Selenium 根据元素的ID属性选择元素
Posted sunzzc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Selenium 根据元素的ID属性选择元素相关的知识,希望对你有一定的参考价值。
每个标签都有不同的属性,其中有一个属性为id
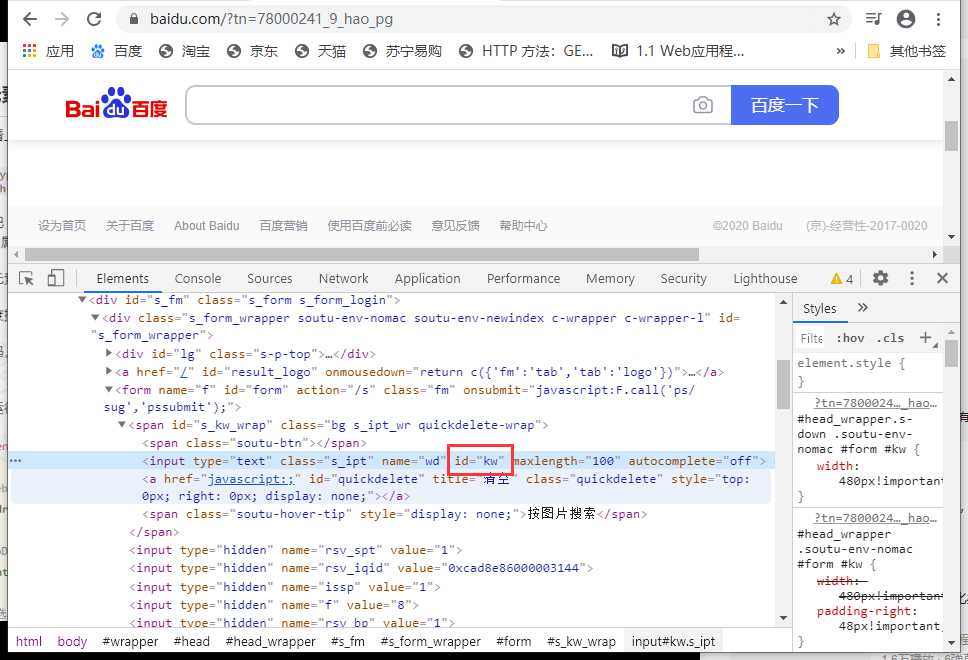
标签中的ID就相当于元素的编号,是用来标记该元素的,根据规范,如果元素有
ID属性,这个ID必须是当前html中唯一的。
所以个人元素有ID,根据ID选择元素是最简单高效的方式。
这里,百度搜索框元素的ID值为 kw
可以用代码 实现自动化在浏览器中访问百度,并且输入框中搜索内容
from selenium import webdriver # 导包
# 实例化浏览器 如果为空就是是用的项目根目录的Chrome驱动
borwser = webdriver.Chrome()
# 请求网址
borwser.get(‘http://www.baidu.com‘)
# print(borwser.page_source) # 获取网页源码
# 根据ID定位并 返回是该元素webelement对象
ele = borwser.find_element_by_id(‘kw‘)
# 可以通过webelement对象 就要对元素操作了 例如输入字符串
ele.send_keys(‘老祝头‘)
borwser.find_element_by_id(‘su‘).click() # 点击搜索
根据class属性,tag名 选择元素
web自动化的重点之一,就是如何选择我们想要操作的web页面元素。
除了根据元素id,我们还可以根据元素的class属性选择元素
实例网址:http://f.python3.vip/webauto/sample1.html
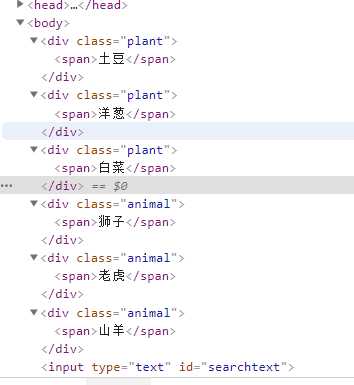
所有植物元素都有class属性 值为 plant 代表类别
所有植物元素都有class属性 值为 plant 代表类别
如果要选择所有动物或植物 就可以使用 find_elements_by_class_name()
因为 定位class_name 一般为多个 所以element 是复数形式 加 s
注意:
find_elements_by_class_name() 方法返回的是找到符合条件的所有元素,放在一个列表中返回。
如果使用 find_element_by_class_name() 不加s方法,就只会返回第一个元素
实例代码:
from selenium import webdriver # 导包
# 实例化浏览器 如果为空就是是用的项目根目录的Chrome驱动
borwser = webdriver.Chrome()
# 请求网址
borwser.get(‘http://f.python3.vip/webauto/sample1.html‘)
# 根据class name 选择元素 返回的是列表
ele = borwser.find_elements_by_class_name(‘plant‘)
# 取出列表中每个 webelement对象中的文本内容
for i in ele:
print(i.text)
element 和elements的区别
使用find_elements选择的是符合条件的所有元素,如果没有符合条件的元素返回的是空列表
使用find_element选择的是符合条件的第一个元素,如果没有符合条件的元素,抛出异常
以上是关于Selenium 根据元素的ID属性选择元素的主要内容,如果未能解决你的问题,请参考以下文章