数据库原理系列一:存储引擎(上)
Posted alpes
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库原理系列一:存储引擎(上)相关的知识,希望对你有一定的参考价值。
0:数据库架构 & 常见模块

Q1:为什么是disk-oriented架构?
- 磁盘很慢。那么问题来了,磁盘慢为啥还要用呢?
- 磁盘便宜。磁盘比内存那不是便宜了一点啊。
- 比内存大。数据往往很大,如果单纯的就用内存,那么多的数据存在哪。
- 永久存储。内存掉电数据就没了。
Q2:如果用了磁盘又会引入哪些问题?
- 数据交互。磁盘&内存存储的数据需要换入换出。
- 谁来换。DB or OS,各自的实现方式以及优缺点。
- 换哪些。LRU策略,内存刷入刷出的策略有哪些,各自的特点是啥?
- 什么时候换。刷脏页的条件,脏页线程轮询;buffer pool满了之类的。
- 怎么换。怎样能有效的提高读写,邻近页怎么处理,是否考虑顺序的读取、写入。
Q3:谁来change page?
- DB自身。同样的page交换,OS天然就自带这个功能mmap,为啥不用呢?
- 场景1:如果内存中没有空间了,new page怎样加进来?OS会care哪些是你经常用的page?不会,OS只会根据自己的策略去淘汰。DB失去了对数据的control。
- 场景2:并发读写page,并发读还好,如果是并发写呢?DB该如何来保证隔离级别&高并发的性能
Q4:要知道数据怎样在disk?mem之间切换,先看看数据在disk上是怎样存储的
- File → Page → Tuple
- File。mysql8.0大多是情况下就是一个表一个idb文件
- Page。可能包含tuples 元数据 索引 日志ect;有一个唯一id,查找用。
- 磁盘扇区 ~ 512字节,这个也是redo log写盘的最小单位,保证原子性
- OS ~ 4K
- Mysql Page ~ 16K;因为和OS的4K不对等,为了保证原子,引入Double Write
- Tuple。
Q5:File存储
怎样存储page,文件中的page
- linked list ?
- page dirctory ?
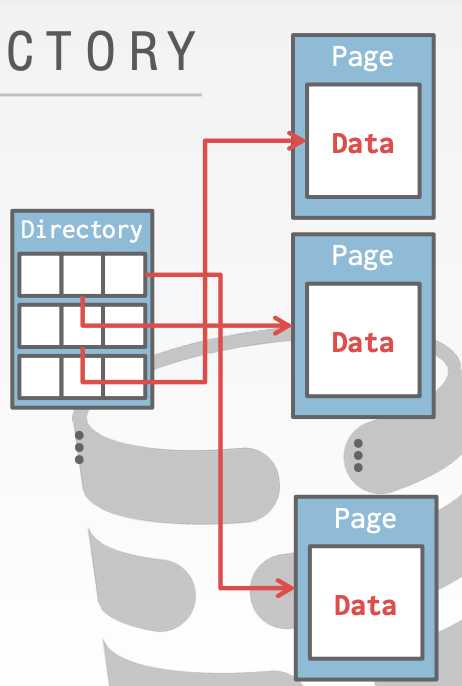
Q6:Page存储
- 存tuple(MySQL)
- 存log(leveldb,rocksDB ) 分层→ 压缩问题
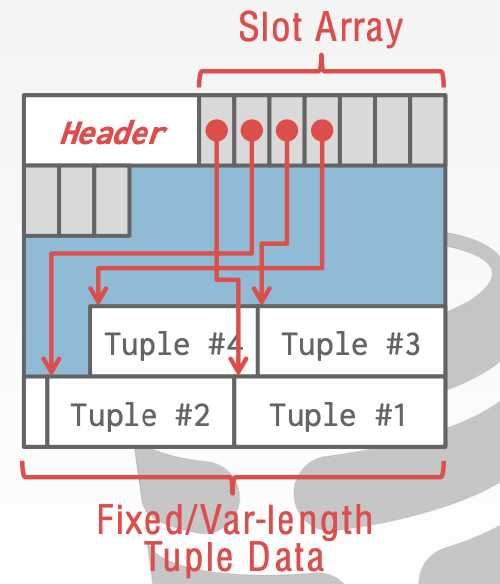
Q7:Tuple存储
- header。lsn信息[并发控制的],bitmap[NULL值信息]
- data。字段值
Q8:PG怎样找到对应的record
- page_id+offset
# 通过citydi找到page_id + offset
postgres=# select ctid,* from r;
ctid | id | val
-------+-----+-----
(0,1) | 101 | aaa ~~ page为0的第一个记录
(0,2) | 102 | bbb
(0,3) | 103 | ccc
# 删除是不会直接回收的
postgres=# delete from r where id=102;
DELETE 1
postgres=# select ctid,* from r;
ctid | id | val
-------+-----+-----
(0,1) | 101 | aaa
(0,3) | 103 | ccc
# 插入新的数据会顺延
postgres=# insert into r values(104,‘ddd‘);
INSERT 0 1
postgres=# select ctid,* from r;
ctid | id | val
-------+-----+-----
(0,1) | 101 | aaa
(0,3) | 103 | ccc
(0,4) | 104 | ddd
(3 rows)
# 重整后数据会挪动
postgres=# vacuum full;
VACUUM
postgres=# select ctid,* from r;
ctid | id | val
-------+-----+-----
(0,1) | 101 | aaa
(0,2) | 103 | ccc
(0,3) | 104 | ddd
Q9:MySQL怎样找到对应的record
# 8.0.20
# 根据表明找到TABLE_ID
mysql> select TABLE_ID,NAME from INNODB_TABLES where NAME=‘sbtest/sbtest1‘;
+----------+----------------+
| TABLE_ID | NAME |
+----------+----------------+
| 1065 | sbtest/sbtest1 |
+----------+----------------+
# 根据主键找到root page
mysql> select INDEX_ID,NAME,TYPE,PAGE_NO,SPACE from INNODB_INDEXES where TABLE_ID=1065 and NAME=‘PRIMARY‘;
+----------+---------+------+---------+-------+
| INDEX_ID | NAME | TYPE | PAGE_NO | SPACE |
+----------+---------+------+---------+-------+
| 151 | PRIMARY | 3 | 4 | 4 |
+----------+---------+------+---------+-------+
# 根据SPACE找到物理文件
mysql> select * from INNODB_DATAFILES where SPACE=4;
+--------------+----------------------+
| SPACE | PATH |
+--------------+----------------------+
| 0x34 | ./sbtest/sbtest1.ibd |
+--------------+----------------------+
# 二叉树的根节点在 ./sbtest/sbtest1.ibd文件 + PAGE_NO[4]的位置
# 根据二叉树找到对应的数据的page_id
# 然后在page中找满足条件的slot
# 不同于pg,MySQL表中并没有直接记录record对应的pageid + offset信息
https://dev.mysql.com/doc/internals/en/innodb-page-directory.html
https://dev.mysql.com/doc/refman/8.0/en/innodb-information-schema-system-tables.html
以上是关于数据库原理系列一:存储引擎(上)的主要内容,如果未能解决你的问题,请参考以下文章