Hibernate第二章关联映射的总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hibernate第二章关联映射的总结相关的知识,希望对你有一定的参考价值。
1.type值的解释:如下图:
1)type的值,不是java语言的一个类型的全称,而是一个hibernate自定义 的类型的名称。
2)Type的值,其实是对应hibernate中的一个类型的简称,而由 org.hibernate.type包下面的类型来真正完成java类型与数据库类型的传 换。
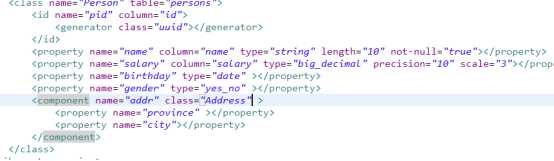
2.单类对单表的映射配置
1)类型的处理:
I.各种:type
II.精度:precision,scale
III.逻辑值的处理:boolean,yes_no
2)主键的处理
Native,assigned,uuid
3.数据库编程最佳实践
1)数据库的约束是越少越好
2)主键要用“非”业务的主键,一般会用uuid,guid做主键
4.单表映射
1)只有一个实体类映射一个表
2)有一个实体类 + 一个或者多个值类型,合在一起映射为一个表
5.多表映射
定义:类有多个映射为多给表
6.数据库层面,如orm无关
1)2个表之间要建立关系?该如何做?有多少种方法?
答案:
3种关系:
a)主键关联:A表的主键对应B表的主键,(一对一的关系)
在数据库如何建立这种关系?
结果:假定A做为主表,在B表里面的某个字段既是主键也是 外键。
b)外键关系:
c)连接表关联(中间表关联):
中间表关联既可以做一对一,也可以做一对多,也可以做多对多 关联,但实际项目中,出现中间表关联的时候,一般就是多对多。
2)多对多关系,在数据库层面本质上“不支持”,一般是把多对多关系拆分 为两个一对多。
3)
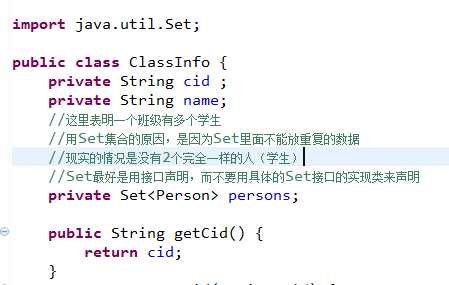
7.set集合的解说 :
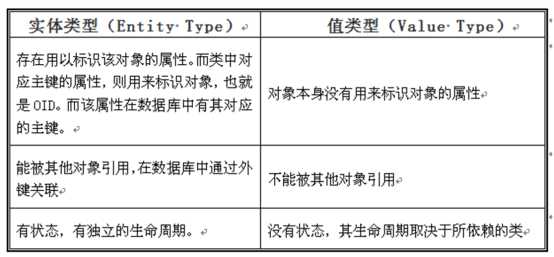
8.实体类型与值类型:
9.Hibarnate对应的sql类型和java类型

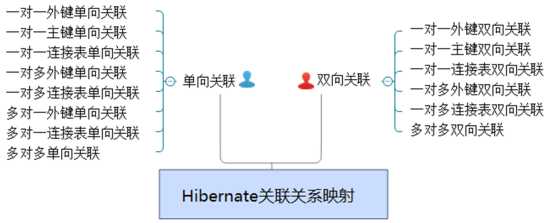
10.Hibarnate关联关系映射表:
11.常用数据库系统中可使用的标识符生成器:
1)mysql数据库:identity、increment、hiho、native
2)SQL Server数据库:identity、increment、hiho、native
3)Oracle数据库:sequence、increment、hiho、native
12.hibernate开发的三种方式中的:
1)编写domain object + 映射文件 -->创建出对应的数据库
2)这里我们说明如果要自动的创建出对应的数据库,需要做配置 (hibernate.cfg.xml)
3)<property name=”hbm2ddl.auto”>create<property>
这里有四个配置的值:create,update,create-drop,validate
I.Create:当我们的应用程序加载hibernate.cfg.xml
[new Configuration().cofig();]就会根据映射文件,创建出数据库,每次都 会重新创建,原来表中的数据就没有了。
II.update:如果数据库中没有该表 ,则创建,如果有表,则看有没有变化, 如果有变化,则更新。
III.create-drop:在显示关闭sessionFactory时,将drop掉数据库的schema。
IIII.validate:相当于每次插入数据之前都会验证数据库中的表结构和hbm 文件的结构是否一致。
注意:在开发测试中,我们配置哪个都可以测试,但是如果项目发布后, 最好自己配置一次,让对应的数据库生成,完成取消配置。
4)domain对象的细节:
a)需要一个无参的构造函数(用于hibernate反射该对像)
b)应当有一个无业务逻辑的主键属性
c)给每个属性提供 set get方法
d)在domain对象中的属性,只有配置到了对象映射文件后,才会被 hibernate管理
e)属性一般时private范围
13.Session的save()方法用来将一个临时对象转变为持久化对象,也就是将一个 新的实体保存到数据库中。通过save()将持久化对象保存到数据库需要经过 以下步骤:
1)系统根据指定的ID生成策略,为临时对象生成一个唯一的OID;
2)将临时对像加载到缓存中,使之变成持久化对象;
3)提交事务时,清理缓存,利用持久化对象包含的信息生成insert语句,将 持久化对象保存到数据库。
以上是关于Hibernate第二章关联映射的总结的主要内容,如果未能解决你的问题,请参考以下文章
Hibernate—— 一对多 和 多对多关联关系映射(xml和注解)总结(转载)
关联映射级联操作关系维护 ---- Hibernate之一对多|多对一关系