Sequence Model-week2编程题1(词向量的运算)
Posted douzujun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sequence Model-week2编程题1(词向量的运算)相关的知识,希望对你有一定的参考价值。
词向量运算(Operations on word vectors)
因为词嵌入的训练是非常耗资源的,所以ML从业职 都是 选择加载训练好 的 词嵌入数据集。
任务:
-
导入 预训练词向量,使用余弦相似性(cosine similarity)计算相似度
-
使用词嵌入来解决 “Man is to Woman as King is to __.” 之类的 词语类比问题
-
修改词嵌入 来减少它们的性别歧视
import numpy as np
from w2v_utils import *
导入词向量,这个任务中,使用 50维的 GloVe向量 来表示单词,导入 load the word_to_vec_map.
words, word_to_vec_map = read_glove_vecs(‘data/glove.6B.50d.txt‘)
print(list(words)[:10])
print(word_to_vec_map[‘mauzac‘])
[‘1945gmt‘, ‘mauzac‘, ‘kambojas‘, ‘4-b‘, ‘wakan‘, ‘lorikeet‘, ‘paratroops‘, ‘wittkower‘, ‘messageries‘, ‘oliver‘]
[ 0.049225 -0.36274 -0.31555 -0.2424 -0.58761 0.27733
0.059622 -0.37908 -0.59505 0.78046 0.3348 -0.90401
0.7552 -0.30247 0.21053 0.03027 0.22069 0.40635
0.11387 -0.79478 -0.57738 0.14817 0.054704 0.973
-0.22502 1.3677 0.14288 0.83708 -0.31258 0.25514
-1.2681 -0.41173 0.0058966 -0.64135 0.32456 -0.84562
-0.68853 -0.39517 -0.17035 -0.54659 0.014695 0.073697
0.1433 -0.38125 0.22585 -0.70205 0.9841 0.19452
-0.21459 0.65096 ]
导入的数据:
-
words: 词汇表中单词集. -
word_to_vec_map: dictionary 映射单词到它们的 GloVe vector 表示.
Embedding vectors vs one-hot vectors
-
one-hot向量不能很好捕捉单词之间的相似度水平(每一个one-hot向量与任何其他one-hot向量有相同的欧几里得距离(Euclidean distance))
-
Embedding vector,如Glove vector提供了许多关于 单个单词含义 的有用信息
-
下面介绍如何使用 GloVe向量 来度量两个单词之间的 相似性
1. Cosine similarity
为了测量两个单词之间的相似性, 我们需要一个方法来测量两个单词的两个embedding vectors的相似性程度。 给定两个向量 (u) 和 (v), cosine similarity 定义如下:
-
(u cdot v) 是两个向量的点积(内积)
-
(||u||_2) 向量 (u) 的范数(长度)
-
( heta) 是 (u) 与 (v) 之间的夹角角度
-
余弦相似性 依赖于 (u) and (v) 的角度.
- 如果 (u) 和 (v) 很相似, 那么 (cos( heta)) 越接近1.
- 如果 (u) 和 (v) 不相似, 那么 (cos( heta)) 得到一个很小的值.
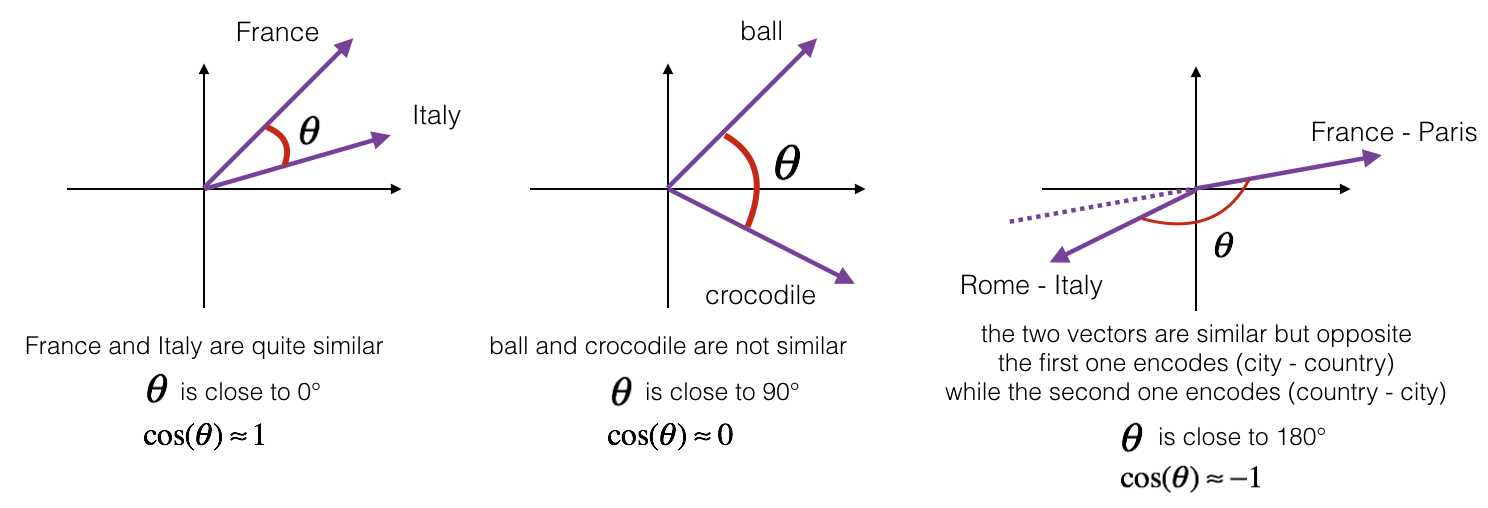
Exercise: 实现函数 cosine_similarity() 来计算两个词向量之间的 相似性.
Reminder: (u) 的范式定义为 (||u||_2 = sqrt{sum_{i=1}^{n} u_i^2})
提示: 使用 np.dot, np.sum, or np.sqrt 很有用.
以上是关于Sequence Model-week2编程题1(词向量的运算)的主要内容,如果未能解决你的问题,请参考以下文章