DataStreamUtils 连续keyBy 优化
Posted springmoon-venn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DataStreamUtils 连续keyBy 优化相关的知识,希望对你有一定的参考价值。
经常会有这样的业务需求,需要对一个 stream 连续分区,比如:
source .keyBy(0) .process(new TmpKeyedProcessFunction2) .keyBy(0) .process(new TmpKeyedProcessFunction2) .keyBy(0) .process(new TmpKeyedProcessFunction2)
注: keyBy 算子有 shuffle
org.apache.flink.streaming.api.scala.KeyedStream 的 process 方法声明如下:
@PublicEvolving def process[R: TypeInformation]( keyedProcessFunction: KeyedProcessFunction[K, T, R]): DataStream[R] = { if (keyedProcessFunction == null) { throw new NullPointerException("KeyedProcessFunction must not be null.") } asScalaStream(javaStream.process(keyedProcessFunction, implicitly[TypeInformation[R]])) }
从 KeyedStream 的 process 源码可以看到,process 方法后, KeyedStream 变为 DataStream,如果还想在后面使用 process 方法,就只能使用 DataStream 的 process 方法。如果算子中不使用状态,是无所谓 key 或 非 key 的。但是想在process 方法中使用键控状态,就需要将 stream 转为 KeyedStream,所以就有了前面的连续 keyBy。
算子执行图如下:

对应官网地址: https://ci.apache.org/projects/flink/flink-docs-master/zh/dev/stream/experimental.html
DataStreamUtils#reinterpretAsKeyedStream API 的作用是: re-interpret a pre-partitioned data stream as a keyed stream to avoid shuffling. (讲预分区的流重新解释为键控流)
官网案例如下:
val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) val source = ... new DataStreamUtils(source).reinterpretAsKeyedStream((in) => in) .timeWindow(Time.seconds(1)) .reduce((a, b) => a + b) .addSink(new DiscardingSink[Int]) env.execute()
官网的例子感觉不出来转为键控流,看下面的例子:
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val topic = "randon_string" val kafkaSource = new FlinkKafkaConsumer[String](topic, new SimpleStringSchema(), Common.getProp) val source: DataStream[(String, String, String)] = env.addSource(kafkaSource) .map(str => { val arr = str.split(",") (arr(0), arr(1), arr(2)) }) val keyStream0 = source.keyBy(0) .process(new TmpKeyedProcessFunction2) val keyedStream = new DataStreamUtils(keyStream0) .reinterpretAsKeyedStream(element => element._1) .process(new TmpKeyedProcessFunction("11")) val keyedStream2 = new DataStreamUtils(keyedStream) .reinterpretAsKeyedStream(element => element._1) .process(new TmpKeyedProcessFunction3("22")) env.execute("multiKeyBy")
这样就能很清晰的看出来,讲一个 DataStream 解释为 KeyedStream 了
执行图如下:
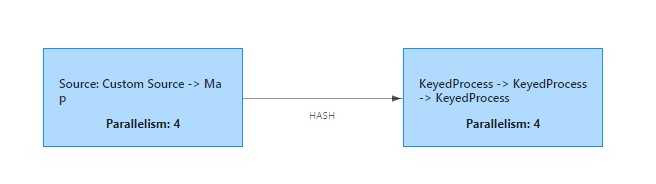
警告:重新解释的 DataStream 必须已经完全按照 Flink 的 keyBy 将数据按随机顺序进行分区的相同方式进行了预分区。 如: key-group 分配。 (来自官网)
如果解释的流不是预分区的,在使用状态的时候,不同分区的数据进来,会报NullPointException
完整代码稍后会放到 github 上 (https://github.com/springMoon/flink-rookie)
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文

以上是关于DataStreamUtils 连续keyBy 优化的主要内容,如果未能解决你的问题,请参考以下文章