dropout原理学习
Posted bluebluesea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了dropout原理学习相关的知识,希望对你有一定的参考价值。
1.百面机器学习中的讲解
Dropout是指在深度网络的训练中, 以一定的概率随机地 “临时丢弃”一部分神经元节点。
- 相当于每次迭代都在训练不同结构的神经网络。
- 类比于Bagging方法, Dropout可被认为是一种实用的大规模深度神经网络的模型集成算法。
- 因此, 对于包含N个神经元节点的网络, 在Dropout的作用下可看作为2N个模型的集成。
- 这2N个模型可认为是原始网络的子网络, 它们共享部分权值, 并且具有相同的网络层数, 而模型整体的参数数目不变,
- 大大简化了运算
训练阶段:
应用dropout之后前向传播过程变为:
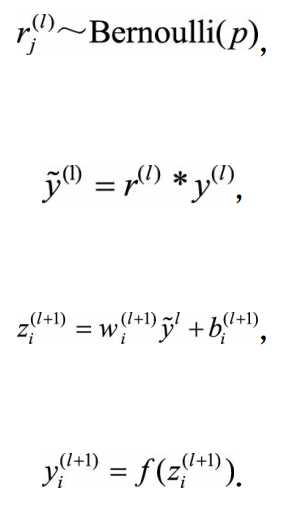
经过一个p值的伯努利分布,乘以上一层的输出,之后前向传播,值为0的BP时不计算梯度。
测试阶段:
dropout是带有随机性的,如果测试也做的话,网络的输出就不稳定了。所以测试阶段是没有dropout的。
测试阶段是前向传播的过程。 在前向传播的计算时, 每个神经元的参数要预先乘以概率系数p, 以恢复在训练中该神经元只有p的概率被用于整个神经网络的前向传播计算。
2.dropout为什么可以解决过拟合?
https://zhuanlan.zhihu.com/p/38200980
- 取平均的作用:整个dropout过程就相当于对很多个不同的神经网络取平均。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。
- 减少神经元之间复杂的共适应关系:因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
3.Keras中的实现
https://zhuanlan.zhihu.com/p/38200980
# coding:utf-8 import numpy as np # dropout函数的实现 def dropout(x, level): if level < 0. or level >= 1: #level是概率值,必须在0~1之间 raise ValueError(‘Dropout level must be in interval [0, 1[.‘) retain_prob = 1. - level # 我们通过binomial函数,生成与x一样的维数向量。binomial函数就像抛硬币一样,我们可以把每个神经元当做抛硬币一样 # 硬币 正面的概率为p,n表示每个神经元试验的次数 # 因为我们每个神经元只需要抛一次就可以了所以n=1,size参数是我们有多少个硬币。 random_tensor = np.random.binomial(n=1, p=retain_prob, size=x.shape) #即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了 print(random_tensor) x *= random_tensor print(x) x /= retain_prob return x #对dropout的测试,大家可以跑一下上面的函数,了解一个输入x向量,经过dropout的结果 x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32) dropout(x,0.4) # [0 1 1 0 1 1 1 1 1 0] [0. 2. 3. 0. 5. 6. 7. 8. 9. 0.]
[ 1.6666666 0. 0. 0. 8.333333 10.
11.666666 13.333333 0. 0. ]#放大后
但是我们可以看到有一句这么的操作: x /= retain_prob,对失活后又进行了scale,*了1/(1-p),其中这里的p表示的是失活率。
https://www.zhihu.com/question/61751133,进行了解释。

这里的p指的是1-失活率。因为训练的时候经过了*p的操作,而如果测试的时候不做改变,那么测试的输出就是训练时候的1/p倍,那么如果在训练的时候在dropout之后,就*1/p之后,预测的时候就不必做操作了。总的来说是为了保持输出期望不变,输出就会比较稳定。这就是Inverted Dropout。
朴素vanilla 版本:训练时候因为随机扔掉了一些节点,总期望变小,那么预测时候就全体缩小一点来保持一致。存在的问题:预测过程需要跟着 dropout 策略做调整,哪些层取消了、加重了或者减轻了,都需要改。一不小心就会出错。

以上是关于dropout原理学习的主要内容,如果未能解决你的问题,请参考以下文章
深度学习基础系列| Dropout VS Batch Normalization? 是时候放弃Dropout了
深度学习原理与框架-递归神经网络-RNN网络基本框架(代码?) 1.rnn.LSTMCell(生成单层LSTM) 2.rnn.DropoutWrapper(对rnn进行dropout操作) 3.tf.