Spark DAG 依赖关系 Stage
Posted alen-apple
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark DAG 依赖关系 Stage相关的知识,希望对你有一定的参考价值。
DAG :
整个计算链可以抽象为一个DAG(有向无环图) Spark 的 DAG 作用:
记录了RDD之间的依赖关系,即RDD是通过何种变换生成的,
如下图:RDD1是RDD2的父RDD,通过flatMap操作生成 借助RDD之间的依赖关系,可以实现数据的容错,
即子分区(子RDD)数据丢失后,可以通过找寻父分区(父RDD),结合依赖关系进行数据恢复
综上,RDD(弹性分布式数据集)
①分区机制
②容错机制(借助RDD之间的依赖关系容错) 即使用Spark 框架处理数据,把数据封装为RDD,然后通过高阶函数来处理

以上的执行过程如下:
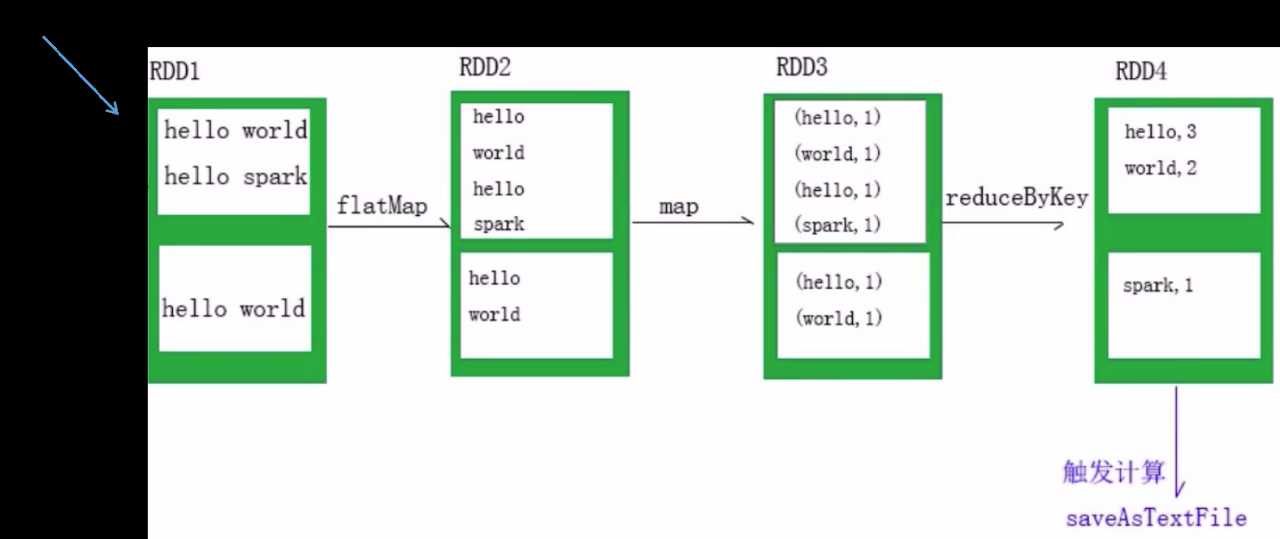
RDD之间的依赖关系
依赖关系有两种:
①窄依赖:父分区和子分区是一对一关系,没有shuffle,即不会发生磁盘I/O,所以执行效率很高,
如果DAG中存在多个连续的窄依赖,会放到一起执行,这种优化方式称为流水线优化
②宽依赖:父分区和子分区是一对多关系,会发生shuffle过程,会发生磁盘I/O。所以Spark框架并不是完全基于内存的,
也是要依赖于磁盘的。但是已经尽力避免产生shuffle

Stage
Spark的Stage(阶段)
Spark在执行任务(job)时,首先会根据依赖关系,将DAG划分为不同的阶段(Stage)。
处理流程是:
1)Spark在执行Transformation类型操作时都不会立即执行,而是懒执行(计算)
2)执行若干步的Transformation类型的操作后,一旦遇到Action类型操作时,才会真正触发执行(计算)
3)执行时,从当前Action方法向前回溯,如果遇到的是窄依赖则应用流水线优化,继续向前找,直到碰到某一个宽依赖
4)因为宽依赖必须要进行shuffle,无法实现优化,所以将这一次段执行过程组装为一个stage
5)再从当前宽依赖开始继续向前找。重复刚才的步骤,从而将这个DAG还分为若干的stage
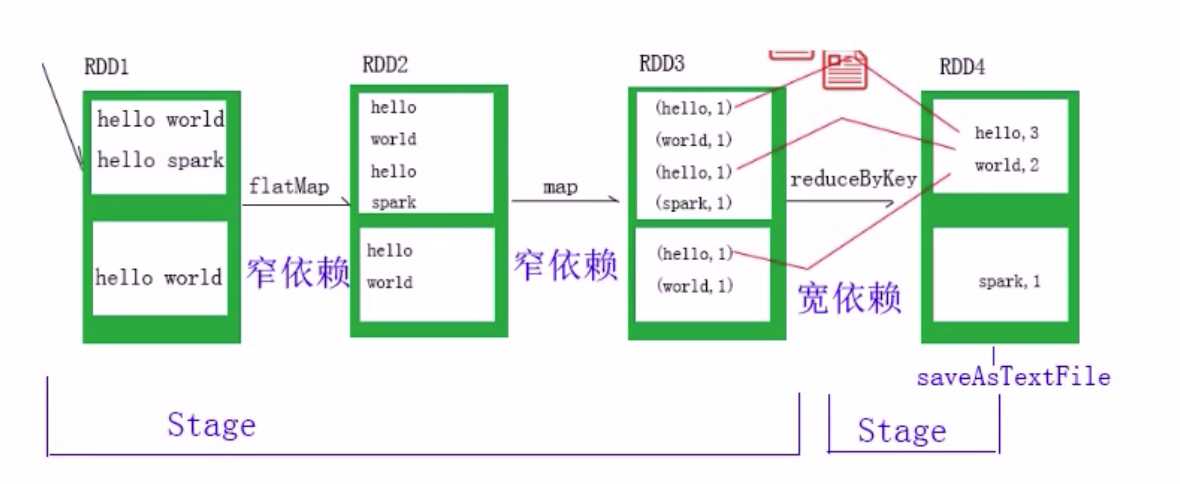
Stage(阶段) -> 一组Task集合
Task任务对应的是分区,即一个分区就是一个Task,但是要注意:多个连续的窄依赖,会放到一起执行 作为一个Task,宽依赖按照不同的分区
以上是关于Spark DAG 依赖关系 Stage的主要内容,如果未能解决你的问题,请参考以下文章