虚拟机类加载机制
Posted yzhengy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了虚拟机类加载机制相关的知识,希望对你有一定的参考价值。
概述
Java虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这个过程被称作虚拟机的类加载机制。
类的生命周期
一个类型从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期将会经历加载、验证、准备、解析、初始化、使用和卸载七个阶段,其中验证、准备、解析三个部分统称为连接。七个阶段的发生顺序如下图。
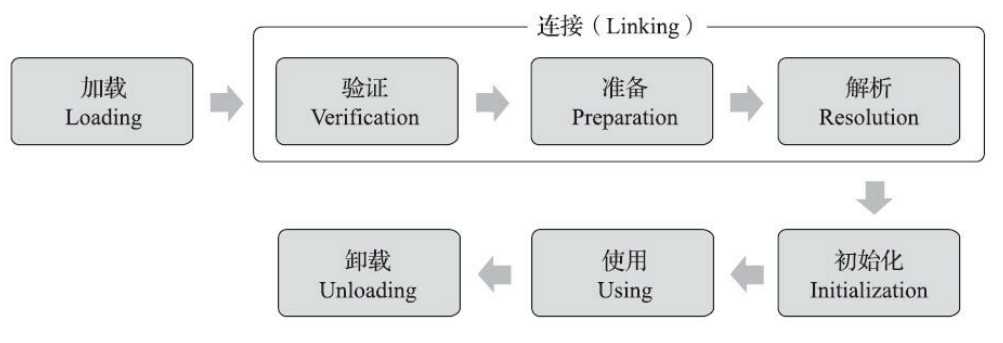
加载、验证、准备、初始化和卸载这五个阶段的顺序是确定的,类型的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定特性。
《Java虚拟机规范》 严格规定了**有且只有**六种情况必须立即对类进行“初始化”(而加载、验证、准备要在此之前开始):
1)遇到new、getstatic、putstatic或invokestatic这四条字节码指令时,如果类型没有进行过初始化,则需要先触发其初始化阶段。
2)使用java.lang.reflect包的方法对类型进行反射调用的时候,如果类型没有进行过初始化,则需要先触发其初始化。
3)当初始化类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
4)当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类。
5)当使用JDK 7新加入的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果为REF_getStatic、REF_putStatic、REF_invokeStatic、REF_newInvokeSpecial四种类型的方法句柄,并且这个方法句柄对应的类没有进行过初始化,则需要先触发其初始化。
6)当一个接口中定义了JDK 8新加入的默认方法(被default关键字修饰的接口方法)时,如果有这个接口的实现类发生了初始化,那该接口要在其之前被初始化。
这六种场景中的行为称为对一个类型进行主动引用。除此之外,所有引用类型的方式都不会触发初始化,称为被动引用。
被动引用举例:
通过子类引用父类的静态字段,不会导致子类初始化
通过数组定义来引用类,不会触发此类的初始化
常量在编译阶段会存入调用类的常量池中,本质上没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化
接口的加载过程
接口的加载过程与类加载过程稍有不同,针对接口需要做一些特殊说明:
接口也有初始化过程,类的代码都是用静态语句块“static{}”来输出初始化信息的,而接口中不能使用“static{}”语句块,但编译器仍然会为接口生成“
类加载的详细过程
加载
在加载阶段,Java虚拟机需要完成以下三件事情:
1)通过一个类的全限定名来获取定义此类的二进制字节流。
2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
验证
验证的目的是确保Class文件的字节流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信息被当作代码运行后不会危害虚拟机自身的安全。
验证阶段大致上会完成四个阶段的检验动作:文件格式验证、元数据验证、字节码验证和符号引用验证。
准备
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段,从概念上讲,这些变量所使用的内存都应当在方法区中进行分配,但必须注意到方法区本身是一个逻辑上的区域,在JDK 7及之前,HotSpot使用永久代来实现方法区时,实现是完全符合这种逻辑概念的;而在JDK 8及之后,类变量则会随着Class对象一起存放在Java堆中,这时候“类变量在方法区”就完全是一种对逻辑概念的表述了。
实例变量不会在这阶段分配内存,它会在对象实例化时随着对象一起被分配在堆中。
初始值“通常情况”下是数据类型的零值,例如下面的类变量 value 被初始化为 0 而不是 123。
public static int value = 123;
如果类变量是常量,那么它将初始化为表达式所定义的值而不是 0。例如下面的常量 value 被初始化为 123 而不是0。
public static final int value = 123;
解析
解析阶段是Java虚拟机将常量池内的符号引用替换为直接引用的过程。
其中解析过程在某些情况下可以在初始化阶段之后再开始,这是为了支持 Java 的动态绑定。
初始化
除了在加载阶段用户应用程序可以通过自定义类加载器的方式局部参与外,其余动作都完全由Java虚拟机来主导控制。直到初始化阶段,Java虚拟机才真正开始执行类中编写的Java程序代码,将主导权移交给应用程序。
进行准备阶段时,变量已经赋过一次系统要求的初始零值,而在初始化阶段,则会根据程序员通过程序编码制定的主观计划去初始化类变量和其他资源。初始化阶段就是执行类构造器
接口中不可以使用静态语句块,但仍然有类变量初始化的赋值操作,接口与类一样都会生成
接口的实现类在初始化时也一样不会执行接口的
类加载器
Java虚拟机设计团队有意把类加载阶段中的“通过一个类的全限定名来获取描述该类的二进制字节流”这个动作放到虚拟机外部去实现,以便让应用程序自己决定如何去获取所需的类。实现这个动作的代码被称为“类加载器”(Class Loader)。
任意一个类,都必须由加载它的类加载器和这个类本身一起共同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。即比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个Java虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
“相等”,包括代表类的Class对象的equals()方法、isAssignableFrom()方法、isInstance()方法的返回结果,也包括了使用instanceof关键字做对象所属关系判定等各种情况。
双亲委派模型
站在Java虚拟机的角度来看,只存在两种不同的类加载器:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器使用C++语言实现,是虚拟机自身的一部分;另外一种就是其他所有的类加载器,这些类加载器都由Java语言实现,独立存在于虚拟机外部,并且全都继承自抽象类java.lang.ClassLoader。
站在Java开发人员的角度来看,类加载器就应当划分得更细致一些。对于这个时期的Java应用,绝大多数Java程序都会使用到以下3个系统提供的类加载器来进行加载。
--启动类加载器(Bootstrap Class Loader):这个类加载器负责加载存放在<JAVA_HOME>lib目录,或被-Xbootclasspath参数所指定的路径中存放的,而且是Java虚拟机能够识别的(按照文件名识别,如rt.jar,tools.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机的内存中。启动类加载器无法被Java程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给引导类加载器去处理,那直接使用null代替即可。
--扩展类加载器(Extension Class Loader):这个类加载器是在类sun.misc.Launcher$ExtClassLoader中以Java代码的形式实现的。它负责加载<JAVA_HOME>libext目录中,或者被java.ext.dirs系统变量所指定的路径中所有的类库。这是一种Java系统类库的扩展机制,JDK的开发团队允许用户将具有通用性的类库放置在ext目录里以扩展Java SE的功能,在JDK9之后,这种扩展机制被模块化带来的天然的扩展能力所取代。由于扩展类加载器是由Java代码实现的,开发者可以直接在程序中使用扩展类加载器来加载Class文件。
--应用程序类加载器(Application Class Loader):这个类加载器由sun.misc.Launcher$AppClassLoader来实现。由于应用程序类加载器是ClassLoader类中的getSystem-ClassLoader()方法的返回值,所以有些场合中也称它为“系统类加载器”。它负责加载用户类路径(ClassPath)上所有的类库,开发者同样可以直接在代码中使用这个类加载器。如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
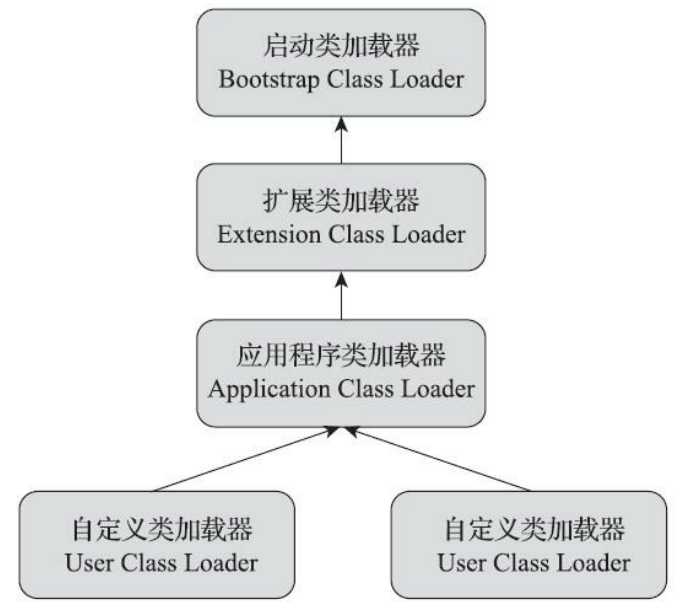
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器。不过这里类加载器之间的父子关系一般不是以继承(Inheritance)的关系来实现的,而是通常使用组合(Composition)关系来复用父加载器的代码。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
使用双亲委派模型来组织类加载器之间的关系,好处是Java中的类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar之中,无论哪一 个类加载器要加载这个类,最终都是委派给处于模型最顶端的启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都能够保证是同一个类。反之,如果没有使用双亲委派模型,都由各个 类加载器自行去加载的话,如果用户自己也编写了一个名为java.lang.Object的类,并放在程序的 ClassPath中,那系统中就会出现多个不同的Object类,Java类型体系中最基础的行为也就无从保证,应用程序将会变得一片混乱。
//双亲委派模型的实现:先检查请求加载的类型是否已经被加载过,若没有则调用父加载器的 loadClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。假如父类加载器加载失败, 抛出ClassNotFoundException异常的话,才调用自己的findClass()方法尝试进行加载。
protected synchronized Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { // 首先,检查请求的类是否已经被加载过了
Class c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
c = parent.loadClass(name, false); }
else { c = findBootstrapClassOrNull(name); }}
catch (ClassNotFoundException e) {
// 如果父类加载器抛出ClassNotFoundException
// 说明父类加载器无法完成加载请求 }
if (c == null) {
// 在父类加载器无法加载时
// 再调用本身的findClass方法来进行类加载
c = findClass(name); } }
if (resolve) {
resolveClass(c); }
return c;
}
破坏双亲委派模型
--第一次“被破坏”其实发生在双亲委派模型出现之前——即JDK 1.2面世以前。由于双亲委派模型在JDK 1.2之后才被引入,但是类加载器的概念和抽象类java.lang.ClassLoader则在Java的第一个版本中就已经存在,面对已经存在的用户自定义类加载器的代码,Java设计者们引入双亲委派模型时不得不做出一些妥协,为了兼容这些已有代码,无法再以技术手段避免loadClass()被子类覆盖的可能性,只能在JDK 1.2之后的java.lang.ClassLoader中添加一个新的protected方法findClass(),并引导用户编写的类加载逻辑时尽可能去重写这个方法,而不是在loadClass()中编写代码。上节我们已经分析过loadClass()方法,双亲委派的具体逻辑就实现在这里面,按照loadClass()方法的逻辑,如果父类加载失败,会自动调用自己的findClass()方法来完成加载,这样既不影响用户按照自己的意愿去加载类,又可以保证新写出来的类加载器是符合双亲委派规则的。
--第二次“被破坏”是由这个模型自身的缺陷导致的,双亲委派很好地解决了各个类加载器协作时基础类型的一致性问题(越基础的类由越上层的加载器进行加载),基础类型之所以被 称为“基础”,是因为它们总是作为被用户代码继承、调用的API存在,但程序设计往往没有绝对不变的完美规则,如果有基础类型又要调用回用户的代码,那该怎么办呢?
一个典型的例子便是JNDI服务,JNDI现在已经是Java的标准服务,它的代码由启动类加载器来完成加载(在JDK 1.3时加入到rt.jar的),肯定属于Java中很基础的类型 了。但JNDI存在的目的就是对资源进行查找和集中管理,它需要调用由其他厂商实现并部署在应用程序的ClassPath下的JNDI服务提供者接口(Service Provider Interface,SPI)的代码,现在问题来了,启动类加载器是绝不可能认识、加载这些代码的,那该怎么办?为了解决这个困境,Java的设计团队只好引入了一个不太优雅的设计:线程上下文类加载器 (Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContext-ClassLoader()方 法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器。
有了线程上下文类加载器,程序就可以做一些“舞弊”的事情了。JNDI服务使用这个线程上下文类加载器去加载所需的SPI服务代码,这是一种父类加载器去请求子类加载器完成类加载的行为,这种行为实际上是打通了双亲委派模型的层次结构来逆向使用类加载器,已经违背了双亲委派模型的一般性原则,但也是无可奈何的事情。Java中涉及SPI的加载基本上都采用这种方式来完成,例如JNDI、 JDBC、JCE、JAXB和JBI等。不过,当SPI的服务提供者多于一个的时候,代码就只能根据具体提供者的类型来硬编码判断,为了消除这种极不优雅的实现方式,在JDK 6时,JDK提供了java.util.ServiceLoader类,以META-INF/services中的配置信息,辅以责任链模式,这才算是给SPI的加载提供了一种相对合理的解决方案。
--第三次“被破坏”是由于用户对程序动态性的追求而导致的,这里所说的“动态性”指的是一些非常“热”门的名词:代码热替换(Hot Swap)、模块热部署(Hot Deployment)等。说白了就是希望Java应用程序能像我们的电脑外设那样,接上鼠标、U盘,不用重启机器就能立即使用, 鼠标有问题或要升级就换个鼠标,不用关机也不用重启。对于个人电脑来说,重启一次其实没有什么大不了的,但对于一些生产系统来说,关机重启一次可能就要被列为生产事故,这种情况下热部署就对软件开发者,尤其是大型系统或企业级软件开发者具有很大的吸引力。
OSGi实现模块化热部署的关键是它自定义的类加载器机制的实现,每一个程序模块(OSGi中称为Bundle)都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换。在OSGi环境下,类加载器不再双亲委派模型推荐的树状结构,而是进一步发展为更加复杂的网状结构。
Spring破坏双亲委派模型
Spring要对用户程序进行组织和管理,而用户程序一般放在WEB-INF目录下,由WebAppClassLoader类加载器加载,而Spring由Common类加载器或Shared类加载器加载。那么Spring是如何访问WEB-INF下的用户程序呢?
使用线程上下文类加载器。 Spring加载类所用的classLoader都是通过Thread.currentThread().getContextClassLoader()获取的。当线程创建时会默认创建一个AppClassLoader类加载器(对应Tomcat中的WebAppclassLoader类加载器):setContextClassLoader(AppClassLoader)。
利用这个来加载用户程序。即任何一个线程都可通过getContextClassLoader()获取到WebAppclassLoader。
以上是关于虚拟机类加载机制的主要内容,如果未能解决你的问题,请参考以下文章