crashcourse中机器学习中一些基础名词解释
Posted zy1120192493
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了crashcourse中机器学习中一些基础名词解释相关的知识,希望对你有一定的参考价值。
在机器学习中,我们通过一些已标记的数据(已知的数据,带有标签,确定了其种类和一些属性数值的数据记录)记录成图表等,比如在进行分类问题的训练过程中,
如果特性只有两个,那么可以列平面图表来表示对应的labeled data, 即类似
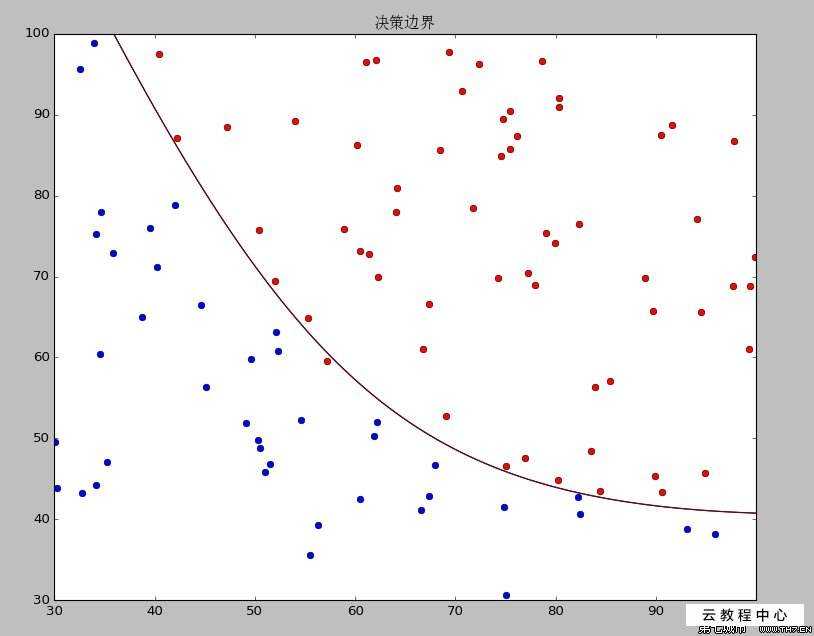
的图像(来自百度图片), 其中的曲线既是决策边界,如果我们用一个表格记录不同标签判断正确和判断错误的数值或者次数,那么表格就可以形成一个混淆矩阵(confusing matrix),如果属性数据不止3种,那么我们无法用直观上可以感受的二维或者三维图像来表示对应的标签数据,那么就需要用到高等代数中的对应知识,每一个属性的值对应了一个维度,每一个数据的不同属性则可以形成一个多维向量,在这种情况下进行分类的话,则是应当找到一个超平面(hyperplane)(即如果我们拿到的表示各种属性的向量是n维的,那么我们要找到n-1的仿射超平面作为决策边界,来对具有相关属性的数据进行预测和分类,仿射代数还没学,后续加上对应的理解)

决策树就是模仿判断未知数据对象并进行分类的一种推理过程和方式,方便进行代码实现,即我们找到了一些区分不同类别数据的判断条件,根据这些条件之间的逻辑关系用树的数据结构来表示该推测过程。
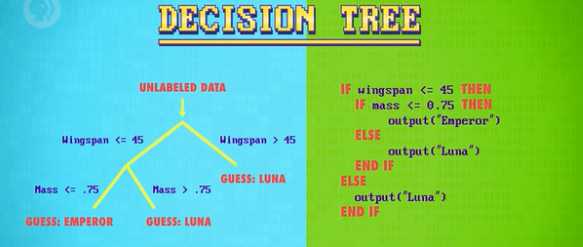
(图来自crashcourse)
支持向量机(support vector machine)也是用来找到决策边界的一种方式,可以是多项式或者数学函数等。
未完待续……
以上是关于crashcourse中机器学习中一些基础名词解释的主要内容,如果未能解决你的问题,请参考以下文章