Pytorch定义并训练自己的数字数据集
Posted hikseeker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch定义并训练自己的数字数据集相关的知识,希望对你有一定的参考价值。
这一篇主要讲解Pytorch搭建一个卷积神经网络识别自己的数字数据集基本流程。
注:一开始接触很多教程都是直接加载datasets已有的MNIST等,如果想要训练自己的数据就可以采用这个方法。
基本步骤:获取并读取数据-->定义网络模型和损失函数-->使用优化算法训练模型-->利用验证数据集求取网络识别准确度
1、首先是获取并读取数据,其中最关键的就是Datasets这个类即torchvision.datasets,类里自带很多数据集(包括mnist/coco/cifar10等)。就拿mnist手写识别数据集来说,我们所需要提取的信息主要有两个:一个是手写图片的所有像素,另一个就是这张图片的标签(即这个数字的大小是多少)。torchvision.datasets.MNIST()该函数所返回的就是这些信息。
datasets这个类是图像数据集中非常重要的一个类,当我们需要定义自己的数据集进行加载训练的时候,应该要继承datasets这个父类,其中父类中的两个私有成员函数必须被重载:
def __getitem__(self, index) def __len__(self)
len返回的是这个数据集的大小,而getitem主要用来编写支持数据集索引的函数。
getitem()会接收一个index,然后返回图片数据和标签。这个index通常是指一个list的index,这个list的每个元素就包含了图像所在的系统路径和标签信息。
2、那么,如果我们需要定义一个自己的数据集,就需要有一个这样的list列表。方法就是将图片的系统路径和标签信息放在一个txt文件当中,然后再从这个txt中读取信息。所以,定义并读取自己数据的基本流程如下:
(1)制作存储了图片系统路径和标签的txt文件
(2)将这些信息转换成一个list,这个list的每一个元素对应一个样本
(3)通过getitem函数读取数据像素信息和标签
3、比如我本来有这样的10个数字信息,每一个数字取700张作为训练集,200张作为验证集,如图所示

4、接下来需要编写一个python脚本对这些图像进行信息提取(提取图片路径和标签)
import os
b = 0
dir = ‘F:/ele/data/‘
#os.listdir的结果就是一个list集合
#可以使用一个list的sort方法进行排序,有数字就用数字排序
files = os.listdir(dir)
files.sort()
#print("files:", files)
train = open(‘F:/ele/data/train.txt‘, ‘a‘)
test = open(‘F:/ele/data/test.txt‘, ‘a‘)
a = 0
a1 = 0
while(b < 20):#20是因为10个train文件夹+10个valid的文件夹
#这里采用的是判断文件名的方式进行处理
if ‘train‘ in files[b]:#如果文件名有train
label = a #设置要标记的标签,比如sample001_train里面都是0的图片,标签就是0
ss = ‘F:/ele/data/‘ + str(files[b]) + ‘/‘ #700张训练图片
pics = os.listdir(ss) #得到sample001_train文件夹下的700个文件名
i = 1
while i < 701:#一共有700张
name = str(dir) + str(files[b]) + ‘/‘ + pics[i-1] + ‘ ‘ + str(int(label)) + ‘
‘
train.write(name)
i = i + 1
a = a + 1
if ‘valid‘ in files[b]:
label = a1
ss = ‘F:/ele/data/‘ + str(files[b]) + ‘/‘ #200张验证图片
pics = os.listdir(ss)
j = 1
while j < 201:
name = str(dir) + str(files[b]) + ‘/‘ + pics[j-1] + ‘ ‘ + str(int(label)) + ‘
‘
test.write(name)
j = j + 1
a1 = a1 + 1
b = b + 1
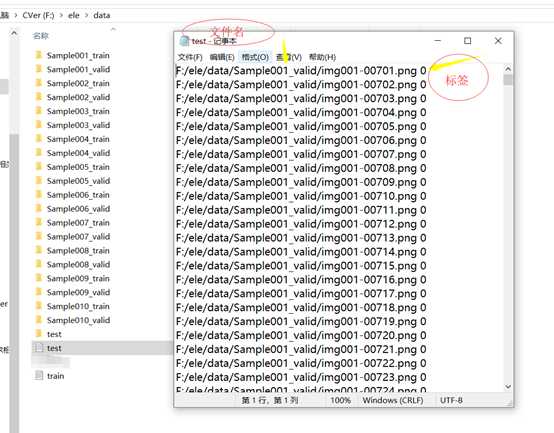
5、通过上面的python文本处理就可以得到train和test两个txt文件如图所示。
6、接下来就要定义数据集的类MyDataset如下所示:
class MyDataset(Dataset):
#初始化一些需要传入的参数和数据集的调用
def __init__(self, txt, transform=None,
target_transform=None, loader=default_loader):
super(MyDataset, self).__init__()
imgs = []
fh = open(txt, ‘r‘)
#按照传入的路径和txt文本参数,以只读的形式打开这个文本
for line in fh:
#迭代该列表,按行循环txt文本
line = line.strip(‘
‘)
line = line.rstrip(‘
‘)
#删除本行string字符串末尾的指定字符,
words = line.split()
#用split的方式将该行分割成列表
#split的默认参数是空格,所以不传递任何参数时分割空格
imgs.append((words[0], int(words[1])))
#把txt的内容读入imgs列表保存
#word[0]是图片信息,words[1]是label
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
#对数据进行预处理并返回想要的信息
#这个方法是必须要有的,用于按照索引读取每个元素的具体内容
def __getitem__(self, index):
fn, label = self.imgs[index]
img = self.loader(fn) #按照标签里面的地址读取图片的RGB像素
if self.transform is not None:
img = self.transform(img)
return img, label
#return哪些内容,那么我们在训练时循环读取每个batch时,就能获取哪些内容
#初始化一些需要传入的参数和数据集的调用
#这个函数必须写,返回数据集长度,也就是多少张图片,和Loader长度区分
def __len__(self):
return len(self.imgs)
7、其中比较关键的一个就是读取图像信息的方式default_loader,这个是定义的一个函数:
#定义读取文件的格式
def default_loader(path):
return Image.open(path).convert(‘L‘)
L表示读取灰度信息,只返回一个通道的数据
RGB表示返回三个通道的数据
接下来就是正式读取信息返回到列表里面了
因为我们所读取到的图片的尺度是图片原本的尺度,在设计神经网络的过程中,输入尺度往往有一定的要求,比如我文章使用的这个LeNet输入必须是28*28,因此可以自己定义一个train_transform进行尺度变换如下:
train_transforms = transforms.Compose(
[transforms.RandomResizedCrop((28, 28)),
transforms.ToTensor()]
)
test_transforms = transforms.Compose(
[transforms.RandomResizedCrop((28, 28)),
transforms.ToTensor()]
)
然后加载MyDataset这个类:
train_data = MyDataset(txt=root+‘train.txt‘, transform=train_transforms)
test_data = MyDataset(txt=root+‘test.txt‘, transform=test_transforms)
8、当我们把所有的数字数据打包好了之后就是要放到DataLoader里面进行批量打包,batch_size可以一次读取多张图片的信息。
train_loader = DataLoader(dataset=train_data, batch_size=10, shuffle=True, num_workers=1)
test_loader = DataLoader(dataset=test_data, batch_size=10, shuffle=False, num_workers=1)
这样一个自己的数字数据集就定义好了。
9、接下来就是要定义自己的网络模型,这里举例最简单的LeNet网络结构的类定义,其他网络只需更改类即可。
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(16*4*4, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
__init__用于对网络元素进行初始化,forward用于定义网络前向传播的规则。
10、接下来创建一个这样的网络,定义学习率,学习epoch次数,optimizer优化器类型:
net = LeNet() lr, num_epoch = 0.001, 20 optimizer = torch.optim.Adam(net.parameters(), lr=lr)
11、接下来编写训练代码,在训练过程中
def train(net, train_iter, test_iter, start_epoch, optimizer, device, num_epochs):
net = net.to(device)
print("training on:", device)
loss = torch.nn.CrossEntropyLoss()#定义损失函数
batch_count = 0 #第几个batch,如果7000张图片的batch_size是10,那么共有700个batch
nb = len(train_iter)#训练数据一共有多少
for epoch in range(start_epoch, num_epochs):
#这里之所以会有start_epoch是为了后面直接加载上次未训练完的信息
train_l_sum = 0.0#训练损失值
train_acc_sum = 0.0#训练精度
n, start = 0, time.time()
pbar = tqdm(enumerate(train_iter), total=nb)
#tqmd可以更直观地观察训练集加载的过程
for i, (imgs, targets) in pbar:
imgs = imgs.to(device)
targets = targets.to(device)
y_hat = net(imgs)#把像素信息传入网络得出预测结果
l = loss(y_hat, targets)#计算预测结果和标签的损失值
optimizer.zero_grad()#梯度清零
l.backward()#反向传播
optimizer.step()#优化器作用
train_l_sum += l.cpu().item()
#这里使用y_hat.argmax(dim=1)是因为该网络返回的是一个包含10个结果的向量
# 这10个结果分别是所属类别的概率
train_acc_sum += (y_hat.argmax(dim=1) == targets).sum().cpu().item()
#10个类别里面取出最大值的索引作为结果
n += targets.shape[0]
batch_count += 1
s = ‘%g/%g %g‘ % (epoch, num_epochs - 1, len(targets))
pbar.set_description(s) # 这个就是进度条显示
mean_loss = train_l_sum/batch_count
train_acc = train_acc_sum/n
test_acc = test(net, test_iter, device)
#下面这三个列表作为全局变量用于后面的绘图
mean_loss_list.append(mean_loss)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(‘loss %.4f, train_acc %.3f, test_acc %.3f‘ % (mean_loss, train_acc, test_acc))
#在所有的epoch训练完之后创建节点列表保存到.pt文件里面
#这样创建的好处是可以把当前未训练完的epoch也保存进去
chkpt = {‘epoch‘: epoch,
‘model‘: net.state_dict(),
‘optimizer‘: optimizer.state_dict()}
torch.save(chkpt, PATH)
del chkpt
12、训练过程中的test是表示采用验证集计算精度,考察模型泛化能力
def test(net, test_iter, device):
acc_sum, n = 0.0, 0
with torch.no_grad():
for imgs, targets in test_iter:
net.eval()
y_hat = net(imgs.to(device)).argmax(dim=1)
acc_sum += (y_hat == targets.to(device)).float().sum().cpu().item()
net.train()
n += targets.shape[0]
return acc_sum/n
13、训练完成后将结果使用PLT库画出来
train(net, train_loader, test_loader, start_epoch=start_epoch, optimizer=optimizer, device=device, num_epochs=num_epoch) plot_use_plt(mean_loss_list, train_acc_list, test_acc_list, num_epoch)
14、首先要加载import matplotlib.pyplot as plt
def plot_use_plt(mean_loss_list, train_acc_list, test_acc_list, num_epoch):
x1 = range(0, num_epoch)
x2 = range(0, num_epoch)
x3 = range(0, num_epoch)
plt.subplot(1, 3, 1) #一行三列的第一列
plt.plot(x1, mean_loss_list, ‘o-‘)
plt.title(‘Train_loss vs.epochs‘)
plt.ylabel(‘Train loss‘)
plt.subplot(1, 3, 2)
plt.plot(x2, train_acc_list, ‘.-‘)
plt.title(‘Train_acc vs.epochs‘)
plt.ylabel(‘Train acc‘)
plt.subplot(1, 3, 3)
plt.plot(x3, test_acc_list, ‘.-‘)
plt.title(‘Test_acc vs.epochs‘)
plt.ylabel(‘Test acc‘)
plt.savefig("F:/ele/show.jpg")#这一句话一定要放在plt.show()前面
plt.show()
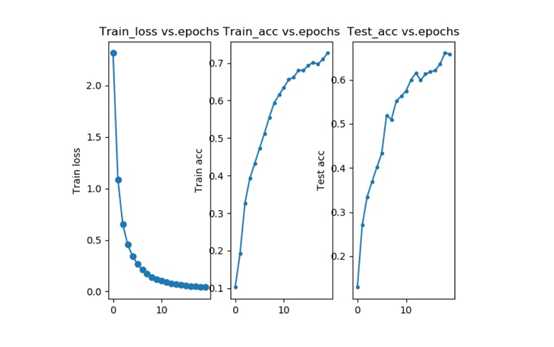
15、训练结果如图所示
本项目完整代码已上传至github:https://github.com/logic03/Digital-recognition-with-ConvNet
以上是关于Pytorch定义并训练自己的数字数据集的主要内容,如果未能解决你的问题,请参考以下文章
3.2使用PyTorch搭建AlexNet并训练花分类数据集
PyTorch 和 Albumentations 实现图像分类(猫狗大战)