Alertmanager 安装与使用
Posted xiao987334176
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Alertmanager 安装与使用相关的知识,希望对你有一定的参考价值。
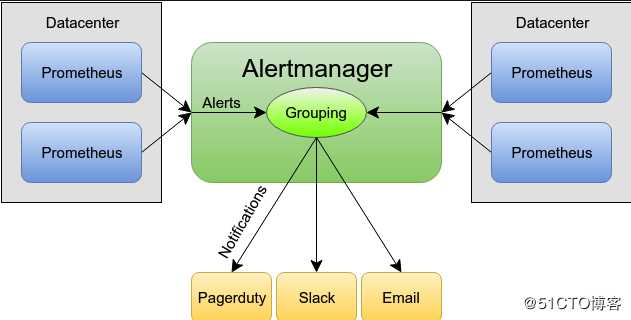
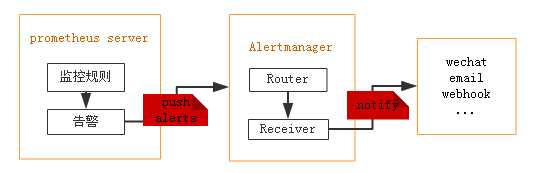
一、概述
二、AlertManager 配置邮件告警
AlertManager 默认配置文件为 alertmanager.yml,在容器内路径为 /etc/alertmanager/alertmanager.yml,默认配置如下:
global: resolve_timeout: 5m route: group_by: [‘alertname‘] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: ‘web.hook‘ receivers: - name: ‘web.hook‘ webhook_configs: - url: ‘http://127.0.0.1:5001/‘ inhibit_rules: - source_match: severity: ‘critical‘ target_match: severity: ‘warning‘ equal: [‘alertname‘, ‘dev‘, ‘instance‘]
简单介绍一下主要配置的作用:
global: 全局配置,包括报警解决后的超时时间、SMTP 相关配置、各种渠道通知的 API 地址等等。
route: 用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
receivers: 配置告警消息接受者信息,例如常用的 email、wechat、slack、webhook 等消息通知方式。
inhibit_rules: 抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的警报(目标)。
自定义邮件模板
AlertManager 支持自定义邮件模板配置的,创建数据目录。
mkdir -p /data/alertmanager/template mkdir -p /data/alertmanager/storage chmod 777 -R /data/alertmanager/storage
新建一个模板文件 email.tmpl
vi /data/alertmanager/template/email.tmpl
内容如下:
{{ define "email.from" }}11111111@qq.com{{ end }}
{{ define "email.to" }}22222222@qq.com{{ end }}
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2019-08-04 16:58:15" }} <br>
=========end==========<br>
{{ end }}
{{ end }}
说明:
define 用来定义变量,配置3个变量,分别是:email.from、email.to、email.to.html ,可以在 alertmanager.yml 文件中直接配置引用。
这里 email.to.html 就是要发送的邮件内容,支持 Html 和 Text 格式。为了显示好看,采用 Html 格式简单显示信息。
{{ range .Alerts }} 是个循环语法,用于循环获取匹配的 Alerts 的信息,下边的告警信息跟上边默认邮件显示信息一样,只是提取了部分核心值来展示。
基于docker安装
编辑配置文件,配置一下使用 Email 方式通知报警信息,这里以 QQ 邮箱为例,
vi /data/alertmanager/alertmanager.yml
内容如下:
# 全局配置项 global: resolve_timeout: 5m #超时,默认5min #邮箱smtp服务 smtp_smarthost: ‘smtp.qq.com:465‘ smtp_from: ‘11111111@qq.com‘ smtp_auth_username: ‘11111111@qq.com‘ smtp_auth_password: ‘123456‘ smtp_require_tls: false # 定义模板信息 templates: - ‘template/*.tmpl‘ # 路径 # 路由 route: group_by: [‘alertname‘] # 报警分组依据 group_wait: 10s #组等待时间 group_interval: 10s # 发送前等待时间 repeat_interval: 1h #重复周期 receiver: ‘mail‘ # 默认警报接收者 # 警报接收者 receivers: - name: ‘mail‘ #警报名称 email_configs: - to: ‘{{ template "email.to" . }}‘ #接收警报的email html: ‘{{ template "email.to.html" . }}‘ # 模板 send_resolved: true # 告警抑制 inhibit_rules: - source_match: severity: ‘critical‘ target_match: severity: ‘warning‘ equal: [‘alertname‘, ‘dev‘, ‘instance‘]
说明:
全局配置:
{{ template "email.from" . }} 意思是,从/data/alertmanager/template文件夹中,引入变量email.from
注意:smtp_require_tls: false,默认是true。一定要改成false才能发送邮件。
告警抑制:
抑制的功能其实就是根据label进行去重的操作,上面的配置就会把warning的去掉,告警发送的时候只转发critical的。
下面的equal是合并的条件,其实就是label必须相同的才可以进行抑制。这个根据需求进行相同的选择就行,一般情况alertname能满足条件。
启动服务
docker run -d -p 9093:9093 --name alertmanager --restart=always -v /data/alertmanager:/etc/alertmanager -v /data/alertmanager/storage:/alertmanager prom/alertmanager
访问网页
http://ip地址:9093
效果如下:
三、prometheus配置
配置文件
修改prometheus.yaml,我的prometheus是在docker中运行的
创建目录
mkdir -p /data/prometheus/data mkdir -p /data/prometheus/rules chmod 777 -R /data/prometheus/data
启动参数如下:
docker run -d --restart=always --name prometheus -p 9090:9090 -v /data/prometheus:/etc/prometheus -v /data/prometheus/data:/prometheus -e TZ=Asia/Shanghai prom/prometheus
/data/prometheus目录结构如下:
./
├── data
├── prometheus.yml
└── rules
├── memory_over.yml
└── node_down.yml
其中data,就是prometheus数据文件。由于文件过多,这里就不展示了。
修改文件:/data/prometheus/prometheus.yml
# Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - 192.168.31.229:9093 # Load rules once and periodically evaluate them according to the global ‘evaluation_interval‘. rule_files: - "rules/*.yml"
alerting 里面,指定Alertmanager 的地址。
rule_files 里面,指定了告警规则。
node_down.yml
groups: - name: node-up rules: - alert: node-up expr: up{job="node-exporter"} == 0 for: 15s labels: severity: 1 team: node annotations: summary: "{{ $labels.instance }} 已停止运行!" description: "{{ $labels.instance }} 检测到异常停止!请重点关注!!!"
memory_over.yml
groups: - name: example rules: - alert: NodeMemoryUsage expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 80 for: 1m labels: severity: warning annotations: summary: "{{$labels.instance}}: High Memory usage detected" description: "{{$labels.instance}}: Memory usage is above 80% (current value is:{{ $value }})"
expr 是计算公式,(1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 表示获取内存使用率。
在grafana中,就可以看到。

注意:去掉里面的 {instance=~"$node"}即可。
重启prometheus
docker restart prometheus
访问告警页面
http://ip地址:9090/alerts
效果如下:
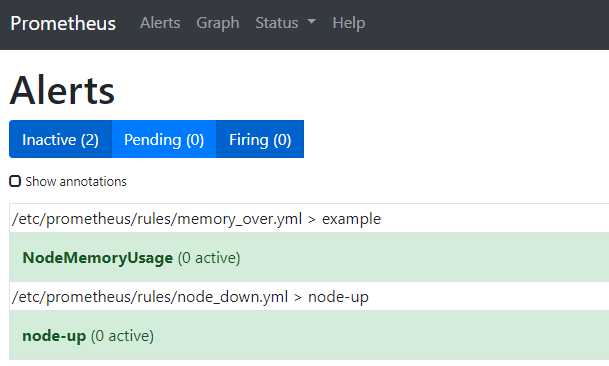
点击一下,就会显示完整的配置
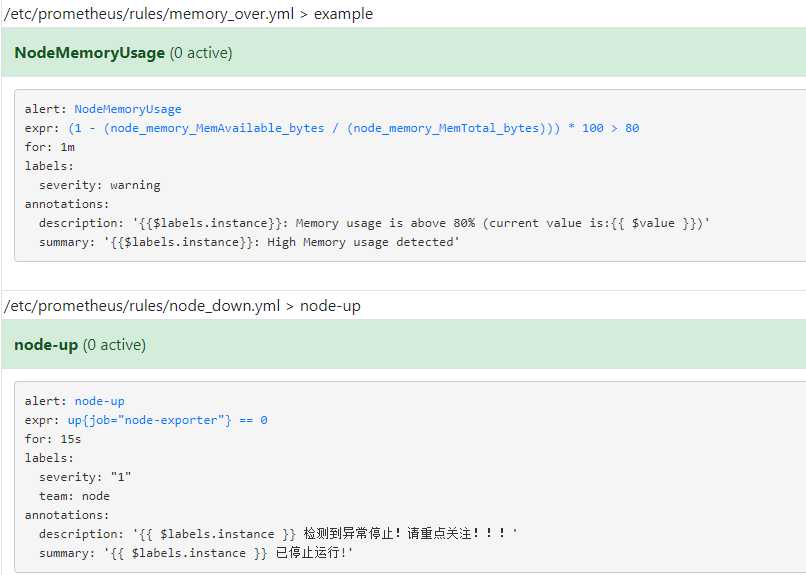
四、测试报警
这里直接修改 /data/prometheus/rules/memory_over.yml文件,告警阈值改为10
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 10
重启prometheus
docker restart prometheus
等待1分钟,会出现Pending
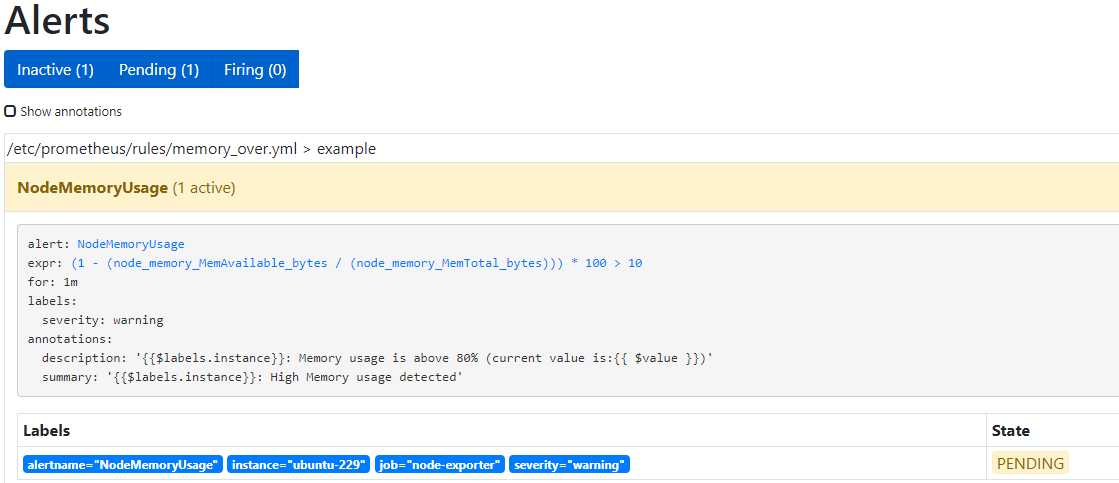
再等待一分钟,会出现Firing
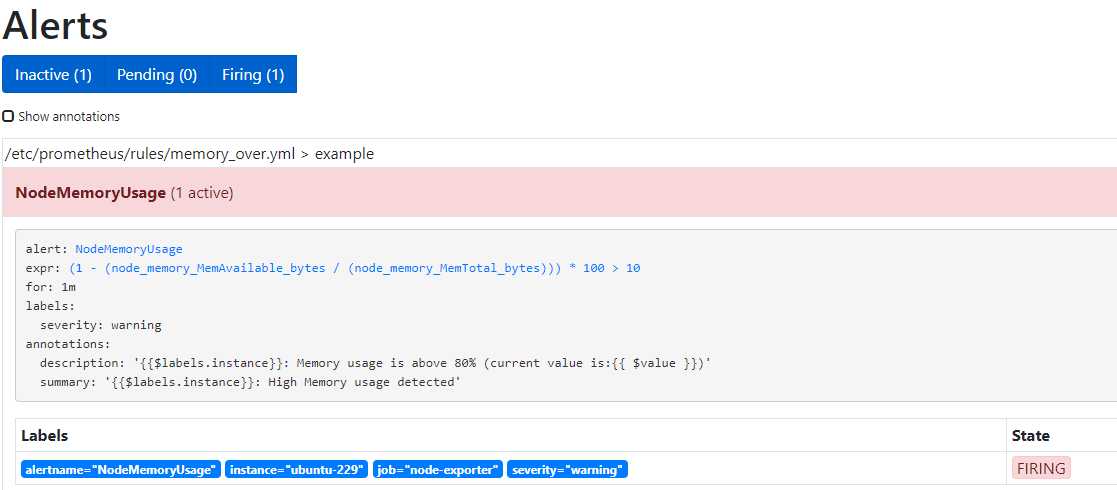
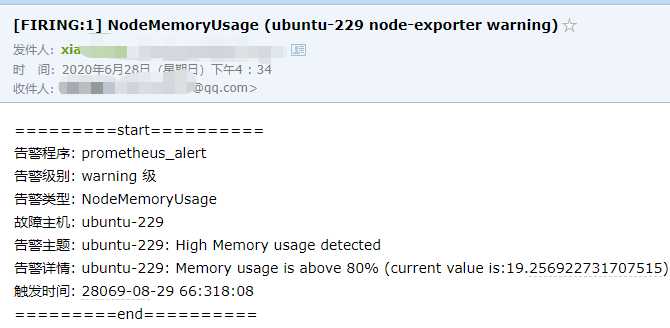
查看邮件
查看alertmanager日志
docker logs -f alertmanager
输出如下:
level=info ts=2020-06-28T08:33:46.794Z caller=coordinator.go:131 component=configuration msg="Completed loading of configuration file" file=/etc/alertmanager/alertmanager.yml level=info ts=2020-06-28T08:33:46.799Z caller=main.go:485 msg=Listening address=:9093 level=info ts=2020-06-28T08:33:48.774Z caller=cluster.go:648 component=cluster msg="gossip not settled" polls=0 before=0 now=1 elapsed=2.000472056s
如果没有收到邮件,请确保上面的配置参数正确。查看alertmanager日志,是否有报错信息。
本文参考链接:
https://www.cnblogs.com/gschain/p/11697200.html
https://blog.csdn.net/aixiaoyang168/article/details/98474494
以上是关于Alertmanager 安装与使用的主要内容,如果未能解决你的问题,请参考以下文章
alertmanager+webhook发报警邮件(使用587端口)