) df.values
print("df.values: ", df.values)
print(‘-‘ * 30)
# 2. DataFrame整体情况查询
# (1) df.head() 显示头部几行,默认前5行
print("df.head(2):", df.head(2))
print(‘-‘ * 30)
# (2) df.tail() 显示头部几行,默认前5行
print("df.tail(2):", df.tail(2))
print(‘-‘ * 30)
# (3) df.info() 查看信息
print("df.info():", df.info())
print(‘-‘ * 30)
# (4) df.describe() 快速综合统计结果
print("df.describe():", df.describe())
print(‘-‘ * 30)
# code10_统计狗的名字使用情况.py
import numpy as np
import pandas as pd
# pd.read_csv() => 读出csv文件并转换为df对象
df = pd.read_csv(r"./dogNames.csv")
# print(df)
# print(df.info()) => df.info() 快速查看一下统计信息
# DataFrame中的排序方法
# pd.DataFrame.sort_values(by=[‘列索引名称1‘,‘列索引名称2‘,...]) DataFrame要指定排序的列索引
df = df.sort_values(by=["Count_AnimalName"],ascending=False)
print(df)
print(‘-‘ * 30)
# 查看前10个大的
print(type(df.tail(10))) # <class ‘pandas.core.frame.DataFrame‘>
print(df.head(10)) # 查看前10个最大的
Pandas的索引操作
索引对象
1. Pandas中的索引都是Index类对象,又称索引对象,该对象是不可以进行修改的,以保证数据安全.
(1) 如果修改索引值会报错 => ser.index[‘a‘] = 2 # 这个是错的,索引不能修改
2. Index类的不可变性是非常重要的,正因为如此,多个数据结构之间才能够安全的共享Index类对象
ser01 = pd.Series(range(3),index=[a,b,c])
ser02 = pd.Series(range(8),index=ser01.index) # ser02可以直接使用ser01的索引
print(ser01.index is ser02.index)
3. Index类对象是可迭代的,可实现的很多操作:
(1) for x in ser.index: # 迭代遍历
(2) type(ser.index) # 查看类型
(3) list(ser.index) # 转换为 list
(4) len(ser.index) # 获取长度
Series索引
1. Series有关索引的用法类似于Numpy数组中索引,只不过Series的索引不只是整数.如果要获取某个数据的值,可以
(1) 索引的位置来获取值
(2) 索引的名称来获取值
2. Series的切片操作
(1) 索引的位置来切片 [) => ser_obj[2:4]
(2) 索引的名称来切片 [] => ser_obj[‘c‘:‘e‘]
3. Series不连续索引
不连续只要传入这个不连续索引的值的序列即可 ser_obj[[不连续索引序列]]
(1) 索引的位置 ser_obj[[0,2,4]]
(2) 索引的名称 ser_obj[[‘a‘,‘c‘,‘d‘]]
4. 布尔型索引
使用布尔型也是进行布尔运算,然后会的返回的新的布尔数组
ser_bool = ser_obj>2 # 获得布尔数组
ser_obj[ser_bool] # 获得结果为True的数据
# code04_Series的索引操作.py
import pandas as pd
ser_obj = pd.Series(range(1, 6), [chr(ord(‘a‘) + x) for x in range(5)])
print(ser_obj)
print(‘-‘ * 30)
# 1. 使用索引获得值 (1)索引位置 (2) 索引名称
print("ser_obj[2]:", ser_obj[2]) # 使用索引位置获取值
print("ser_obj[‘c‘]:", ser_obj[‘c‘]) # 使用索引名称获取值
print(‘-‘ * 30)
# 2. Series切片
print("ser_obj[2:4]:
", ser_obj[2:4]) # 通过索引位置切片 [)
print("ser_obj[‘c‘:‘e‘]:
", ser_obj[‘c‘:‘e‘]) # 通过索引名称切片 []
print(‘-‘ * 30)
# 3. Series不连续索引
print("ser_obj[[0, 2, 4]]:
", ser_obj[[0, 2, 4]]) # 通过索引位置
print("ser_obj[[‘a‘, ‘c‘, ‘d‘]]:
", ser_obj[[‘a‘, ‘c‘, ‘d‘]]) # 通过索引名称
print(‘-‘ * 30)
# 4. 布尔索引
ser_bool = ser_obj > 2 # 获得布尔值数组
print(ser_obj[ser_bool]) # 输出大于2的值
# print(ser_obj[ser_obj>2])
DataFrame索引
1. df[ ]--选择列,整数可以选择行,但是不能单独选择,要用切片的方式如df[:2]
(1) df[["colums1","columns2",......]] 通过这样来选择列
(2) df[index1:index2] 通过这个才可以对行进行切片
(3) df[["colums1","columns2",......]] 切片的同时是选择行
2. 布尔索引 df[布尔索引]
df[(df["Row_Labels"].str.len()>4) & (df["Count_AnimalName"]>700)]
(1) 有两个连接符 &,|
(2) 两个不同条件之间需要使用() 括起来
# code12_DataFrame索引使用.py
import numpy as np
import pandas as pd
# pd.read_csv() => 读出csv文件并转换为df对象
df = pd.read_csv(r"./dogNames.csv")
print(df.info())
print(‘-‘ * 30)
# 1. df[ ]--选择列,整数可以选择行,但是不能单独选择,要用切片的方式如df[:2]
# (1) df[["colums1","columns2",......]] 通过这样来选择列
print(df[["Row_Labels", "Count_AnimalName"]]) # 选择指定的列输出
print(‘-‘ * 30)
# (2) df[index1:index2] 通过这个才可以对行进行切片
print(df[:20]) # 输出前20行 (只能切片,不能进行单独的选择)
print(‘-‘ * 30)
# (3) df[["colums1","columns2",......]] 切片的同时是选择行
print(df[:20]["Row_Labels"]) # 切片同时选择指定的列
print(‘-‘ * 30)
# 2. 布尔索引 df[布尔索引]
# (1) 连接符 & | (2) 不同条件之间要使用括号括起来
print(df[(df["Row_Labels"].str.len() > 4) & (df["Count_AnimalName"] > 700)])
print(‘-‘ * 30)
高级索引: 标签,位置和混合
(1) loc标签索引 (2) iloc位置索引
使用loc,iloc,那么DataFrame的切片操作就和ndarry的二维数组切片一致
1. 虽然DataFrame操作索引能够满足基本数据查看请求,但是仍然不够灵活. 为此,pandas提供了loc和iloc.
2. loc: 基于标签索引(索引名称),用于按标签选取数据. df.loc[行,列]
3. iloc: 基于标签位置,按位置选取数据 df.iloc[行,列]
4. 注意:
(1) 位置的切片是不包含末尾,而标签切片是包含末尾的
(2) 花式索引与ndarray不太一致,ndarray花式索引取出是一个一个值,但是DataFrame取出是一行一行
# code13_loc和iloc.py
import numpy as np
import pandas as pd
# 通过df.loc[行,列] df.iloc[行,列] 实现了DataFrame和numpy二维数组切片操作的一致
arr = np.arange(16).reshape(4, 4)
df = pd.DataFrame(arr, columns=list("abcd"))
print(df)
print(‘-‘ * 30)
# 1. 使用df.loc[] 按照索引标签名字
print(df.loc[:, ["c", "a"]]) # 全部行的c,a列
print(‘-‘ * 30)
print(df.loc[[0, 2], [‘a‘, ‘c‘]]) # 要注意DataFrame的花式索引与ndarray有点不同
print(‘-‘ * 30)
# 2. df.iloc[] 按照索引位置
print(df.iloc[:, [2, 0]]) # 全部行的c,a列
print(‘-‘ * 30)
print(df.iloc[[0, 2], [0, 2]])
print(‘-‘ * 30)
Pandas的对齐运算
Pandas的函数应用
apply和applymap
1. 可以直接使用numpy的函数
排序
(1) ser.sort_index() df.sort_index()
(2) ser.sort_values() df.sort_values(by=[])
1. 索引排序
Pandas中按索引排序使用的是sort_index(),该方法可以用行索引或者列索引进行排序
sort_index(axis=0,level=None,ascending=True,inplace=False,kind=‘quicksort‘...)
(1) axis: 轴索引(排序的方向),0表示index(按行),1表示columns(按列),默认按index
(2) level: 若不为None,则对指定索引级别的值进行排序
(3) ascending: 是否升序排序,默认为True,表示升序
(4) inpalce: 默认为False,表示对数据表进行排序,返回一个新的排序数组
(5) kind: 选择排序算法,默认为quicksort
2. 按值排序
sort_values(by,axis=0,ascending=True,inplace=False,kind=‘quicksort‘,na_position=‘last‘)
(1) by: 表示排序的列
(2) na_position: 参数只有两个值 first,last.若为first,则会将NaN值放在开头. 默认NaN值是放在末尾
# code11_pandas数据排序.py
import numpy as np
import pandas as pd
# 1. 按索引排序
# sort_index(axis=0,level=None,ascending=True,inplace=False,kind=‘quicksort‘...)
ser = pd.Series(range(10, 15), index=[5, 3, 1, 3, 2]) # 这里索引标签是可以同名的
print(ser)
print(‘-‘ * 30)
ser.sort_index(inplace=True) # 按索引值升序排序
print(ser)
print(‘-‘ * 30)
ser.sort_index(ascending=False, inplace=True) # 按索引值降序排序
print(ser)
print(‘-‘ * 30)
df = pd.DataFrame(np.arange(9).reshape(3, 3), index=[4, 3, 5])
print(df)
print(‘-‘ * 30)
df = df.sort_index() # 默认按index升序排序,返回一个新的数组
print(df)
print(‘-‘ * 30)
# 2. 按值排序
# sort_values(by,axis=0,ascending=True,inplace=False,kind=‘quicksort‘,na_position=‘last‘)
ser = pd.Series([4, np.nan, 6, np.nan, -3, 2])
print(ser)
print(‘-‘ * 30)
ser.sort_values(inplace=True) # 默认NaN在最后,升序排序
print(ser)
print(‘-‘ * 30)
d1 = dict(No1=[0.4, -0.1, -0.3, 0.0],
No2=[0.2, 0.6, -0.1, -0.7],
No3=[0.8, 0.6, -0.5, 0.1])
df = pd.DataFrame(d1)
print(df)
print(‘-‘ * 30)
df.sort_values(by=["No1","No2","No3"],inplace=True) # 按照关键字 No1 No2 No3 进行排序
print(df)
print(‘-‘ * 30)
处理缺失数据
1. 一般空值使用None表示,缺失值使用NaN表示.
2. Pandas中提供了一些用于检查或处理空值(None)和缺失值(NaN)的函数.
(1) pd.isnull() / pd.notnull() 判断数据集合中是否存在空值和缺失值
(2) pd.dropna() 和 pd.fillna() 对空值和缺失值进行删除和填充
3. pd.isnull(obj)/pd.notnull(obj)
4. pd.dropna(axis=0,how=‘any‘,thresh=None,subset=None,inplace=False)
(1) axis: 确定过滤行或列
1) 0为index,删除包含缺失值的行,默认为0
2) 1为columns,删除包含缺失值的列
(2) how: 确定过滤的标准,取值可以为
1) any: 默认值,如果存在NaN值,则删除该行或该列
2) all: 如果所有值都是NaN值,则删除该行或该列
(3) thresh: 表示有效数据量的最小要求. 若传入了2,则是要求该行或该列至少有两个非NaN值将其保留
(4) subset: 表示在特定的子集中寻找NaN值
(5) inplace: 表示是否在原数据上操作
5. pd.fillna(value=None,method=None,limit=None.....)
(1) value: 用于填充的数据
(2) method: 表示填充方式,默认值为None
1) pad/ffill: 将最后一个有效的数据向后传播,也就是说缺失值前面的一个值代替缺失值
2) backfill/bfill: 将最后一个有效的数据向前传播,也就是说用缺失值后面的一个值代替缺失值
注意: method参数和value参数只能二者选其一,不同同时使用
(3) limit: 可以连续填充的最大数量,默认为None
4. 关于0的处理 => df[df==0]=np.nan
(1) 注意: 不是每次都需要处理0,但是像求平均数这类操作,0是会参与的,视情况处理了
# code14_pandas处理缺失值.py
import pandas as pd
import numpy as np
# 1. 判断是否为缺失值
# pd.isnull() pd.notnull()
ser = pd.Series([1, None, np.nan])
print(ser)
print(‘-‘ * 30)
print(pd.isnull(ser)) # 检查是否为空值或缺失值
print(‘-‘ * 30)
print(pd.notnull(ser)) # 检查是否不是空值或缺失值
print(‘-‘ * 30)
# 3. 删除含有含有缺失值/空值的行或列
# pd.dropna(axis=0,how=‘any‘,thresh=None,subset=None,inplace=False)
d1 = dict(类别=[‘小说‘, ‘散文随笔‘, ‘青春文学‘, ‘传记‘],
书名=[np.nan, ‘《皮囊》‘, ‘《旅程结束时》‘, ‘《老舍自传》‘],
作者=[‘老舍‘, None, ‘张其鑫‘, ‘老舍‘])
df = pd.DataFrame(d1)
print(df)
print(‘-‘ * 30)
drop_df = df.dropna(inplace=False) # 默认是删除有缺失值的行
print(drop_df)
print(‘-‘ * 30)
# 3. 填充缺失值/空值
# pd.fillna(value=None,method=None,limit=None.....)
d2 = dict(A=[1, 2, 3, np.nan],
B=[np.nan, 4, np.nan, 6],
C=[‘a‘, 7, 8, 9],
D=[np.nan, 2, 3, np.nan])
df = pd.DataFrame(d2)
print(df)
print(‘-‘ * 30)
# (1) 全部缺失值都才采用一个value来填充
fill_value_df = df.fillna(value=66.0) # 使用66.0替换缺失值
print(fill_value_df)
print(‘-‘ * 30)
# (2) 指定的列使用指定的value来填充
fill_value = dict(A=4.0, B=5.0, C=6.0, D=7.0)
fill_value_df = df.fillna(value=fill_value) # 给value传入字典,可以实现给指定的列填充指定的数值
print(fill_value_df)
print(‘-‘ * 30)
# (3) ffill : 同一列,NaN上面的值来填充
ffill_df = df.fillna(method=‘ffill‘)
print(ffill_df)
print(‘-‘*30)
# (3) bfill : 同一列,NaN下面的值来填充
bfill_df = df.fillna(method=‘bfill‘)
print(bfill_df)
print(‘-‘*30)
Pandas字符串方法
1. pd.Series.str 这是Series的一个属性,里面有字符串方法
2. 内置字符串方法优势在于矢量化,而无需循环(如果使用使用普通Python字符串的话)
df["Row_Labels"].str.len() > 4 # 该列字符串长度大于4的
ser.str.lower() # 把该列字符串都转为小写字母

Pandas的层级索引
Pandas统计计算和描述
1. 数组化处理 => list(ndarray) ndarray.tolist()
比如像set() 使用去重方式, ndarray报错 unhashable
2. 去重处理
(1) set(list())
(2) Series.unique()
3. 多维数组转为一维数组
(1) Python循环转化 [j for i in L for j in i] # 二维list为例子
(2) ndarray().flatten() / ndarray.reshape(-1)
4. 获得Series和DataFrame的行数了列数
(1) Series.shape[0] DataFrame.shape[1]
(2) len(Series)
5. 对Series/ DataFrame进行排序
sort_values, sort_index
常用统计计算

常用统计描述
1. 如果希望一次性输出多个统计指标,比如平均值,最大值,最小值,求和等,则可以调用describe(),而不用再单独地逐个调用相应的统计方法.
2. describe(percentiles=None,include=None,exclude=None)
(1) percentiles: 输出中包含的百分数,位于[0,1]之间,如果不设置该参数,则默认为[0.25,0.5,0.75],返回25%,50%,75%分位数.
(2) include,exclude: 指定返回结果的形式
# code15_电影评分信息.py
import numpy as np
import pandas as pd
df = pd.read_csv(r"./IMDB-Movie-Data.csv") # 读入csv文件
print(df.info())
print("-" * 30)
# 1. 评分的平均分 mean(Rating)
rating_mean = df["Rating"].mean() # 选中对应的列,然后进行求平均计算
print("df["Rating"].mean():", rating_mean)
print("-" * 30)
# 2. 导演人数 len(set(Director)) / unique()
# nums_director = len(set(df["Director"].tolist()))
nums_director = len(df["Director"].unique()) # 使用 df[列属性].unique() <=> set(df[列属性].tolist())
print("len(df["Director"].unique()):", len(df["Director"].unique()))
print("-" * 30)
# 3. 演员人数 len(set(Actors)) / unique()
# 演员人数有点特殊,因为演员是一行有好几个言演员
temp_actors_list = df["Actors"].str.split(", ").tolist() # 分隔逗号, 然后称为一个二维数组
actor_list = [j for i in temp_actors_list for j in i] # 把二维的列表平铺为一维的 => Python普通做法
# 转为numpy对象,进行矢量化处理 => reshape(-1) flatten() (记得转为list类型)
# 这个思路可以,但是列表中的每个元素都是list类型的,并不能展开,所以自己两重循环
actor_num = len(set(actor_list)) # 统计演员人数
print("len(set(actor_list)):", actor_num)
# TypeError: unhashable type: ‘list‘ 注意不能直接对numpy进行set() => list(ndarray) ndarray.tolist()
print(‘-‘ * 30)
# 4. 电影时长的最大最小值
max_runtime = df[["Runtime (Minutes)"]].max() # 获得最大值
max_runtime_index = df["Runtime (Minutes)"].argmax() # 获取最大值索引
min_runtime = df["Runtime (Minutes)"].min()
min_runtime_index = df["Runtime (Minutes)"].argmin()
median_runtime = df["Runtime (Minutes)"].median()
print("df["Runtime (Minutes)"].max():", max_runtime)
print("df["Runtime (Minutes)"].argmax():", max_runtime_index)
print("df["Runtime (Minutes)"].min():", min_runtime)
print("df["Runtime (Minutes)"].argmin():", min_runtime_index)
print("df["Runtime (Minutes)"].median():", median_runtime)
# code16_电影时长和评分分布.py
import numpy as np
import pandas as pd
# import matplotlib.pyplot as plt
from matplotlib import pyplot as plt
file_path = r"./IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
print(df.info()) # 查看资料信息
print(‘-‘ * 30)
print(df.head(1)) # 查看你第一行数据
print(‘-‘ * 30)
# 任务: rating,runtime分布情况
# 图形: 直方图
# 准备数据
runtime_data = df["Runtime (Minutes)"].values
print(type(df["Runtime (Minutes)"])) # <class ‘pandas.core.series.Series‘>
print(type(df["Runtime (Minutes)"].values)) # <class ‘numpy.ndarray‘>
# 计算组数(例如5分钟作为组距)
runtime_max = runtime_data.max()
runtime_min = runtime_data.min()
runtime_bins = (runtime_max - runtime_min) // 5
# 画图
plt.figure(figsize=(20, 8 * 3), dpi=80)
plt.subplot(3, 1, 1)
plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 用来正常显示中文标签
plt.rcParams[‘axes.unicode_minus‘] = False # 用来正常显示负号
plt.hist(runtime_data, bins=runtime_bins)
# 设置刻度 => 最小值,最大值+步长,步长
plt.xticks(range(runtime_min, runtime_max + 5, 5))
plt.title("电影时长分布情况")
print(‘-‘ * 30)
# 下面同理绘制评分的分布图
plt.subplot(3, 1, 2)
rating_data = df["Rating"].values
rating_max, rating_min = rating_data.max(), rating_data.min()
rating_bins = (rating_max - rating_min) // 0.5 # 评分的组距为0.5(不同的属性应该有不同的属性)
# plt.hist(np.arange(rating_min, rating_max + 0.5, 0.5)) # 这个是典型的错误,因为range里面必须全部都是int
# 现在为了取到0.5步长,不能使用range() 只能自己手动操作
rating_x = []
i = rating_min
while i <= rating_max + 0.5:
rating_x.append(i)
i += 0.5
plt.hist(rating_data, bins=int(rating_bins))
plt.xticks(rating_x)
plt.title("评分分布情况")
plt.subplot(3, 1, 3)
plt.title("评分分布情况(调整组距)") # 前面人数较少的组可以合并 => bins传入一个数组
# 1.9-3.5 这个人数少的其实可以设置为一组
rating_bins = [rating_min, rating_min + 1.6]
# max(9.0) min(1.9) => 整个的距离是 7.1, 现在在减去1.6,剩余5.5的距离,然后这个5.5按0.5的组距在划分
x = rating_bins[-1]
while x <= rating_max:
x += 0.5
rating_bins.append(x) # 注意列表的append()和+的区别
plt.hist(rating_data, bins=rating_bins)
plt.xticks(rating_bins)
plt.show()
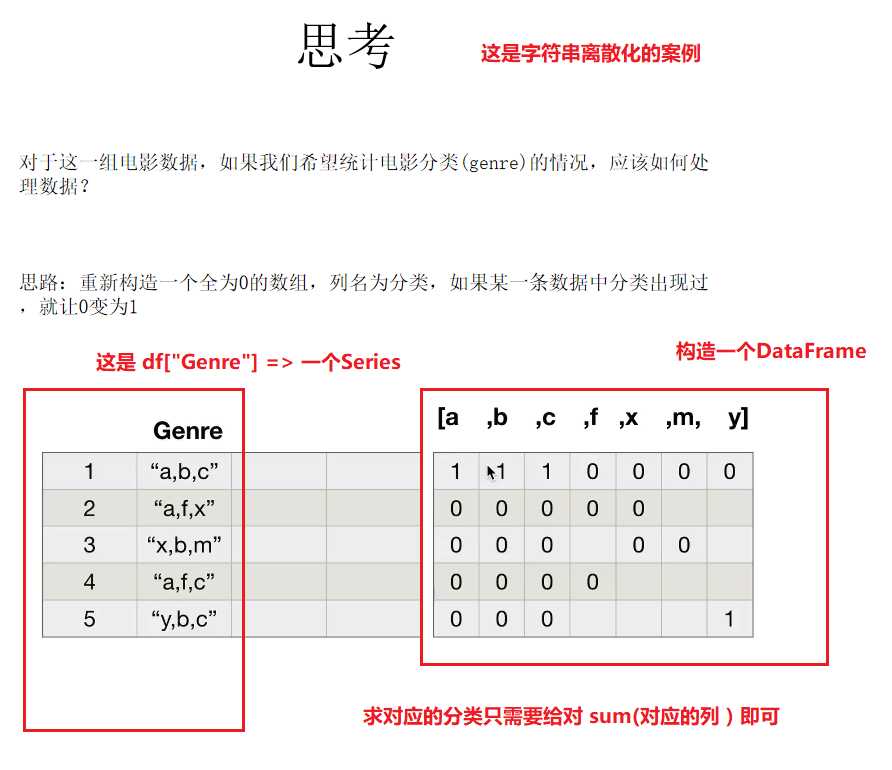
# code17_电影类型分类情况.py
# 字符串离散化案例
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
file_path = r"./IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
# print(df.loc[0,"Genre"])
temp_list = df["Genre"].str.split(",").tolist() # [[],[],[],...] 这样的格式
# 获得属性的列表
genre_list = list(set([j for i in temp_list for j in i]))
# 构造全为0的数组
zeros_pd = pd.DataFrame(np.zeros((df.shape[0], len(genre_list))), columns=genre_list)
# 给数组的每个位置赋值 => 好像并不能一行一行的处理
# for i in range(df.shape[0]):
# for j in temp_list[i]:
# zeros_pd.loc[i,j]=1
for i in range(df.shape[0]):
zeros_pd.loc[i,temp_list[i]]=1 # 直接可以一整行的处理
# 统计df => 指定axis
genre_count = zeros_pd.sum(axis=0) # 指定axis进行求和
print(genre_count) # 得到一个Series
print(‘-‘*30)
plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 用来正常显示中文标签
plt.rcParams[‘axes.unicode_minus‘] = False # 用来正常显示负号
plt.figure(figsize=(20*2,8*2),dpi=80)
plt.subplot(2,1,1)
plt.bar(genre_count.index,genre_count.values)
plt.title("电影类型统计")
plt.subplot(2,1,2)
plt.title("电影类型统计(排序)")
# 排序
genre_count.sort_values(inplace=True)
plt.bar(genre_count.index,genre_count.values,width=0.4,color="orange")
plt.show()
Pandas分组与聚合
读写数据操作
读写文本数据
CSV文件是一种纯文本文件,可以使用任何文本编辑器进行编辑,它支持追加模式(a),节省内存开销.
因为CSV文件具有诸多的优点,所以在很多时候会将数据保存在CSV文件中.
1. Pandas提供了 (1) read_csv() 和 (2) to_csv(),分别用于读取CSV文件和写入CSV文件
2. 通过to_csv()将数据写入CSV文件
to_csv(path_or_buf=None,index=True,sep=‘,‘,.....)
(1)
读写Excel数据
读取html表格数据
读写数据库
以上是关于pandas -- numpy++的主要内容,如果未能解决你的问题,请参考以下文章