scrapy基本知识
Posted kongrui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy基本知识相关的知识,希望对你有一定的参考价值。
1. Scrapy使用了Twisted异步网络库来处理网络通讯,整体架构:
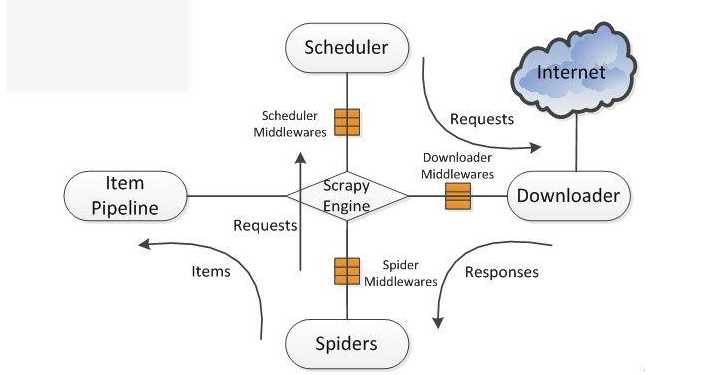
- Scrapy爬虫框架主要由5个部分组成,分别是:Scrapy Engine(Scrapy引擎),Scheduler(调度器),Downloader(下载器),Spiders(蜘蛛),Item Pipeline(项目管道)。爬取过程是Scrapy引擎发送请求,之后调度器把初始URL交给下载器,然后下载器向服务器发送服务请求,得到响应后将下载的网页内容交与蜘蛛来处理,尔后蜘蛛会对网页进行详细的解析。
- 蜘蛛分析的结果有两种:一种是得到新的URL,之后再次请求调度器,开始进行新一轮的爬取,不断的重复上述过程;另一种是得到所需的数据,之后会转交给项目管道继续处理。项目管道负责数据的清洗、验证、过滤、去重和存储等后期处理,最后由Pipeline输出到文件中,或者存入数据库等。
scrapy startproject XXX可以产生一个项目
以上是关于scrapy基本知识的主要内容,如果未能解决你的问题,请参考以下文章