疫情宅在家,研究一下fastjson中字段智能匹配的原理
Posted 水中加点糖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了疫情宅在家,研究一下fastjson中字段智能匹配的原理相关的知识,希望对你有一定的参考价值。
示例
有次看到项目中同事用驼峰(Camel-Case)命名法定义的字段来直接接收对方下划线命名的字段,刚开始我还以为有BUG

结果一测试:
import com.alibaba.fastjson.JSON;
import lombok.Data;
public class FastJsonTestMain
public static void main(String[] args)
String jsonStr = "\\n" +
" \\"age\\": 28,\\n" +
" \\"user_id\\": 123,\\n" +
" \\"user_name\\": \\"海洋哥\\"\\n" +
"";
UserInfo userInfo = JSON.parseObject(jsonStr, UserInfo.class);
System.out.println(userInfo.toString());
@Data
public static class UserInfo
private Integer age;
private Long userId;
private String userName;
输入的字符串为:
"age": 28,
"user_id": 123,
"user_name": "海洋哥"
输出结果为:
FastJsonTestMain.UserInfo(age=28, userId=123, userName=海洋哥)
才明白原来菜的人是我自己。
fastjson反序列化时,是能自动下划线转驼峰的。
但换了其他的json框架发现又不行,趁着疫情关在家,决定还是来研究一下fastjson中它自动转驼峰的原理。
fastjson智能匹配处理过程
fastjson在进行反序列化的时候,对每一个json字段的key值解析时,会调用
com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer#parseField
这个方法
以上面的例子为例,通过debug打个断点看一下解析user_id时的处理逻辑。
此时这个方法中的key为user_id,object为要反序列化的结果对象,这个例子中就是FastJsonTestMain.UserInfo
public boolean parseField(DefaultJSONParser parser, String key, Object object, Type objectType,
Map<String, Object> fieldValues, int[] setFlags)
JSONLexer lexer = parser.lexer; // xxx
//是否禁用智能匹配;
final int disableFieldSmartMatchMask = Feature.DisableFieldSmartMatch.mask;
final int initStringFieldAsEmpty = Feature.InitStringFieldAsEmpty.mask;
FieldDeserializer fieldDeserializer;
if (lexer.isEnabled(disableFieldSmartMatchMask) || (this.beanInfo.parserFeatures & disableFieldSmartMatchMask) != 0)
fieldDeserializer = getFieldDeserializer(key);
else if (lexer.isEnabled(initStringFieldAsEmpty) || (this.beanInfo.parserFeatures & initStringFieldAsEmpty) != 0)
fieldDeserializer = smartMatch(key);
else
//进行智能匹配
fieldDeserializer = smartMatch(key, setFlags);
***此处省略N多行***
再看下核心的代码,智能匹配smartMatch
public FieldDeserializer smartMatch(String key, int[] setFlags)
if (key == null)
return null;
FieldDeserializer fieldDeserializer = getFieldDeserializer(key, setFlags);
if (fieldDeserializer == null)
if (this.smartMatchHashArray == null)
long[] hashArray = new long[sortedFieldDeserializers.length];
for (int i = 0; i < sortedFieldDeserializers.length; i++)
//java字段的nameHashCode,源码见下方
hashArray[i] = sortedFieldDeserializers[i].fieldInfo.nameHashCode;
//获取出反序列化目标对象的字段名称hashcode值,并进行排序
Arrays.sort(hashArray);
this.smartMatchHashArray = hashArray;
// smartMatchHashArrayMapping
long smartKeyHash = TypeUtils.fnv1a_64_lower(key);
//进行二分查找,判断是否找到
int pos = Arrays.binarySearch(smartMatchHashArray, smartKeyHash);
if (pos < 0)
//原始字段没有匹配到,用fnv1a_64_extract处理一下再次匹配
long smartKeyHash1 = TypeUtils.fnv1a_64_extract(key);
pos = Arrays.binarySearch(smartMatchHashArray, smartKeyHash1);
boolean is = false;
if (pos < 0 && (is = key.startsWith("is")))
//上面的操作后仍然没有匹配到,把is去掉后再次进行匹配
smartKeyHash = TypeUtils.fnv1a_64_extract(key.substring(2));
pos = Arrays.binarySearch(smartMatchHashArray, smartKeyHash);
if (pos >= 0)
//通过智能匹配字段匹配成功
if (smartMatchHashArrayMapping == null)
short[] mapping = new short[smartMatchHashArray.length];
Arrays.fill(mapping, (short) -1);
for (int i = 0; i < sortedFieldDeserializers.length; i++)
int p = Arrays.binarySearch(smartMatchHashArray, sortedFieldDeserializers[i].fieldInfo.nameHashCode);
if (p >= 0)
mapping[p] = (short) i;
smartMatchHashArrayMapping = mapping;
int deserIndex = smartMatchHashArrayMapping[pos];
if (deserIndex != -1)
if (!isSetFlag(deserIndex, setFlags))
fieldDeserializer = sortedFieldDeserializers[deserIndex];
if (fieldDeserializer != null)
FieldInfo fieldInfo = fieldDeserializer.fieldInfo;
if ((fieldInfo.parserFeatures & Feature.DisableFieldSmartMatch.mask) != 0)
return null;
Class fieldClass = fieldInfo.fieldClass;
if (is && (fieldClass != boolean.class && fieldClass != Boolean.class))
fieldDeserializer = null;
return fieldDeserializer;
通过上面的smartMatch方法可以看出,fastjson中之所以能做到下划线自动转驼峰,主要还是因为在进行字段对比时,使用了fnv1a_64_lower和fnv1a_64_extract方法进行了处理。
fnv1a_64_extract方法源码:
public static long fnv1a_64_extract(String key)
long hashCode = fnv1a_64_magic_hashcode;
for (int i = 0; i < key.length(); ++i)
char ch = key.charAt(i);
//去掉下划线和减号
if (ch == '_' || ch == '-')
continue;
//大写转小写
if (ch >= 'A' && ch <= 'Z')
ch = (char) (ch + 32);
hashCode ^= ch;
hashCode *= fnv1a_64_magic_prime;
return hashCode;
从源码可以看出,fnv1a_64_extract方法主要做了这个事:
去掉下划线、减号,并大写转小写
fnv1a_64_lower方法源码:
public static long fnv1a_64_lower(String key)
long hashCode = fnv1a_64_magic_hashcode;
for (int i = 0; i < key.length(); ++i)
char ch = key.charAt(i);
if (ch >= 'A' && ch <= 'Z')
ch = (char) (ch + 32);
hashCode ^= ch;
hashCode *= fnv1a_64_magic_prime;
return hashCode;
从源码可以看出,fnv1a_64_lower方法做了大写转小写的功能
其次上面代码中的fieldInfo.nameHashCode的源码也有必要贴一下:
com.alibaba.fastjson.util.FieldInfo#nameHashCode64
private long nameHashCode64(String name, JSONField annotation)
//先从@JSONField注解的name中取值
if (annotation != null && annotation.name().length() != 0)
return TypeUtils.fnv1a_64_lower(name);
//没有@JSONField注解,直接使用java对象的字段
return TypeUtils.fnv1a_64_extract(name);
总结
fastjson中字段智能匹配的原理是在字段匹配时,使用了TypeUtils.fnv1a_64_lower方法对字段进行全体转小写处理。
之后再用TypeUtils.fnv1a_64_extract方法对json字段进行去掉"_“和”-"符号,再全体转小写处理。
如果上面的操作仍然没有匹配成功,会再进行一次去掉json字段中的is再次进行匹配。
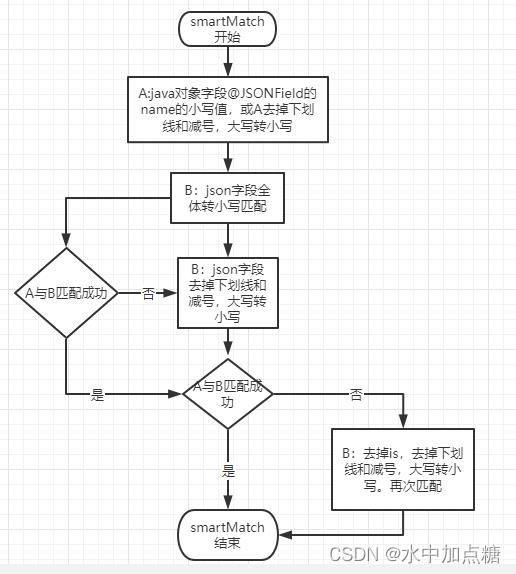
再简化一点描述:
- A是java类对象中的一个字段,B是json串的一个字段,A与B的字段进行匹配。
- A的值优先从@JSONField的name值去取,取到的话就用@JSONField.name的小写值。没取到的话直接使用A的值,去掉"-“、”_"并转小写。
- B的值为json串的值,先使用它的全体小写值与A进行匹配,没有匹配成功再用B的值去掉"-“、”“并转小写进行匹配。如果仍然没有匹配成功且B是以is开头的,则用B去掉is、”-“、”"并转小写进行匹配。
其他
fastjson中smartMatch是默认开启的,如果想要关闭,指定DisableFieldSmartMatch即可
JSONObject.parseObject(strJson, class, Feature.DisableFieldSmartMatch);
例如:
UserInfo userInfo = JSON.parseObject(jsonStr, UserInfo.class, Feature.DisableFieldSmartMatch);
以上是关于疫情宅在家,研究一下fastjson中字段智能匹配的原理的主要内容,如果未能解决你的问题,请参考以下文章