volitail关键字
Posted zpp1234
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了volitail关键字相关的知识,希望对你有一定的参考价值。
从硬件层面了解可见性的本质
一台计算机中最核心的组件是CPU、内存、以及I/O设备。 在整个计算机的发展历程中,除了CPU、内存以及I/O设 备不断迭代升级来提升计算机处理性能之外,还有一个非 常核心的矛盾点,就是这三者在处理速度的差异。CPU的 计算速度是非常快的,内存次之、最后是IO设备比如磁盘。 而在绝大部分的程序中,一定会存在内存访问,有些可能 还会存在I/O设备的访问 为了提升计算性能,CPU从单核升级到了多核甚至用到了 超线程技术最大化提高 CPU 的处理性能,但是仅仅提升 CPU性能还不够,如果后面两者的处理性能没有跟上,意 味着整体的计算效率取决于最慢的设备。为了平衡三者的速度差异,最大化的利用CPU提升性能,,最大化的利用CPU提升性能,从硬件、操作系 统、编译器等方面都做出了很多的优化
1. CPU增加了高速缓存
2. 操作系统增加了进程、线程。通过CPU的时间片切换最 大化的提升CPU的使用率
3. 编译器的指令优化,更合理的去利用好CPU的高速缓存 然后每一种优化,都会带来相应的问题,而这些问题也是 导致线程安全性问题的根源。为了了解前面提到的可见性 问题的本质,我们有必要去了解这些优化的过程
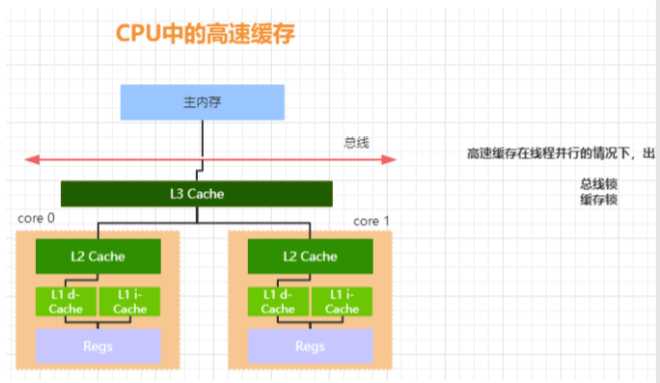
通过高速缓存的存储交互很好的解决了处理器与内存的速 度矛盾,但是也为计算机系统带来了更高的复杂度,因为 它引入了一个新的问题,缓存一致性。
什么叫缓存一致性呢?
首先,有了高速缓存的存在以后,每个CPU的处理过程是, 先将计算需要用到的数据缓存在CPU高速缓存中,在CPU 进行计算时,直接从高速缓存中读取数据并且在计算完成 之后写入到缓存中。在整个运算过程完成后,再把缓存中 的数据同步到主内存。 由于在多CPU种,每个线程可能会运行在不同的CPU内, 并且每个线程拥有自己的高速缓存。同一份数据可能会被 缓存到多个 CPU 中,如果在不同 CPU 中运行的不同线程
看到同一份内存的缓存值不一样就会存在缓存不一致的问 题 为了解决缓存不一致的问题,在 CPU 层面做了很多事情, 主要提供了两种解决办法
1. 总线锁 2. 缓存锁
总线锁和缓存锁
总线锁,简单来说就是,在多cpu下,当其中一个处理器 要对共享内存进行操作的时候,在总线上发出一个LOCK# 信号,这个信号使得其他处理器无法通过总线来访问到共 享内存中的数据,总线锁定把CPU和内存之间的通信锁住 了,这使得锁定期间,其他处理器不能操作其他内存地址 的数据,所以总线锁定的开销比较大,这种机制显然是不 合适的 ;
如何优化呢?最好的方法就是控制锁的保护粒度,我们只 需要保证对于被多个 CPU 缓存的同一份数据是一致的就 行。所以引入了缓存锁,它核心机制是基于缓存一致性协 议来实现的。
缓存一致性协议:即值的四个状态
为了达到数据访问的一致,需要各个处理器在访问缓存时遵循一些协议,在读写时根据协议来操作,常见的协议有 MSI,MESI,MOSI等。最常见的就是MESI协议。接下来 给大家简单讲解一下MESI(硬件方面的实现);
MESI表示缓存行的四种状态,分别是
1. M(Modify) 表示共享数据只缓存在当前 CPU 缓存中, 并且是被修改状态,也就是缓存的数据和主内存中的数 据不一致
2. E(Exclusive) 表示缓存的独占状态,数据只缓存在当前 CPU缓存中,并且没有被修改
3. S(Shared) 表示数据可能被多个CPU缓存,并且各个缓 存中的数据和主内存数据一致
4. I(Invalid) 表示缓存已经失效
在 MESI 协议中,每个缓存的缓存控制器不仅知道自己的 读写操作,而且也监听(snoop)其它Cache的读写操作,嗅探机制,即修改发送通知给其他cpu,让其他cpu缓存行修改为I,即失效状态
对于 MESI 协议,从 CPU 读写角度来说会遵循以下原则:
CPU读请求:缓存处于M、E、S状态都可以被读取,I状 态CPU只能从主存中读取数据 CPU写请求:缓存处于M、E状态才可以被写。
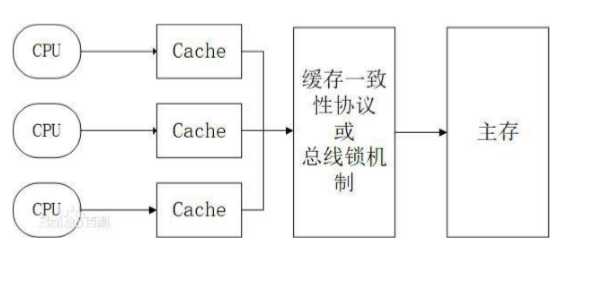
对于S状 态的写,需要将其他CPU中缓存行置为无效才可写 使用总线锁和缓存锁机制之后,CPU对于内存的操作大概 可以抽象成下面这样的结构。从而达到缓存一致性效果
MESI 优化带来的可见性问题
MESI协议虽然可以实现缓存的一致性,但是也会存在一些 问题。 就是各个CPU缓存行的状态是通过消息传递来进行的。如 果 CPU0 要对一个在缓存中共享的变量进行写入,首先需 要发送一个失效的消息给到其他缓存了该数据的CPU。并 且要等到他们的确认回执。CPU0 在这段时间内都会处于阻塞状态。为了避免阻塞带来的资源浪费。在cpu中引入 了Store Bufferes。(即CPU0只需要在写入共享数据时,直接把数据写入到store bufferes中,同时发送invalidate消息,然后继续去处理其他指令。 异步处理写数据和发送失效指令))
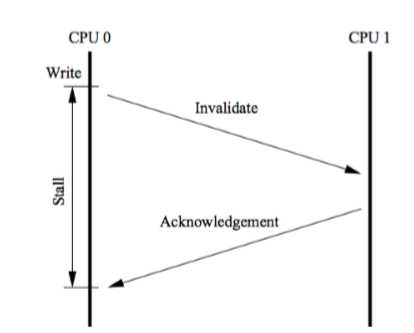
当收到其他所有CPU发送了invalidate acknowledge消息 时,再将 store bufferes 中的数据数据存储至 cache line 中。最后再从缓存行同步到主内存。
但是这种优化存在两个问题
1. 数据什么时候提交是不确定的,因为需要等待其他 cpu 给回复才会进行数据同步。这里其实是一个异步操作
2. 引入了storebufferes后,处理器会先尝试从storebuffer 中读取值,如果 storebuffer 中有数据,则直接从 storebuffer中读取,否则就再从缓存行中读取
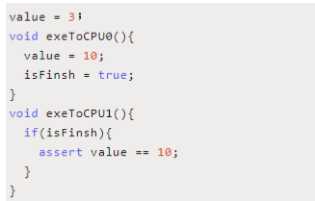
exeToCPU0和exeToCPU1分别在两个独立的CPU上执行。 假如 CPU0 的缓存行中缓存了 isFinish 这个共享变量,并 且状态为(E)、而Value可能是(S)状态。 那么这个时候,CPU0在执行的时候,会先把value=10的 指令写入到storebuffer中。并且通知给其他缓存了该value 变量的CPU。在等待其他CPU通知结果的时候,CPU0会 继续执行isFinish=true这个指令。 而因为当前CPU0缓存了isFinish并且是Exclusive状态,所
以可以直接修改 isFinish=true。这个时候 CPU1 发起 read 操作去读取isFinish的值可能为true,但是value的值不等 于10。 这种情况我们可以认为是CPU的乱序执行,也可以认为是 一种重排序,而这种重排序会带来可见性的问;
这下硬件工程师也抓狂了,我们也能理解,从硬件层面很 难去知道软件层面上的这种前后依赖关系,所以没有办法 通过某种手段自动去解决。 所以硬件工程师就说: 既然怎么优化都不符合你的要求, 要不你来写吧。 所以在 CPU 层面提供了 memory barrier(内存屏障)的指 令,从硬件层面来看这个 memroy barrier就是CPU flush store bufferes中的指令。软件层面可以决定在适当的地方 来插入内存屏障;
内存屏障解决可见性问题,即禁止指令重排序;
CPU 层面的内存屏障
什么是内存屏障?从前面的内容基本能有一个初步的猜想, 内存屏障就是将 store bufferes 中的指令写入到内存,从 而使得其他访问同一共享内存的线程的可见性。
以上是关于volitail关键字的主要内容,如果未能解决你的问题,请参考以下文章