Hadoop中单机模式和伪分布式的区别是啥
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop中单机模式和伪分布式的区别是啥相关的知识,希望对你有一定的参考价值。
单机(非分布式)模式这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统。
注意事项:运行bin/hadoopjarhadoop-0.16.0-examples.jarwordcounttest-intest-out时,务必注意第一个参数是jar,不是-jar,当你用-jar时,不会告诉你是参数错了,报告出来的错误信息是:Exceptioninthread"main"java.lang.NoClassDefFoundError:org/apache/hadoop/util/ProgramDriver,笔者当时以为是classpath的设置问题,浪费了不少时间。通过分析bin/hadoop脚本可知,-jar并不是bin/hadoop脚本定义的参数,此脚本会把-jar作为Java的参数,Java的-jar参数表示执行一个Jar文件(这个Jar文件必须是一个可执行的Jar,即在MANIFEST中定义了主类),此时外部定义的classpath是不起作用的,因而会抛出java.lang.NoClassDefFoundError异常。而jar是bin/hadoop脚本定义的参数,会调用Hadoop自己的一个工具类RunJar,这个工具类也能够执行一个Jar文件,并且外部定义的classpath有效。
伪分布式运行模式
这种模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点(NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode),请注意分布式运行中的这几个结点的区别:从分布式存储的角度来说,集群中的结点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份。从分布式应用的角度来说,集群中的结点由一个JobTracker和若干个TaskTracker组成,JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算。JobTracker和NameNode则无须在同一台机器上。追问

可以显示这几项的是不是就是伪分布式了?
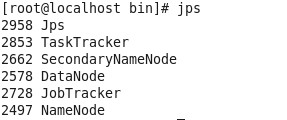
1、Hadoop是Apache开源组织的一个分布式计算框架,可以在大量廉价硬件设备组成的集群上运行应用程序,并未应用程序提供一组稳定可靠的接口,旨在构建一个具有高可靠性和良好扩展性的分布式系统。Hadoop的核心是HDFS(Hadoop Distributed File System),Mapreduce和Hbase,他们分别是Google云计算核心技术GFS,Mapreduce和Bigtable的开源实现。Hadoop集群有三种运行模式,分别为单机模式,伪分布式模式和完全分布式模式。hadoop完全分布式:3个及以上的实体机或者虚拟机组件的机群。hadoop伪分布式:一个节点。
2、单机模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统。默认情况下,Hadoop被配置成以非分布式模式运行的一个独立Java进程。hadoop完全分布式:3个及以上的实体机或者虚拟机组件的机群。通过分析bin/hadoop脚本可知,-jar并不是bin/hadoop脚本定义的参数,此脚本会把-jar作为Java的参数,Java的-jar参数表示执行一个Jar文件(这个Jar文件必须是一个可执行的Jar,即在MANIFEST中定义了主类),此时外部定义的classpath是不起作用的,因而会抛出java.lang.NoClassDefFoundError异常。而jar是bin/hadoop脚本定义的参数,会调用Hadoop自己的一个工具类RunJar,这个工具类也能够执行一个Jar文件,并且外部定义的classpath有效。
3、伪分布模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点(NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode),请注意分布式运行中的这几个结点的区别:从分布式存储的角度来说,集群中的结点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份。从分布式应用的角度来说,集群中的结点由一个JobTracker和若干个TaskTracker组成,JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算。JobTracker和NameNode则无须在同一台机器上。
参考技术B 简单的说,单机模式只是执行程序用的,没有分布式环境。伪分布式是在一台电脑里虚拟出n个节点,执行hadoop程序的时候就和多台电脑环境一样。
以上是关于Hadoop中单机模式和伪分布式的区别是啥的主要内容,如果未能解决你的问题,请参考以下文章