spark.mllib源码阅读-聚类算法1-KMeans
Posted 大愚若智_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark.mllib源码阅读-聚类算法1-KMeans相关的知识,希望对你有一定的参考价值。
KMeans聚类是聚类分析比较简单的一种,由于其简单、高效、易于理解实现等优点被广泛用于探索性数据分析中。
关于KMeans算法的介绍、分析的相关文章可谓汗牛充栋,留给我能写的东西并不多了,在这里,我通过罗列相关文章的方式,将涉及KMeans聚类的各方面做一个尽量详尽的总结。最后简单介绍一下Spark下KMeans聚类的实现过程。
KMeans聚类
算法原理:
关于KMeans算法的原理及单机版实现,可以参考我的博客"matlab下K-means Cluster 算法实现"。
KMeans的数据预处理及距离度量:
由于KMeans算法需要计算样本点到聚类中心点的距离,因此确定距离的度量公式和各个维度的数据归一化方式至关重要
关于数据归一化的一些基本的方法,个人博客下有几篇相关的文章做了一些总结:
关于距离度量,找了几篇相关的文章:
在选取距离度量时,还需要考虑一下几点:
1. 非距离度量不是严格意义上的度量,能否计算平均值
2. 其余的距离度量的平均值有没有实际意义
适用场景:
机器学习中选用何种算法模型进行分析建模,取决于原始数据的分布和我们对数据的认知程度。通常来讲,KMeans算法使用球形簇的数据分布,而非球形簇的数据分布一般KMeans算法会难于胜任,但这一点也不尽然,看下面这个例子:

原始数据分布
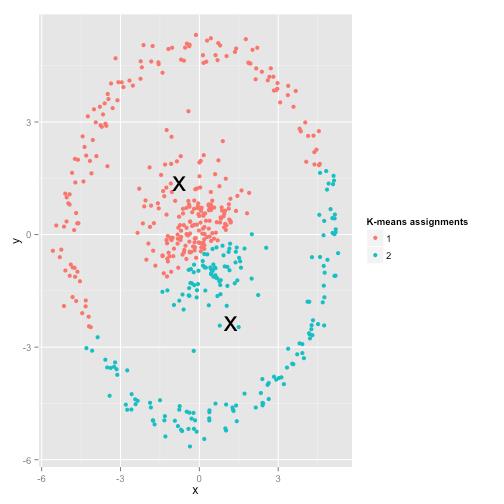
KMeans聚类结果
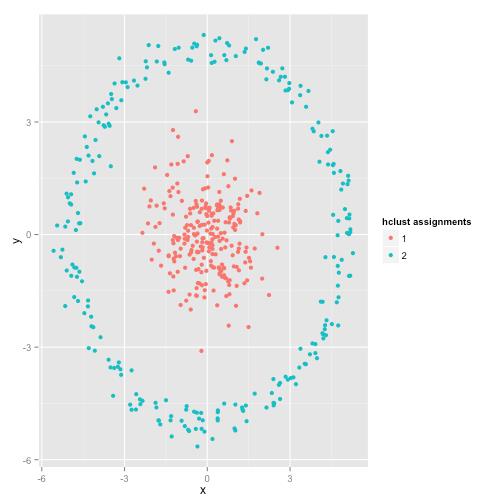
实际的聚类分布(single linkage hierachical clustering算法的聚类结果)
更多的KMeans聚类失效的例子和分析,可以参考我的博文"K均值聚类的失效性分析"
KMeans聚类的Spark实现
KMeans的实现比较简单,下面是Spark下KMmeans的类图:
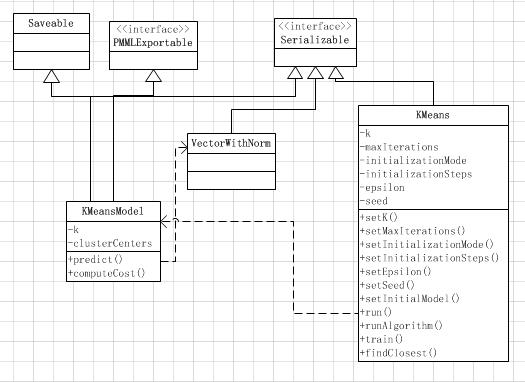
KMeansModel:
KMeansModel主要保存了完成模型训练的一些模型参数(如聚类数目K、聚类中心点数组clusterCenters)。同时提供的模型了载入载出方法。
在模型进行预测时,首先会对输入数据进行归一化,对归一化后的输入数据调用KMeans的findClosest方法来找到距输入样本点最近的聚类簇。
KMeans:
KMeans类完成模型训练,由使用者调用其train方法、训练完成后返回一个KMeansModel供使用者使用。KMeans的内部流程是使用这调用train方法,train完成参数的设定并调用run方法,run方法首先计算归一化参数并对训练数据进行归一化,其后调用runAlgorithm来进行迭代训练,归一化方式使用的是squared norms(将距离原点最远的欧几里德距离归一化为1,其余点的距离都会在0-1之间)。
下面来看看runAlgorithm的源代码,runAlgorithm进行训练的整体思路是数据分区,将聚类中心点信息广播至各个分区计算每个中心点的累计距离距离(损失),累计坐标值和计数;以聚类的索引ID作为key进行reduce, 计算整个数据集的每个中心点的累计距离距离(损失),累计坐标值和计数。
在这里用到了Spark的2个特殊的变量broadcast变量和Accumulator变量:
broadcast变量是只读变量,broadcast将broadcast变量从一个机器分发至集群的其它机器上,每个机器上都有该变量相同的副本。
Accumulator变量,Accumulator是spark提供的累加器,顾名思义,Accumulator变量只能够增加。 只有driver能获取到Accumulator的值(使用value方法),Task只能对其做增加操作(使用+=)。
broadcast由于是只读变量,使用比较简单,Accumulator则复杂一点,其使用可以参考Spark累加器(Accumulator)陷阱及解决办法。
private def runAlgorithm(
data: RDD[VectorWithNorm],
instr: Option[Instrumentation[NewKMeans]]): KMeansModel =
val sc = data.sparkContext
//初始化聚类中心点
val centers = initialModel match
case Some(kMeansCenters) =>
kMeansCenters.clusterCenters.map(new VectorWithNorm(_))
case None =>
if (initializationMode == KMeans.RANDOM)
initRandom(data)
else
initKMeansParallel(data)
var converged = false
var cost = 0.0
var iteration = 0
val iterationStartTime = System.nanoTime()
instr.foreach(_.logNumFeatures(centers.head.vector.size))
//整体思路是数据分区,将聚类中心点信息广播至各个分区
//计算每个中心点的累计距离距离(损失),累计坐标值和计数
//以聚类的索引ID作为key进行reduce, 计算整个数据集的每个中心点的累计距离距离(损失),累计坐标值和计数
while (iteration < maxIterations && !converged)
val costAccum = sc.doubleAccumulator
val bcCenters = sc.broadcast(centers)//将类中心广播至各个分区
// Find the sum and count of points mapping to each center
val totalContribs = data.mapPartitions points =>
val thisCenters = bcCenters.value
val dims = thisCenters.head.vector.size
val sums = Array.fill(thisCenters.length)(Vectors.zeros(dims))
val counts = Array.fill(thisCenters.length)(0L)
points.foreach point =>
val (bestCenter, cost) = KMeans.findClosest(thisCenters, point)//找到距离point最近的聚类中心 并计算损失函数
costAccum.add(cost)//损失函数值累积
val sum = sums(bestCenter)//类中心的坐标值
axpy(1.0, point.vector, sum)//1.0*point + sum,坐标累积
counts(bestCenter) += 1//计数累积
counts.indices.filter(counts(_) > 0).map(j => (j, (sums(j), counts(j)))).iterator
.reduceByKey case ((sum1, count1), (sum2, count2)) =>
axpy(1.0, sum2, sum1)//sum1 = sum1 + sum2
(sum1, count1 + count2) // count = count1 + count2 将各个分区的结果累加
.collectAsMap()
bcCenters.destroy(blocking = false)//bcCenters广播变量是驻留在内存中的,不用的话将其销毁
// Update the cluster centers and costs
converged = true
totalContribs.foreach case (j, (sum, count)) =>
scal(1.0 / count, sum)//sum = sum/count 计算新的聚类中心点
val newCenter = new VectorWithNorm(sum)
if (converged && KMeans.fastSquaredDistance(newCenter, centers(j)) > epsilon * epsilon) //判断此次聚类后是否收敛
converged = false
centers(j) = newCenter//更新聚类中心点至centers
cost = costAccum.value
iteration += 1
new KMeansModel(centers.map(_.vector))
Spark下KMeans的数据归一化方式和距离度量都是硬编码,距离度量采用了欧几里德距离。实际使用,采用欧几里德进行距离度量的场景并不多,有定制化的需求时,需要将数据归一化方式和距离公式重写来完成特殊的需求。
以上是关于spark.mllib源码阅读-聚类算法1-KMeans的主要内容,如果未能解决你的问题,请参考以下文章