Tesseract-OCR 安装中文识别与训练字库
Posted maybaco
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tesseract-OCR 安装中文识别与训练字库相关的知识,希望对你有一定的参考价值。
简介
OCR(Optical Character Recognition):光学字符识别,是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后由Google进行改进、修改bug、优化,重新发布。
下载
1、Windows版本Tesseract各版本下载,本教程用的版本是tesseract-ocr-setup-4.00.00dev.exe(【注意】要3.0以上才支持中文)。
项目github地址:Tesseract
2、各版本对应字库要识别简体中文需要下载chi_sim.traindata字库(【注意】根据版本下载对应字库)。
3、jTessBoxEditor官网下载,用来训练字库的,带FX的版本才支持中文。
安装
1、点击tesseract-ocr-setup-4.00.00dev.exe文件,按提示安装就行,安装成功之后如下张图:
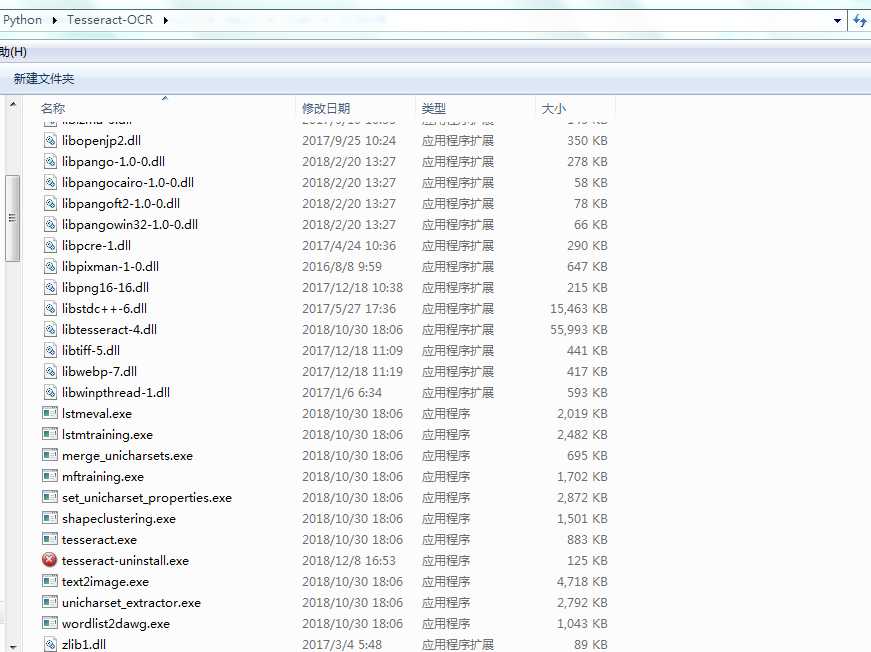
【注意】tesseract在win7系统配置环境变量跟java jdk配置相同。
复制你的安装路径,我的安装路径D:PythonTesseract-OCR,界面如下:

打开我的电脑--系统属性->高级->环境变量
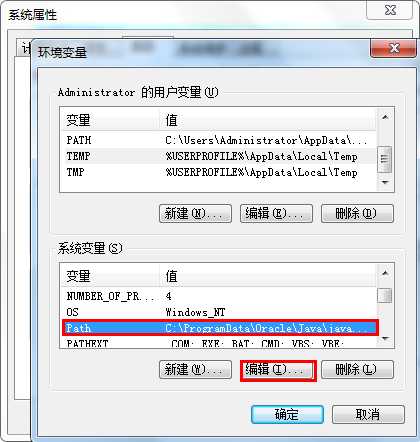
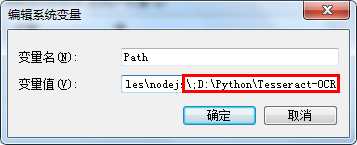
【注意】 于其他路径要以“;”隔开
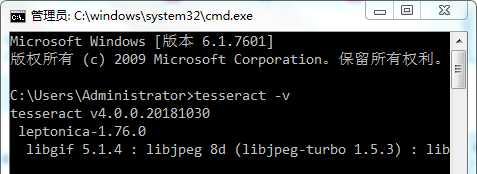
在CMD窗口中输入“tesseract -v,”配置成功如下图:
2、将下载好的字库放到Tesseract-OCR项目的tessdata文件夹里面。
识别
进入cmd,进入到要识别的图片的路径下E:PythonCode*** esseract图片识别(根据自己图片位置而定),输入命令
识别
进入cmd,进入到要识别的图片的路径下E:PythonCode*** esseract图片识别(根据自己图片位置而定),输入命令

例如我的图片识别就是:

经验转载于:https://www.jianshu.com/p/3326c7216696
以上是关于Tesseract-OCR 安装中文识别与训练字库的主要内容,如果未能解决你的问题,请参考以下文章