云上混沌工程实践之可行性评估篇-收集
Posted passzhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云上混沌工程实践之可行性评估篇-收集相关的知识,希望对你有一定的参考价值。
AWS云上混沌工程实践之可行性评估篇-收集
我们在启动篇中谈到混沌工程的发展不是一蹴而就的, Chaos Monkey 开创了混沌工程的先河,从对基础设施的扰动( EC2 实例随机终止 Chaos Monkey 、模拟可用区中断 Chaos Gorilla 、模拟区域中断 Chaos Kong 等),到利用应用网关控制爆炸半径,再到精细化流量配比以区分影响,直至引入断路器实现真正无人值守的混沌工程实验平台。
本篇是混沌工程专栏的第二篇,笔者会探讨大家比较关心的第一个问题——为了能够成功实施混沌工程实验有哪些可行性要求:对实现对象的架构要求?对实验技术能力的要求?对实验工具的要求?还是实验可控性的要求?通常分析这样的问题,我们必须首先弄清楚混沌工程实验的目标。有了明确的目标,才可以深入地评估所做的混沌工程实验是否“可行”,能否“成功实施“。
混沌工程的目标 – 实现韧性架构
正如 AWS CTO Werner Vogels 常说的“故障是注定的,随着时间的流逝,一切终将归于失败”。我们必须接受故障发生是新常态的想法,处在部分故障的系统正常运行是完全可行的。当我们处理多达几十个 EC2 实例的小型系统时,100%的健康运行通常是正常状态,故障则是一种特殊情况。然而,在处理大规模系统时,即100%的健康运行几乎是不可能实现的。因此,运维的新常态便是接受部分故障。处在部分故障中的系统要求仍能正常运行对外提供服务,这就需要架构本身具备 Resilient 能力。这里我并不想把“ Resilient ”翻译成弹性,而应该是韧性(具备恢复能力)。混沌工程就是利用实验提前探知系统风险,通过架构优化和运维模式的改进来解决系统风险,真正实现上述韧性架构,降低企业损失,提高故障免疫力。
韧性架构的重要特征
冗余性
架构的设计要增加冗余性,以便提高该系统的整体可用性。如在AWS云中,这意味着将其部署到多个可用区,甚至跨多个区域进行部署。
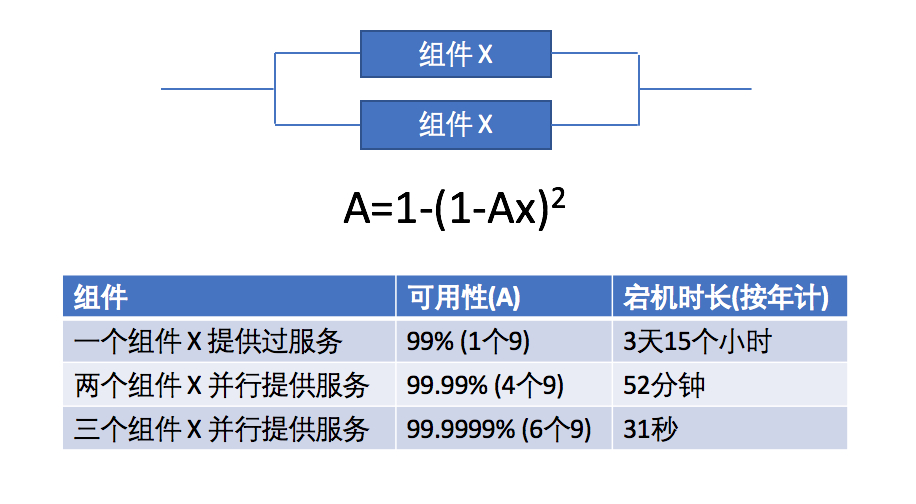
正如上图中所看到的那样,组件X的可用性是99%(按今天的标准来说非常糟糕),但并行放置,增加冗余性,可以将系统的可用性提高到99.99%!如果将三个组件X并行放置,那么就可以达到6个9的可用性!这个结果很惊人,这就是为什么我们总是建议客户跨多个可用区设计架构。
扩展性
架构的设计必须要考虑扩展性,即启用 Auto Scaling ,根据需求动态扩展资源 – 而不是手动执行 – 确保可以满足各种流量模式。如在AWS云中,可使用 Application Auto Scaling 功能为EC2,DynamoDB和EMR等服务提供相同的自动扩展引擎,以支持AWS外部服务的自动扩展。
不可变基础设施
不可变基础设施指的是,每次部署都会替换相应的组件,不做更新。应用部署则使用金丝雀发布(俗称灰度发布),以减少部署新版本应用时出现故障的风险。使用这种技术,可以在真实的生产环境中进行测试,并在需要时进行快速回滚。
无状态应用
无状态应用是自动扩展和不可变基础设施的先决条件,要求应用必须独立于先前的请求或会话,处理所有客户端请求,并且不会存储在本地磁盘或内存中。
避免级联故障
级联故障指的是因依赖关系引发的局部故障导致整个系统崩溃(俗称蝴蝶效应)。架构设计必须考虑级联故障的处理方式:
- 转移切换:当一个集群宕机时,所有的流量都转移到另一个集群,如跨可用区切换,或者跨区域切换。
- 重试退避:指数退避算法逐渐对客户端重试请求减速,避免网络拥塞,同时添加抖动保证性能,详细讨论参看这里。
- 超时机制:过载请求会将连接耗尽,导致系统宕机。超时机制的引入,服务的质量会下降但不至于系统全面崩溃。
- 幂等操作:由于暂时的错误,客户端可能多次发送相同的请求,可能导致系统处理错误。幂等操作,一种可以反复重复的操作,没有副作用或应用程序的失败,可以消除上述隐患。
- 服务降级:当服务器压力剧增的情况下,有策略地减少或退化部分服务,以此释放服务器资源以保证核心任务的正常运行,如只读模式、停用耗时耗资源的功能等等。
- 拒绝服务:请求过载时,按优先级开始丢弃相应的请求。
- 服务熔断:若某个目标服务调用过慢或者有大量超时,直接熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回响应,快速释放资源,待目标服务情况好转则恢复调用。
基础设施即代码
基础设施即代码可减轻繁琐的手工配置和部署任务,由于可用完全相同的方式反复执行,因此解决了随时间推移引发的配置漂移问题,当有故障发生,基础设施的恢复快速且有效。同时可对基础架构以代码的形式进行版本控制,管理其更新、审核、验证和回溯分析。
弄清楚了混沌工程的目标,现在可以来深入讨论如何来评估混沌工程实验的可行性条件。
混沌工程的可行性评估模型
在执行混沌工程实验时,我们需有一个通用的标准来,判断这个实验可不可行,做得好不好。混沌工程的可行性评估模型,结合了亚马逊和Netflix的混沌工程成熟度模型,从成熟度等级和接纳指数两个维度来衡量混沌工程实验成功实施的可行性:
混沌工程实验的成熟度等级
成熟度可以反映出混沌工程实验的可行性、有效性和安全性。成熟度的级别也会因为混沌工程实验的投入程度而有差异。这里将成熟度等级分为1、2、3、4、5级进行描述,等级越高成熟度越好,混沌工程实验的可行性、有效性和安全性会更有保障。
| 实验成熟度等级 | 1级 | 2级 | 3级 | 4级 | 5级 |
|---|---|---|---|---|---|
| 架构抵御故障的能力 | 无抵御故障的能力 | 一定的冗余性 | 冗余且可扩展 | 已使用可避免级联故障的技术 | 已实现韧性架构 |
| 实验指标设计 | 无系统指标监控 | 实验结果只反映系统状态指标 | 实验结果反映应用的健康状况指标 | 实验结果反映聚合的业务指标 | 可在实验组和控制组之间比较业务指标的差异 |
| 实验环境选择 | 只敢在开发和测试环境中运行实验 | 可在预生产环境中运行实验 | 未在生产环境中,用复制的生产流量来运行实验 | 在生产环境中运行实验 | 包括生产在内的任意环境都可以运行实验 |
| 实验自动化能力 | 全人工流程 | 利用工具进行半自动运行实验 | 自助式创建实验,自动运行实验,但需要手动监控和停止实验 | 自动结果分析,自动终止实验 | 全自动的设计、执行和终止实验 |
| 实验工具使用 | 无实验工具 | 采用实验工具 | 使用实验框架 | 实验框架和持续发布工具集成 | 并有工具支持交互式的比对实验组和控制组 |
| 故障注入场景 | 只对实验对象注入一些简单事件,如突发高CPU高内存等等 | 可对实验对象进行一些较复杂的故障注入,如EC2实例终止、可用区故障等等 | 对实验对象注入较高级的事件,如网络延迟 | 对实验组引入如服务级别的影响和组合式的故障事件 | 可以注入如对系统的不同使用模式、返回结果和状态的更改等类型的事件 |
| 环境恢复能力 | 无法恢复正常环境 | 可手动恢复环境 | 可半自动恢复环境 | 部分可自动恢复环境 | 韧性架构自动恢复 |
| 实验结果整理 | 没有生成的实验结果,需要人工整理判断 | 可通过实验工具的到实验结果,需要人工整理、分析和解读 | 可通过实验工具持续收集实验结果,但需要人工分析和解读 | 可通过实验工具持续收集实验结果和报告,并完成简单的故障原因分析 | 实验结果可预测收入损失、容量规划、区分出不同服务实际的关键程度 |
混沌工程实验的接纳指数
接纳指数通过对混沌工程实验覆盖的广度和深度来描述对系统的信心。暴露的脆弱点就越多,对系统的信心也就越足。类似成熟度等级,对接纳指数也定义了1、2、3、4级进行描述。
| 接纳指数 | 描述 |
|---|---|
| 1级 | 公司重点项目不会进行混沌工程实验;只覆盖了少量的系统;公司内部基本上对混沌工程实验了解甚少;极少数工程师尝试且偶尔进行混沌工程实验。 |
| 2级 | 混沌工程实验获得正式授权和批准;由工程师兼职进行混沌工程实验;公司内部有多个项目有兴趣参与混沌工程实验;极少数重要系统会不定期进行混沌工程实验。 |
| 3级 | 成立了专门的混沌工程团队;事件响应已经集成在混沌工程实验框架中以创建对应的回归实验;大多数核心系统都会定期进行混沌工程实验;偶尔以Game Day的形式,对实验中发现的故障进行复盘验证。 |
| 4级 | 公司所有核心系统都会经常进行混沌工程实验;大多数非核心系统也都会经常进行混沌工程实验;混沌工程实验是工程师日常工作的一部分;所有系统默认都要参与混沌工程实验,不参与需要特殊说明。 |
混沌工程实验的可行性路线图
把当前项目进行成熟度等级和接纳指数的评估,将两者的结果合并放在一张图上,就可构建出类似于魔力象限的坐标轴。这不仅可以了解当前项目进行混沌工程实验的可行性,同时还可以与其他项目进行差异对比。此外,根据之前所讨论的混沌工程实验目标,设定想要达到的成熟度等级和接纳程度,便获得可行性路线图,了解自身努力的方向。

综上,本文是混沌工程专栏的第二篇,在此我们弄清楚了混沌工程实验的目标,并通过对混沌工程的成熟度等级和接纳指数的深入描述,探讨了如何通过上述可行性评估模型来衡量混沌工程实验的可行性、有效性和安全性。
以上是关于云上混沌工程实践之可行性评估篇-收集的主要内容,如果未能解决你的问题,请参考以下文章