AWS S3概念 + 操作
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AWS S3概念 + 操作相关的知识,希望对你有一定的参考价值。
- S3出现的时间比较早,可以追溯到2003年。
- S3不同于企业网里面的存储方案,块存储或者文件存储,S3属于对象存储 Object。
- S3的总存储空间是无限大的
- S3都是存储在bucket里面。Bucket形成了S3的最高级别域名,然后bucket的名字也是global的独有的(其实就是个DNS域名)。
- S3的文件/Bucket虽然是全球唯一的,但是在创建的时候得选定一个region,一旦选定了就不能更改。而且不需要选择AZ,AWS会自己负责Avaiablity,Disaster Recovery的设计。
如上面所说,这个bucket size是无限大的。如果需要跨region复制S3数据,得使用cross region replica - S3的单个Object的大小范围 [0, 5TB]
- S3的object是由 文件数据本身 以及 metadata组成。 AWS 把数据本身看成stream of bytes
而metadata 分为system metadata 以及user metadata。 前者是为系统所用,比如说大小,MD5散列值,以及http content type。User metadata 是optional的。 - 每一个bucket里面,标记一个object的方式是通过key,当然粗看上去,这个key更像是个文件名。不同的bucket里面,可以有相同的key(文件名)。一个S3 object 是通过S3 bucket,S3 key,以及可选的version-ID 来标识de
- S3的availability是99.99%
- S3的durability 是99.999999999%(11个9) 这个可以认为是数据的完整性
- Data Consistency 数据的一致性在大型数据中心里面一直是个问题。你在某一块存储上更新了数据,而另外一块存储还没来得及更新。在同步的空档期如果从后者下载了数据,那显然数据不是最更新的了。AWS采取两种策略,read-after-write consistency以及eventual consistency。
- S3有几种不同的等级:standard,standard IA,one-zone IA,Glacier
- S3启用了版本控制,当每个object 有incremental 更新的时候,这个版本号就开始有用了
Versioning is turned on at the bucket level. Once enabled, versioning cannot be removed from a bucket; it can only be suspended. - S3可以通过ACL,bucket policy,IAM进行访问控制。
- 当你成功上传文件到S3的时候,会得到一个HTTP code 200
S3的类型,我直接贴图了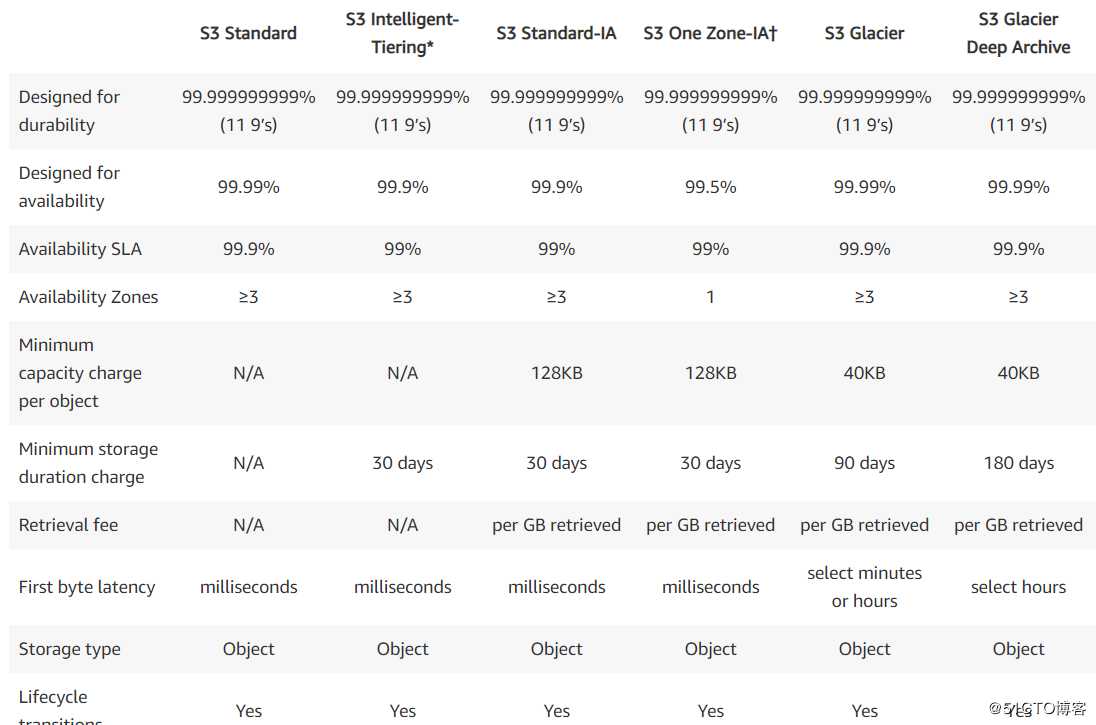
现在可以看到,书上写的RRS,reduce redundancy storage已经没有了。取而代之更多细分。那基本上class 取决于avilablility, 多少个AZ部署,取出时间有多久。
S3的收费标准
具体可以参考这个链接:https://aws.amazon.com/cn/s3/pricing/
总结起来有如下几个特点:
- 按照存储的数据多少收费,存的越多,收费越便宜。以50TB,450TB,500TB为分界线
- S3是通过http请求操作的,所有的get,post,put,list都要收费,delete不收费
- 所有进出S3的internet会被收费,只有三种情况例外:传入数据(AWS获取数据,笑而不语),同一个region的EC2和S3互相传输数据,传到cloudfront
- 管理和复制也会被收费,包括了S3清单,S3分析和S3对象标记功能
- Transfer Acceleration使用了AWS的direct connect,也是会被收费的。
这里我抄一句小茶的话:S3是对象存储、EBS是块存储。EC2可以和S3连接,方法是使用s3fs的方式挂载,或者用AWS CLI来对S3进行操作。
实验环节:
首先进入S3界面,注意右上角没有region,取而代之是global,我们可以管理全球所有的S3 buckets。所以反复强调S3只有region的概念,没有AZ。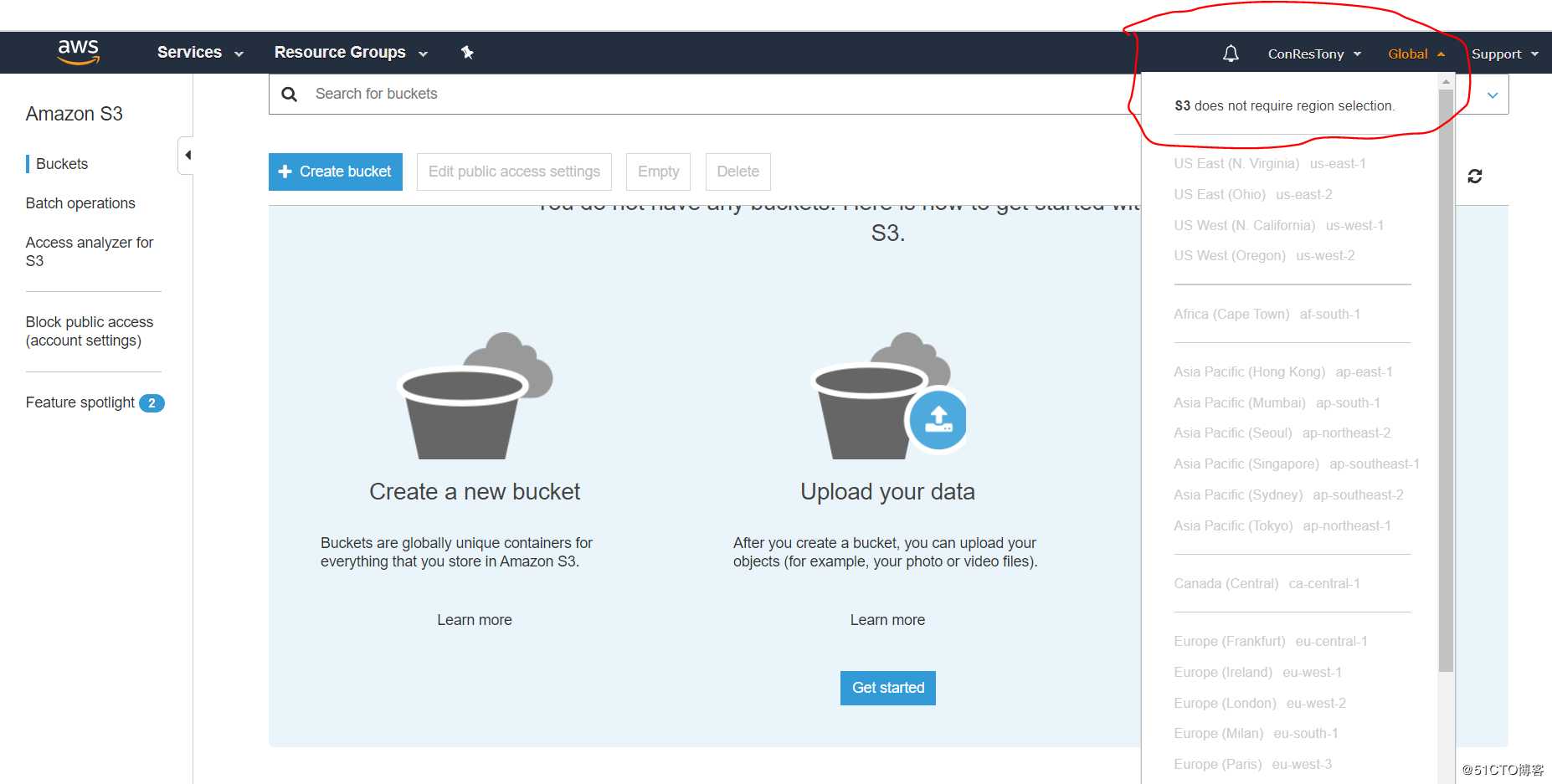
创建完bucket之后就可以上传数据了。
除了让你选择文件之外,还会让你选择storage class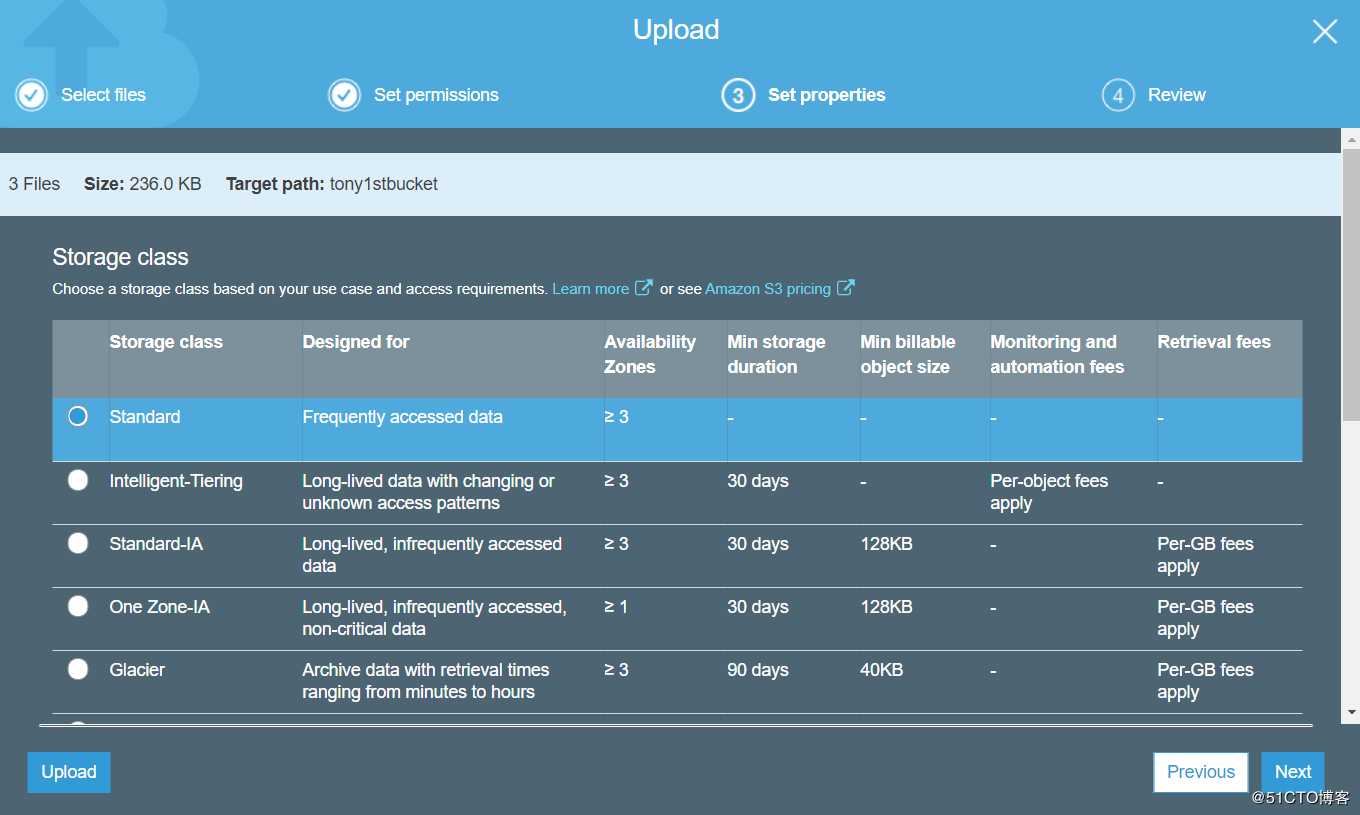
上传完之后就可以看到里面有大量的属性可以更改。大部分特性要做什么其实是一目了然的。
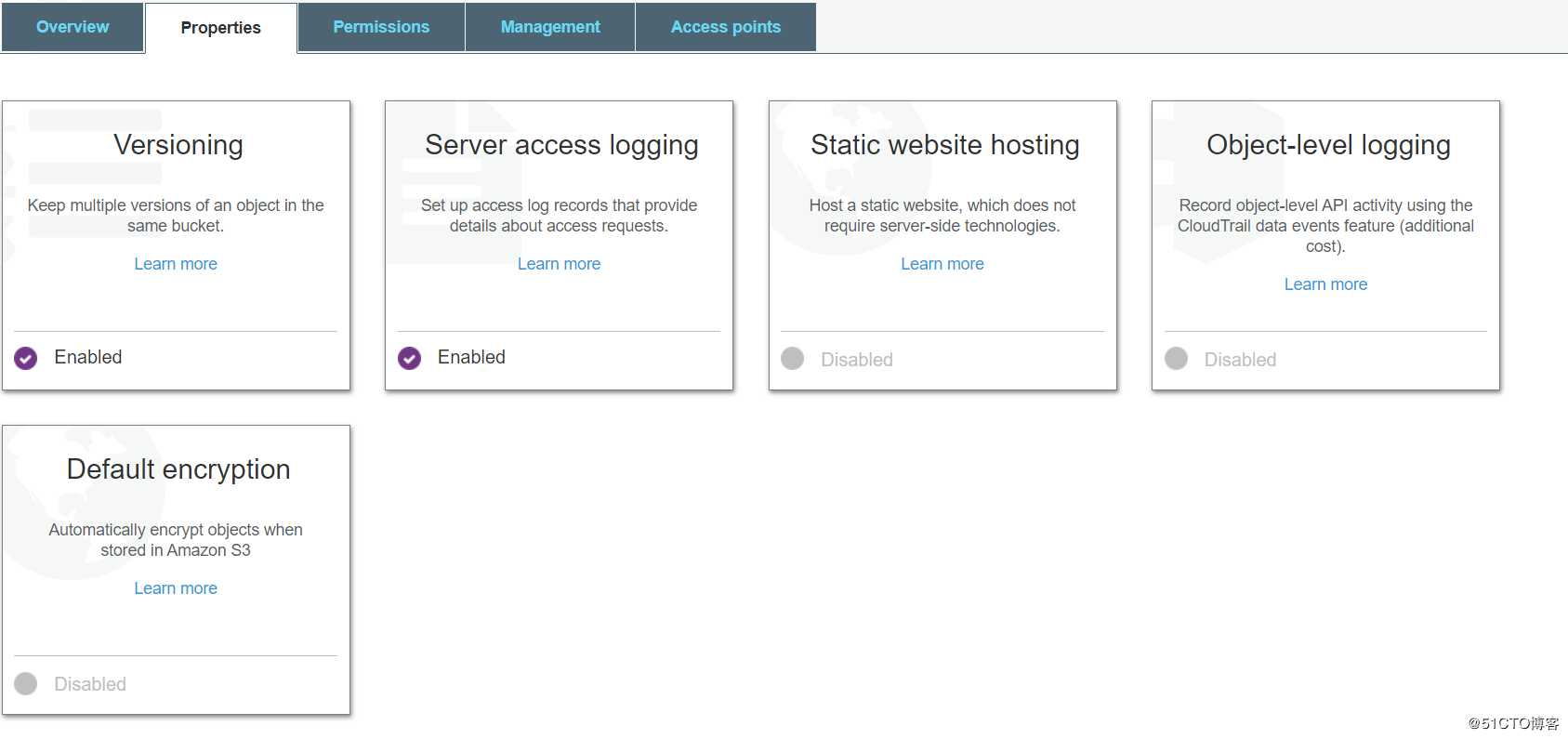
总的来说在真是的运维环境里,这种上传,并且属性的操作肯定是大家开会研究好统一的标准,通过api一起实现的。靠人手工这样操作……画面太美,不敢想象。所以学完整个AWS的课程之后,写一堆rest api的python代码也是必须的。
这里有一个注意点,虽然我们在做实验的时候,把bucket make public了,但是我过了两天回来登录的时候有一堆的垃圾日志文件。明显就是被人DDoS了。虽然不能上传,但万一你开启了忘记关掉,然后又是所有人都可以上传的。
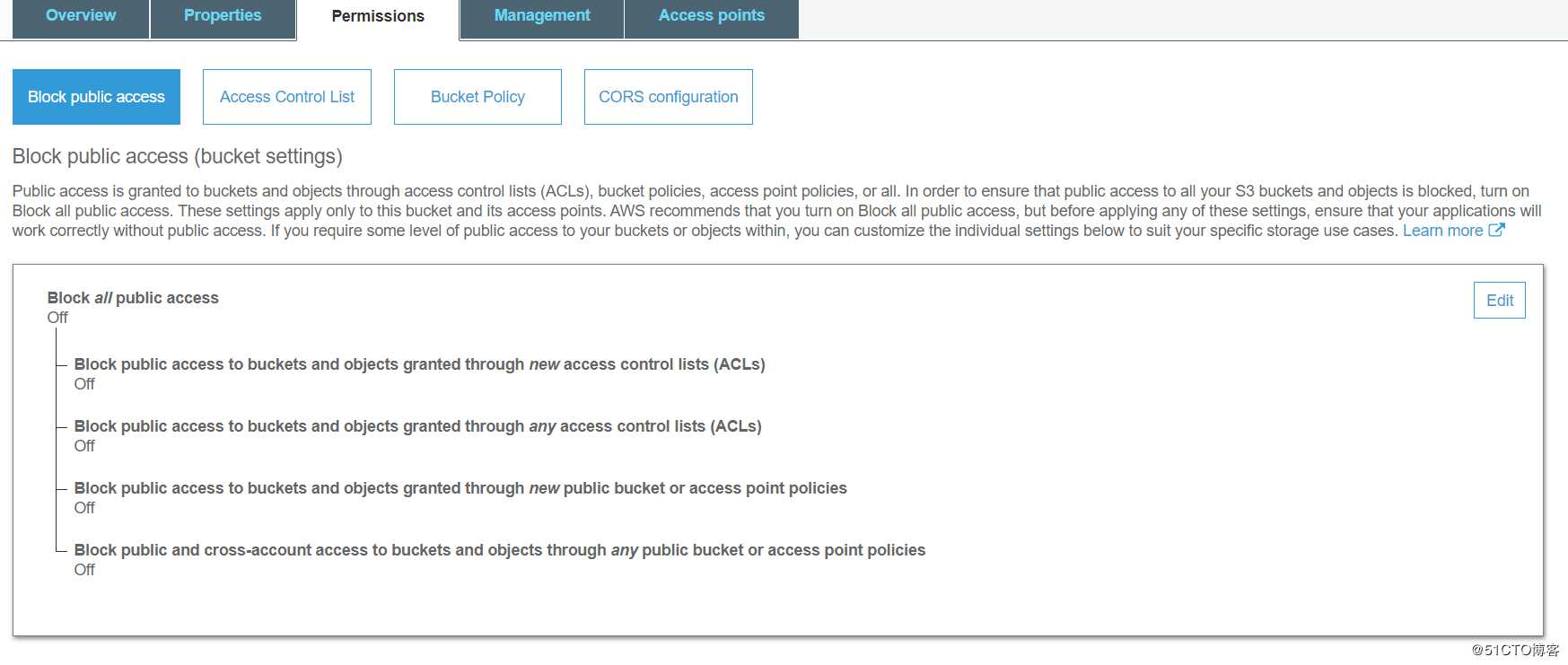
此处也注意一个他们的保护机制,如果在下面页面的地方勾选了block,那你所有的bucket和objects都是无法在公网上被访问的。或者说,这个设置会覆盖你bucket和object的block public access的操作。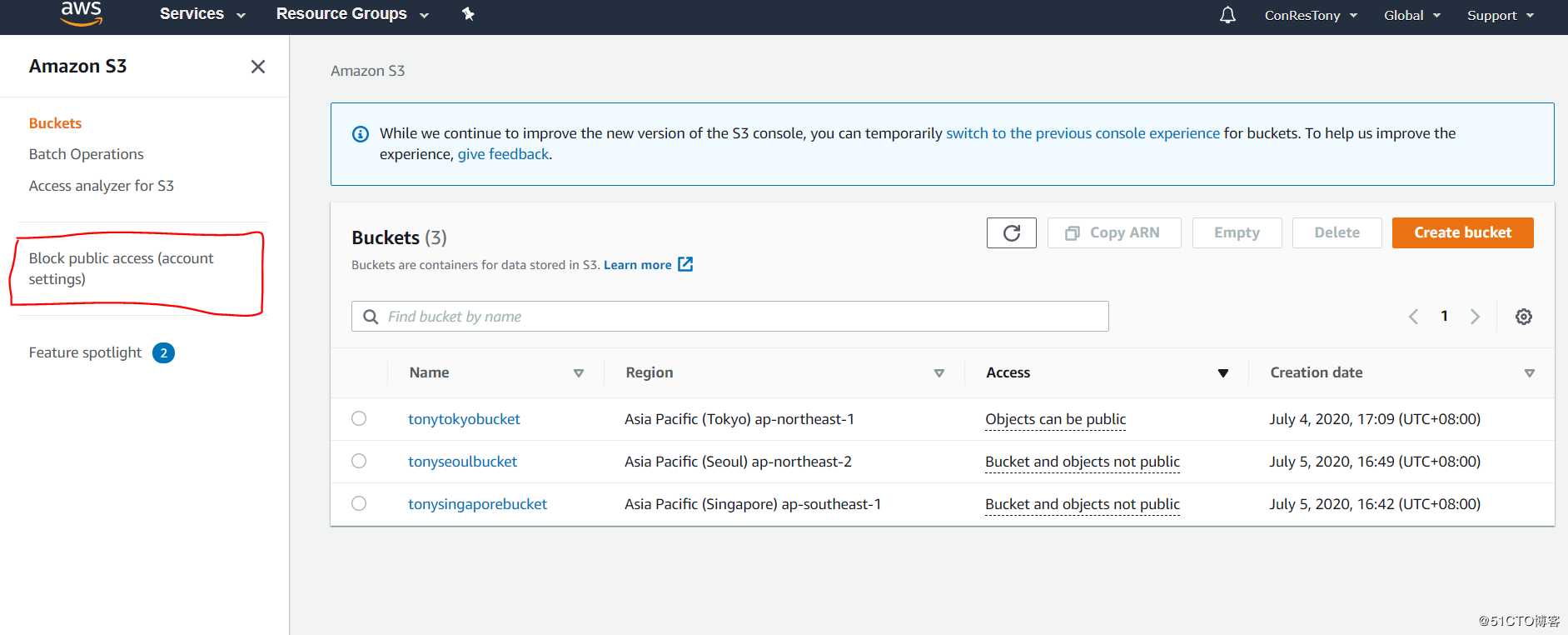
S3的版本控制
- 版本控制会创建多个不同的文件版本,并给一个版本ID;
- 删除被版本控制控制的文件并不会删掉文件,只会添加删除标记,需要显示版本显示;
- 积累的文件版本也是要收费的,所有版本容量的总和;
- 版本控制不能关闭只能暂停,暂停后在上传相同文件会覆盖ID为NULL的文件;
- 版本控制针对的是整个bucket,而不是单个文件
S3的cross-region replication
- cross-replication的前提条件是必须得开启versionning
- 删除文件,文件的某一个版本或者删除删除标记(Delete Marker)是不会被同步的(目标存储桶的对象是不会被删除的)
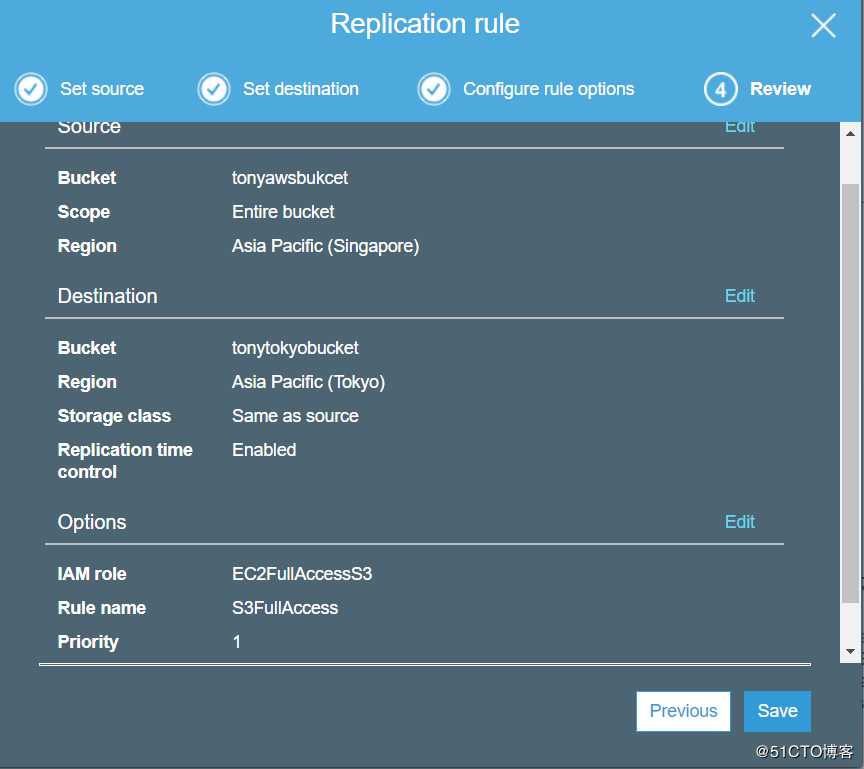
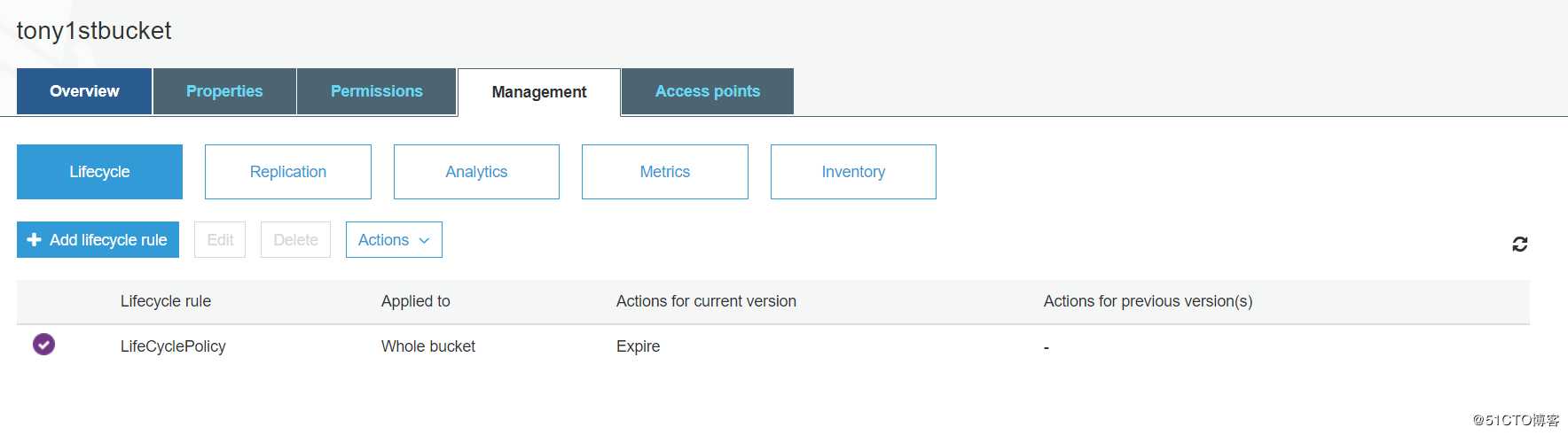
S3的lifecycle
这个功能是不需要开启versioning的,可以解释的地方并不多。主要就是为了成本考虑。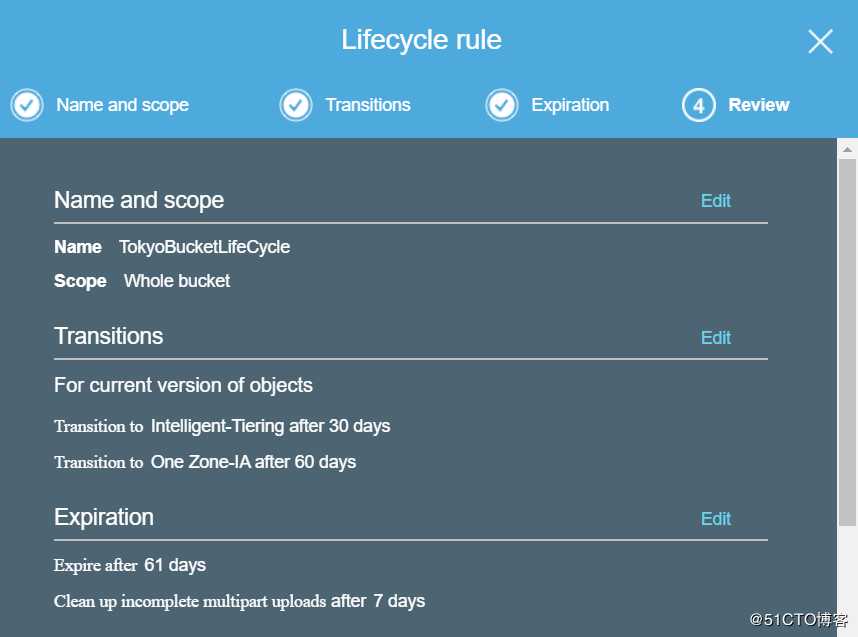
S3 Transfer Acceleration
用户可以通过使用AWS的CloudFront的Edge location来上传下载数据。简单的来讲,就是你和你要操作的S3的节点更近了,然后S3再通过自己内部的传输和各自的region 沟通。
整体而言,对香港这种网速很好的区域,这个功能似乎用处不大。。。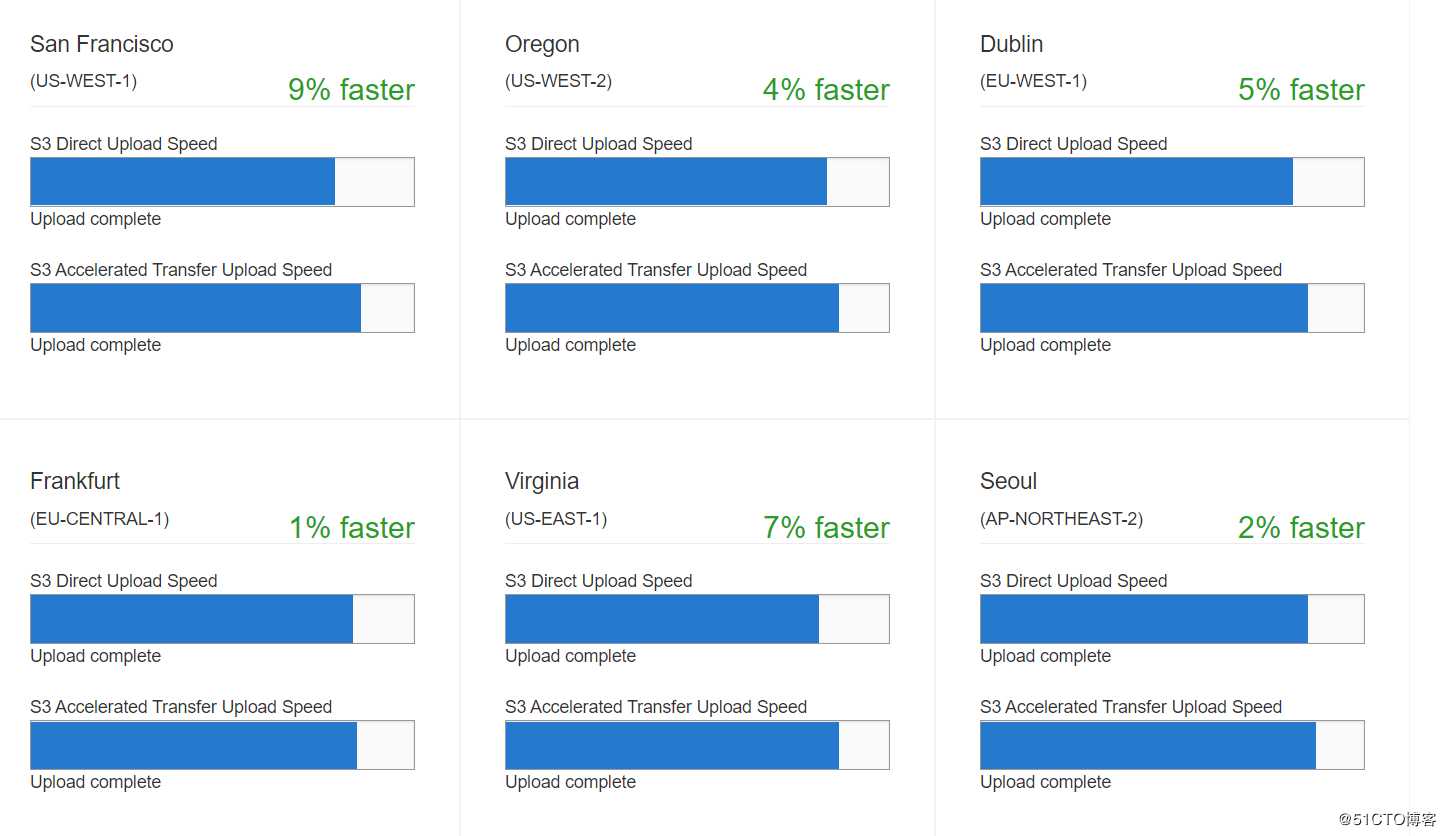
S3 static website hosting
简单的来讲,就是你把一个静态的html页面上传到你的bucket,然后static website hosting会生成一个网页链接,就可以访问了。暂时没想到这个玩意的use case。。。
注意下S3的object 链接和 website 链接两者的区别
https://tonytokyobucket.s3-ap-northeast-1.amazonaws.com/static+webhosting.html
http://tonytokyobucket.s3-website-ap-northeast-1.amazonaws.com/
Storage Gateway
这个功能简单的来讲就是讲现有的on-prem的数据迁移到云上的一个服务。推荐读一读FAQ的第一部分,一般问题:https://aws.amazon.com/cn/storagegateway/faqs/
三个驱动原因值得一记:
- 使用storage gateway 是为了让数据尽量平滑的迁移到云上
- 减少本地存储,少给EMC,Netapp付钱
- 降低数据与AWS服务的延时
需要注意的是,storage不仅可以在AWS的console上配置,也可以使用on-prem或者VM ESxi版本的。
Storage Gateway一共分为三种
File Gateway: 基于NFS,SMB的文件传输
Volume Gateway: 块存储,使用iSCSI。这种存储也分两种类型
a. stored volumes: 会将数据保存在本地,但是会异步的将数据备份到S3上去
b. cached volume: 数据保存到S3上,但是会将经常访问的数据放到缓存上。
Tape Gateway:没啥好说的,全部搬到Glacier上。
基于上面的描述,下面这个部署模型就清晰很多了。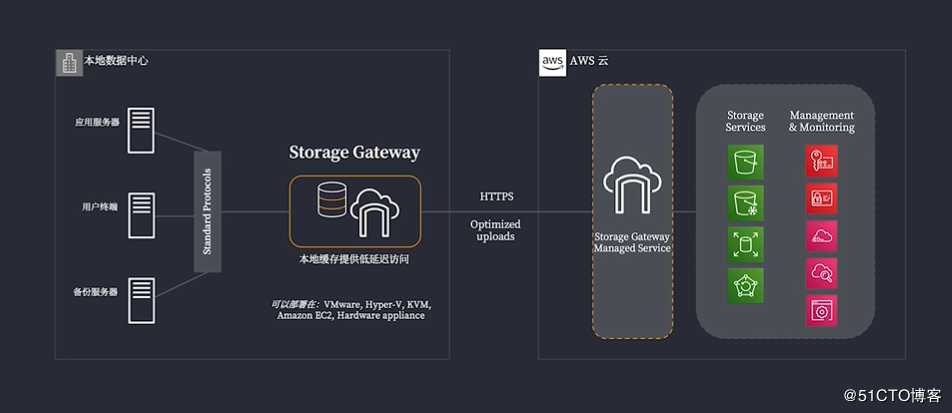
注意,需要部署两套storaged gateway,一套在客户的数据中心,另外一套就在AWS里面。
以上是关于AWS S3概念 + 操作的主要内容,如果未能解决你的问题,请参考以下文章
无法使用 github 操作部署 aws beanstalk,获得 s3 访问被拒绝错误
AWS BOTO3 S3 python - 调用 HeadObject 操作时发生错误(404):未找到
AWS CLI S3:使用终端在本地复制文件:致命错误:调用 HeadObject 操作时发生错误(404)
[Django][AWS S3] botocore.exceptions.clienterror 调用 PutObject 操作时发生错误(访问被拒绝)