什么是消息队列啊?
Posted ibigboy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是消息队列啊?相关的知识,希望对你有一定的参考价值。
大家好,我是walking,今天我们来聊一聊什么是消息队列,为什么要用消息队列,有什么好处呢?同样使用消息队列有什么坏处?
我们的项目要引入消息队列了,之前只是听说使用消息队列有什么什么好处,感觉挺高大上的,自己也只是看过各种消息队列的技术文章,流行的几种消息队列中间件也都自己搭建过,写过demo,所以现在要引入消息队列了,好激动啊,要用新技术了。出于大家都不了解消息队列,所以要在项目组内部对各位开发进行一个简单的科普。以下就是我自己整理的消息队列的科普知识,希望对大家有所帮助。
一、消息队列是个什么东东?
在使用一门新技术之前我们肯定要搞明白这是个什么东西。消息队列这个词想必大家都很熟悉,不管你用没用过,你应该听过吧?即便你没有听过消息队列,那队列你应该听说过,所以在学习什么是消息队列之前我们先来说一下什么是队列(queue)。队列可以说是一个数据结构,可以存储数据,如下图,我们从右侧(队尾)插入元素(入队),从队头获取元素(出队)。

对于这样一个数据结构想必大家都不陌生,Java中也实现了好多队列。例如,创建线程池时我们需要一个阻塞队列,JDK的Lock机制也需要队列。
了解了队列之后,我们来看一下什么是消息队列,消息队列就是我们常说的MQ,英文叫Message Queue,是作为一个单独的中间件产品存在的,独立部署。
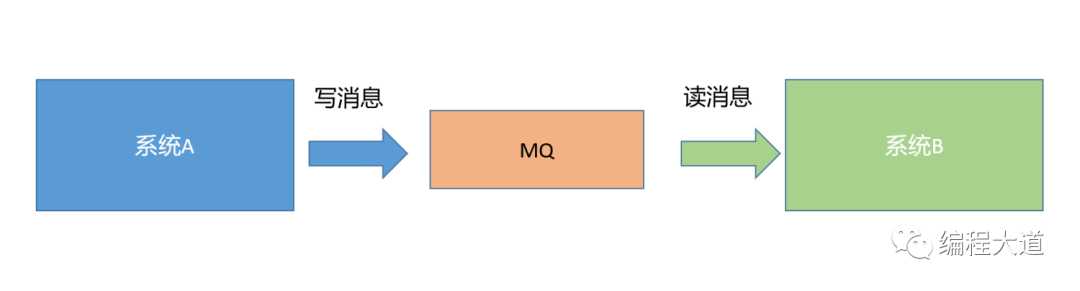
二、为什么要用消息队列呢?
引入一个新的技术产品,肯定是要考虑为什么要用它呢?消息队列也不列外,说到为什么要用,还真是因为它能在某些场景下发挥奇效。例如:解耦,异步,削峰,这三个词你也听说过吧,那下面就就从这三个好处出发,讲讲到底什么是解耦,异步,削峰。
2.1 解耦
解耦都不陌生吧,就是降低耦合度,我们都知道Spring的主要目的是降低耦合,那MQ又是如何解耦的呢?如下图所示,系统A是一个关键性的系统,产生数据后需要通知到系统B和系统C做响应的反应,三个系统都写好了,稳定运行;某一天,系统D也需要在系统A产生数据后作出反应,那就得系统A改代码,去调系统D的接口,好,改完了,上线了。假设过了某段时间,系统C因为某些原因,不需要作出反应了,不要系统A调它接口了,就让系统A把调接口的代码删了,系统A的负责人可定会很烦,改来改去,不停的改,不同的测,还得看会不会影响系统B,系统D。没办法,这种架构下,就是这样麻烦。
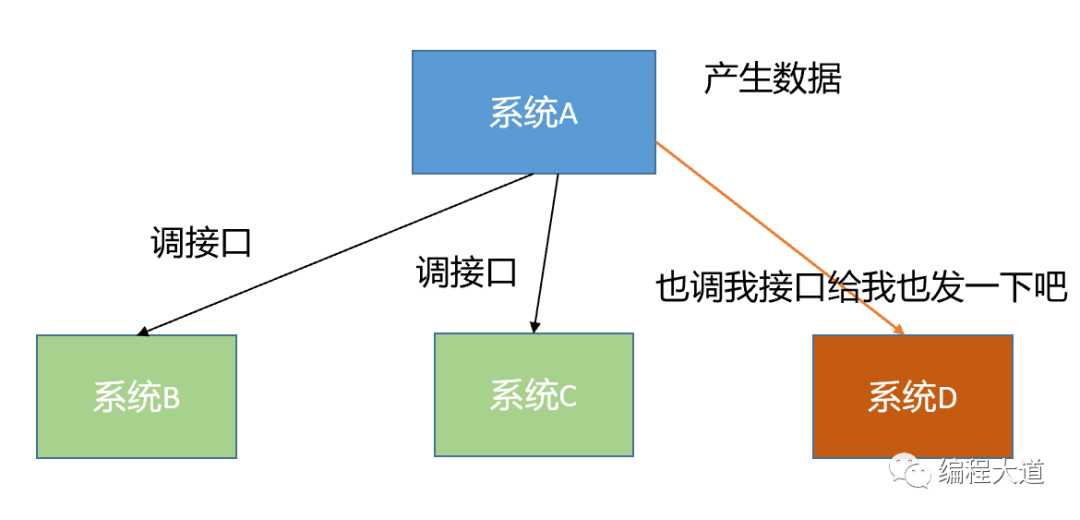
而且这样还没考虑异常情况,假如系统A产生了数据,本来需要实时调系统B的,结果系统B宕机了或重启了,没调成功咋办,或者调用返回失败怎么办,系统A是不是要考虑要不要重试?还要开发一套重试机制,系统A要考虑的东西也太多了吧。
那如果使用MQ会是什么样的效果呢?如下图所示,系统A产生数据之后,将该数据写到MQ中,系统A就不管了,不用关心谁消费,谁不消费,即使是再来一个系统E,或者是系统D不需要数据了,系统A也不需要做任何改变,而系统B、C、D是否消费成功,也不用系统A去关心,通过这样一种机制,系统A和其他各系统之间的强耦合是不是一下子就解除了,系统A是不是一下子清爽了很多?
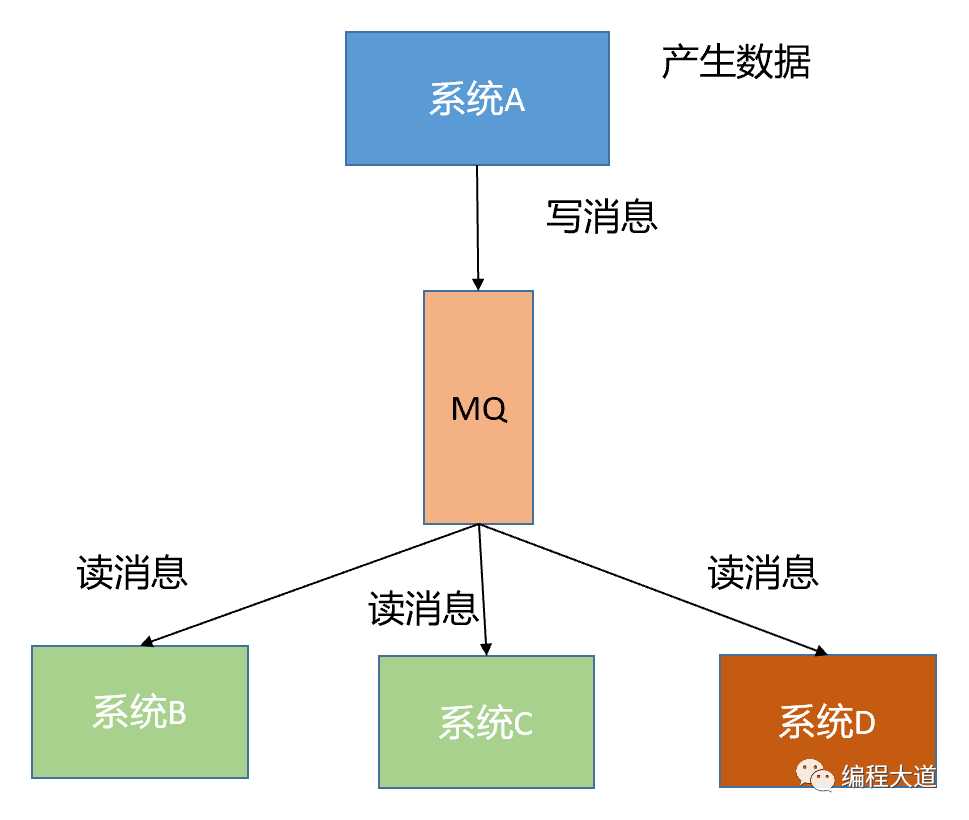
2.2 异步
同步/异步大家都知道吧,举个例子,你早上起床后边吃早饭边看电视(异步),而不是吃完饭再看电视(同步)。在上述例子中,没有使用MQ时,系统A要调系统B、C、D的接口,我们看一下下面的伪代码想一下是不是这样
//系统A中的代码 Data newData = productData();//系统A经过一些逻辑处理后产生了数据,耗时200ms Response responseB = callSysB(newData);//系统A调系统B接口发送数据,耗时300ms Response responseC = callSysC(newData);//系统A调系统C接口发送数据,耗时300ms Response responseD = callSysD(newData);//系统A调系统D接口发送数据,耗时300ms
这样系统A的用户做完这个操作就需要等待:
200ms+300ms+300ms+300ms=1100ms=1.1s
点个按钮等一秒多,用户体验得多差啊,客户可能就会因此而流失掉。
假设使用了MQ呢?系统A就只需要把产生的数据放到MQ里就行了,就可以立马返回用户响应。伪代码如下:
//系统A中的代码 Data newData = productData();//系统A经过一些逻辑处理后产生了数据,耗时200ms writeDateToMQ(newData);//往MQ里写消息,耗时50ms
这样系统A的用户做完这个操作就只需要等待200ms+50ms=250ms,给用户的感觉就是一瞬间的事儿,点一下就好了,用户体验提升了很多。系统A把数据写到MQ里,系统B、C、D就自己去拿,慢慢消费就行了。一般就是一些时效性要求不高的操作,比如下单成功系统A调系统B发下单成功的短信,短信晚几秒发都是OK的。
2.3 削峰
削峰是什么意思?大家都知道对于大型互联网公司,典型的就是电商,时不时的搞一些大促,流量会高于平时几十倍几百倍...例如,平时下单也就每秒一二十单,对于现有的架构来说完全不是事儿,那大促的时候呢?每秒就有可能举个例子是5000单,如果说下单要实时操作数据库,假设数据库最大承受一秒2000,那大促的时候一秒5000的话数据库肯定会被打死的,数据库一挂导致系统直接不可用,那是多么严重的事情。
所以在这种场景下使用MQ完美的解决了这个问题,下游系统下单时只需要往MQ里发消息,我的订单系统可以设定消费的频率,比如每秒我就消费2000个消息(在数据库的可承受范围),不管你下游系统每秒下多少单,我都保持这个速率,既不会影响我订单系统的数据库,也不影响你下游系统的下单操作,很好的保护了系统,也提高了下单的吞吐量。
我们都知道,大促也就几分钟的事,往多了说是几个小时吧,咱就说4个小时吧,每秒5000,4小时7200W单往MQ里写,订单系统每秒消费2000单,大促过后,MQ里会积压4320W个消息,剩下的就慢慢消费呗。当然了,大促的时候肯定会临时申请加机器的,每秒消费不止2000。
这就是削峰,将某一段时间的超高流量分摊到更长的一段时间内去消化,避免了流量洪峰击垮系统。
三、使用消息队列需要注意什么问题?
既然上面已经说了MQ有那么多好处,那他肯定也会有不好的地方吧?这是必然的,任何事物都是有两面性的,没有十全十美的东西。下面就来说说MQ的缺点或要注意的问题。
缺点:
1、增加了系统的复杂性。
原来系统A、 B、C、D之间就直接用接口调用的方式,现在引进了MQ要考虑很多MQ的问题,如:消息会不会丢失?积压了很多消息咋办?MQ满了咋办?消息会不会重复?怎么保证消息顺序性等问题。
2、降低了系统的可用性。
各个系统之间强依赖MQ,MQ的可用性就变得非常的关键,我还要额外的去保证MQ的高可用,担心他会挂了。
3、一致性问题。
如:多个系统依赖一个系统发送的消息,如果部分系统消费成功而部分系统消费失败,可能会导致数据不一致的问题。
四、总结
今天我们主要讲了3个问题:1)什么是消息队列,2)使用消息队列有什么好处/为何要使用消息队列,3)使用消息队列会带来什么问题/需要注意什么问题。现在你是不是对消息队列有了一定的认识呢?
如果对你有所帮助的话,希望不要吝啬你的赞哦,欢迎关注公众号@编程大道

附言
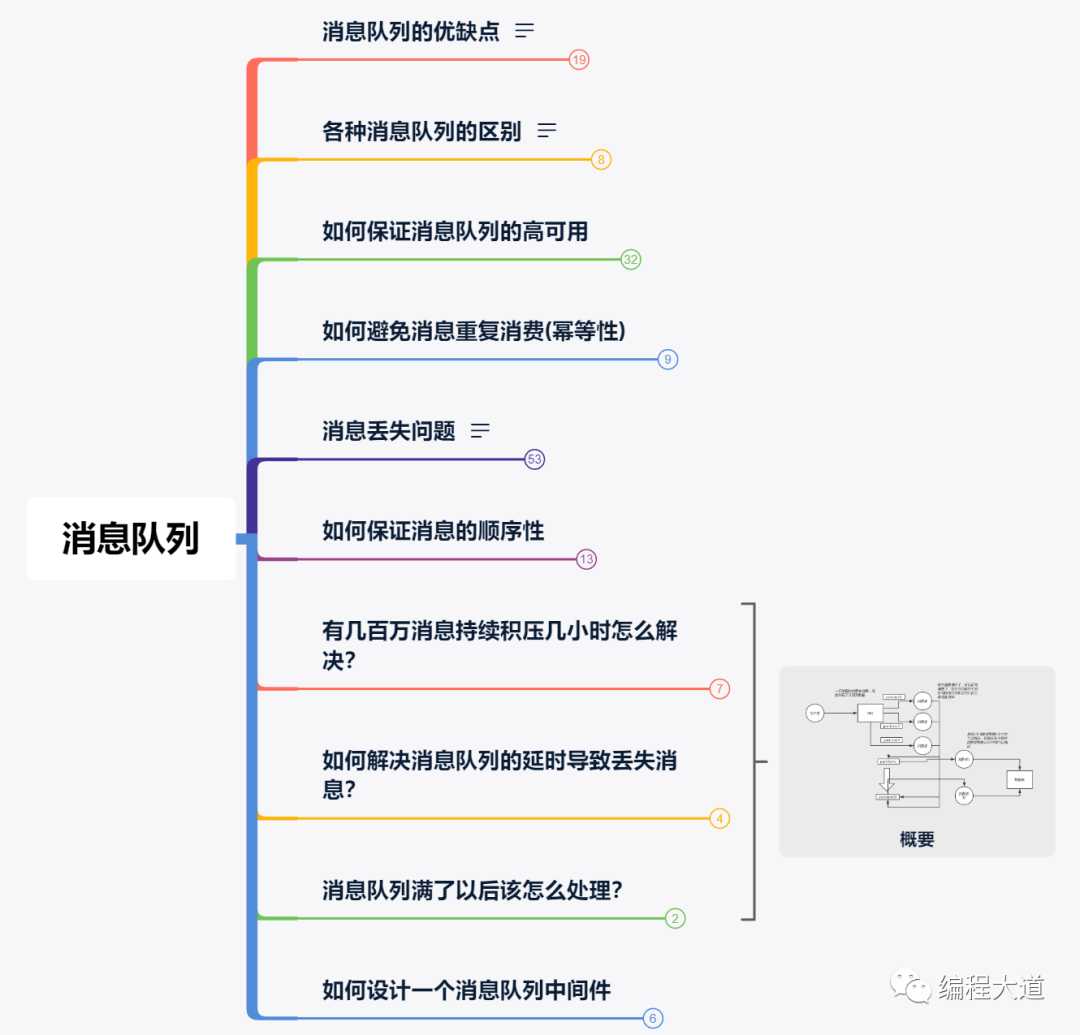
这里整理了关于MQ的知识点的一个脑图,以及上述消息队列的缺点,特别是对诸如消息会不会丢失?积压了很多消息咋办?MQ满了咋办?消息会不会重复?怎么保证消息顺序性等问题...的解决方案,需要的小伙伴公众号后台回复:MQ 即可下载高清脑图
以上是关于什么是消息队列啊?的主要内容,如果未能解决你的问题,请参考以下文章