电影数据集
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了电影数据集相关的知识,希望对你有一定的参考价值。
电影数据集
The MovieLens Dataset
有许多数据集可用于推荐研究。其中,MovieLens数据集可能是最受欢迎的数据集之一。MovieLens是一个基于web的非商业电影推荐系统。创建于1997年,由明尼苏达大学的一个研究实验室GroupLens管理,目的是为了研究目的收集电影分级数据。MovieLens的数据对于包括个性化推荐和社会心理学在内的一些研究都是至关重要的。
1. Getting the Data
MovieLens数据集由GroupLens网站托管。有几个版本可用。将使用MovieLens 100K数据集。此数据集包括10万收视率,从1星到5星,从1682部电影的943名用户。已经被清理,这样每个用户至少有20部电影。一些简单的人口统计信息,如年龄、性别、用户的类型和项目也可用。可以下载ml-100k.zip并提取u.data文件,其中包含所有10万csv格式的评分。文件夹中还有许多其文件,每个文件的详细说明可以在数据集的自述文件中找到。首先,让导入运行本节实验所需的包。
from d2l import mxnet as d2l
from mxnet import gluon, np
import os
import pandas as pd
然后,下载MovieLens 100k数据集并将交互作为DataFrame加载。
#@save
d2l.DATA_HUB[‘ml-100k‘] = (
‘http://files.grouplens.org/datasets/movielens/ml-100k.zip‘,
‘cd4dcac4241c8a4ad7badc7ca635da8a69dddb83‘)
#@save
def read_data_ml100k():
data_dir = d2l.download_extract(‘ml-100k‘)
names = [‘user_id‘, ‘item_id‘, ‘rating‘, ‘timestamp‘]
data = pd.read_csv(os.path.join(data_dir, ‘u.data‘), ‘ ‘, names=names,
engine=‘python‘)
num_users = data.user_id.unique().shape[0]
num_items = data.item_id.unique().shape[0]
return data, num_users, num_items
2. Statistics of the Dataset
让装载数据并手动检查前五个记录。这是学习数据结构并验证是否已正确加载的有效方法。
data, num_users, num_items = read_data_ml100k()
sparsity = 1 - len(data) / (num_users * num_items)
print(‘number of users: %d, number of items: %d.‘ % (num_users, num_items))
print(‘matrix sparsity: %f‘ % sparsity)
print(data.head(5))
number of users: 943, number of items: 1682.
matrix sparsity: 0.936953
user_id item_id rating timestamp
0 196 242 3 881250949
1 186 302 3 891717742
2 22 377 1 878887116
3 244 51 2 880606923
4 166 346 1 886397596
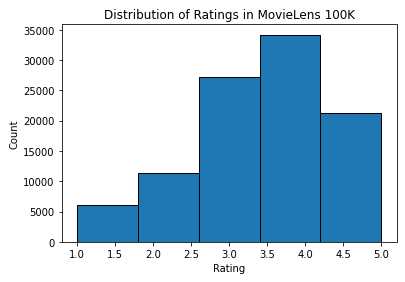
可以看到,每行由四列组成,包括“userid”1-943、“item id”1-1682、“rating”1-5和“timestamp”。可以构造一个尺寸的相互作用矩阵牛×米牛×米,其中nn和米米分别是用户数和项目数。这个数据集只记录现有的评级,所以也可以称之为评级矩阵,如果这个矩阵的值代表确切的评级,将互换使用交互矩阵和评级矩阵。评级矩阵中的大多数值是未知的,因为用户没有对大多数电影进行评级。还展示了这个数据集的稀疏性。稀疏性定义为The sparsity is defined as 1-numberofnonzeroentries/(numberofusers*numberofitems).。显然,相互作用矩阵非常稀疏(即稀疏度=93.695%)。现实世界中的数据集可能会受到更大程度的稀疏性的影响,并且一直是构建推荐系统的长期挑战。一个可行的解决方案是使用附加的附加信息,例如用户/项目特性来缓解稀疏性。然后,绘制不同评级的计数分布图。正如预期的那样,这似乎是一个正态分布,大多数评级集中在3-4。
d2l.plt.hist(data[‘rating‘], bins=5, ec=‘black‘)
d2l.plt.xlabel(‘Rating‘)
d2l.plt.ylabel(‘Count‘)
d2l.plt.title(‘Distribution of Ratings in MovieLens 100K‘)
d2l.plt.show()
3. Splitting the dataset
将数据集分成训练集和测试集。以下函数提供两种分割模式,包括随机和序列感知。在随机模式下,该函数在不考虑时间戳的情况下随机分割100k个交互,默认使用90%的数据作为训练样本,其余10%作为测试样本。在seq-aware模式中,将用户最近评估的项目和用户的历史交互作为训练集。用户历史交互根据时间戳从最旧到最新排序。此模式将在序列感知推荐部分中使用。
#@save
def split_data_ml100k(data, num_users, num_items,
split_mode=‘random‘, test_ratio=0.1):
"""Split the dataset in random mode or seq-aware mode."""
if split_mode == ‘seq-aware‘:
train_items, test_items, train_list = {}, {}, []
for line in data.itertuples():
u, i, rating, time = line[1], line[2], line[3], line[4]
train_items.setdefault(u, []).append((u, i, rating, time))
if u not in test_items or test_items[u][-1] < time:
test_items[u] = (i, rating, time)
for u in range(1, num_users + 1):
train_list.extend(sorted(train_items[u], key=lambda k: k[3]))
test_data = [(key, *value) for key, value in test_items.items()]
train_data = [item for item in train_list if item not in test_data]
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
else:
mask = [True if x == 1 else False for x in np.random.uniform(
0, 1, (len(data))) < 1 - test_ratio]
neg_mask = [not x for x in mask]
train_data, test_data = data[mask], data[neg_mask]
return train_data, test_data
请注意,除了测试集之外,在实践中使用验证集是一个很好的实践。然而,为了简洁起见,省略了这一点。在这种情况下,测试集可以被视为保留验证集。
4. Loading the data
数据集拆分后,为了方便起见,将训练集和测试集转换成列表和字典/矩阵。以下函数逐行读取数据帧并从零开始枚举用户/项的索引。然后,该函数返回用户、项目、评分和记录交互的字典/矩阵的列表。可以将反馈的类型指定为显式或隐式。
#@save
def load_data_ml100k(data, num_users, num_items, feedback=‘explicit‘):
users, items, scores = [], [], []
inter = np.zeros((num_items, num_users)) if feedback == ‘explicit‘ else {}
for line in data.itertuples():
user_index, item_index = int(line[1] - 1), int(line[2] - 1)
score = int(line[3]) if feedback == ‘explicit‘ else 1
users.append(user_index)
items.append(item_index)
scores.append(score)
if feedback == ‘implicit‘:
inter.setdefault(user_index, []).append(item_index)
else:
inter[item_index, user_index] = score
return users, items, scores, inter
之后,将上述步骤放在一起,并将在下一节中使用。结果用Dataset和DataLoader包装。注意,训练数据的最后一批DataLoader被设置为rollover模式(剩余的样本被滚动到下一个epoch),并且顺序被无序排列。
#@save
def split_and_load_ml100k(split_mode=‘seq-aware‘, feedback=‘explicit‘,
test_ratio=0.1, batch_size=256):
data, num_users, num_items = read_data_ml100k()
train_data, test_data = split_data_ml100k(
data, num_users, num_items, split_mode, test_ratio)
train_u, train_i, train_r, _ = load_data_ml100k(
train_data, num_users, num_items, feedback)
test_u, test_i, test_r, _ = load_data_ml100k(
test_data, num_users, num_items, feedback)
train_set = gluon.data.ArrayDataset(
np.array(train_u), np.array(train_i), np.array(train_r))
test_set = gluon.data.ArrayDataset(
np.array(test_u), np.array(test_i), np.array(test_r))
train_iter = gluon.data.DataLoader(
train_set, shuffle=True, last_batch=‘rollover‘,
batch_size=batch_size)
test_iter = gluon.data.DataLoader(
test_set, batch_size=batch_size)
return num_users, num_items, train_iter, test_iter
5. Summary
- MovieLens datasets are widely used for recommendation research. It is public available and free to use.
- We define functions to download and preprocess the MovieLens 100k dataset for further use in later sections.
以上是关于电影数据集的主要内容,如果未能解决你的问题,请参考以下文章