ZooKeeper原理详解及常用操作
Posted tudachui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZooKeeper原理详解及常用操作相关的知识,希望对你有一定的参考价值。
ZooKeeper是什么?
ZooKeeper是一个开源的分布式应用程序协调系统。简称ZK,ZK是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于它实现数据的发布/订阅、负载均衡、名称服务、分布式协调/通知、集群管理、Master选举、分布式锁盒分布式队列等等功能。它运行在JAVA环境之中,并具有JAVA和C的绑定。
ZooKeeper的设计目标
ZooKeeper允许分布式进程通过共享的分层命名空间相互协调,该命名空间的组织方式与标准文件系统类似。名称空间由数据寄存器(在ZooKeeper中,被称为Znodes)组成,这些寄存器类似于文件和目录,与设计用于存储的典型文件系统不同,ZooKeeper数据保存在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟数。ZooKeeper实现非常重视高性能、高可用性、严格有序的访问,ZooKeeper的性能方面意味着它可以在大型分布式系统中使用,可靠性方面使其不会称为单点故障,严格的排序意味着可以在客户端实现复杂的同步原语。
ZooKeeper集群概念
集群角色
•Leader:领导者,通过集群选举产生的主节点,负责集群的读与写工作•Follower:追随者,有资格参与集群选举,但未能被成功选举为Leader的备用选举节点,负责集群的读服务•Observer:观察者,没有资格参与集群选举,负责集群的读服务,同步Leader状态
注意:当Leader故障之后ZooKeeper集群会通过Follower选举新的Leader,如果老的Leader故障修复之后,会再次接管集群中的Leader脚本,新的Leader则退回Follower角色。一般集群当中无需设置Observer节点,Follower节点即可。
图解集群

集群角色工作原理介绍:
上图中有5个ZooKeeper节点,其中一个节点为Leader,除leader节点外,其它都是追随者Follower,Client与ZK集群建立TCP长连接,只有追随者Follower节点来与Client建立连接(我们的Client与Follower建立的连接会始终存在,只有Client不再参与集群或者客户端出现故障之后才会断开连接,是一个持久会话,通过此会话,Client会不短向自己所连接的Follower更新自己的状态信息),并处理Client的请求,如果Client为读请求,则会转发到Follower或者本机进行处理,如果为写请求则转发给Leader处理。如果Client与连接的一台ZK集群中的服务器发生数据变更,则ZK集群中的这台服务器会把变更内容同步到ZK集群中的所有ZK服务器。
假如上图中的Client为Kafka,一共有8台Kafka,Kafka的集群配置信息全部是由ZooKeeper来维护,如果没有ZooKeeper,Kafka的单节点就不知道它们是个集群或者集群中共有那些节点,有了ZooKeeper之后,Kakfa节点会向ZK集群发出请求来询问他们的Kafka一共有几个集群节点,哪个节点还在工作,哪个节点为故障节点等等的集群信息全部都是由ZooKeeper来维护,如果想知道这些信息,Kafka就会去ZK集群节点中去请求一个数据分支,所有有了前面我们介绍ZooKeeper是的一个开源的分布式应用程序协调系统。通过ZooKeeper提供的服务来与Kafka集群的其它节点互知。
数据模型
上面讲到Kafka会去ZK集群中请求一个数据分支,ZooKeeper的数据分支一个倒置树状的分支结构,可以说这个数据是放在ZooKeeper内存中的一个树状的文件系统来保存Kafka集群的数据,ZooKeeper提供的这个存储系统非常类似于标准的文件目录,名称是有斜杠"/"来分割的。Kafka集群的每个节点信息都是存放在内存中的该存储系统中,各节点信息由路径标示,例如下图中的/app1,就是我们的Kafka中的一个节点(此节点在ZooKeeper中被官方称为ZNode,即ZooKeeper数据模型中的数据单元,数据模型因为为树状所以被称为Znode Tree,),/app1下的/p_1-3就是存储的这个Kafka节点的状态信息,例如该节点变更了哪些操作,存活状态等等。
ZNode维护一个stat结构,就是节点下面的/app1/p_1-3,维护该内容的数据数据更改,ACL更改盒时间戳的版本号,以允许缓存验证和协调更新。每次znode的数据更改时,版本号都会增加。例如,每当客户端检索数据时,它也接收数据的版本。

存储在每个ZNode的数据都是以原子方式读取和写入,读取获取与ZNode关联的所有数据字节,写入替换所有数据。每个节点都有一个访问控制列表(ACL),限制谁可以做什么。ZooKeeper也有短暂节点的概念。只要创建znode的会话处于活动状态,就会存在这些znode。会话结束时,znode将被删除。当您想要实现[tbd]时,短暂节点很有用。ZNode的数据节点分为两类
持久节点:一直存在,如果想要消失,仅显示删除才消失临时节点:会话终止即自动消失
上面我们讲到ZNode维护一个stat结构,维护该内容的数据数据更改,ACL更改盒时间戳的版本号,下面我们就讲下ACL和版本号 版本(version):ZK会为每个ZNode维护一个称之为stat的数据结构,记录当前数据结构的三个数据版本
version:当前版本cversion:当前的znode子节点版本aversion:当前的znode的ACL版本
ACL:因为可能会有多个分布式系统使用一个ZooKeeper集群来维护集群的协调服务,那么不同分布式集群信息不能被其它机器所访问,就出现了ZooKeeper使用ACL机制进行权限控制。
CREATE:创建READ:读WRITE:写DELETE:删ADMIN:管理
ZAB协议
ZooKeeper(ZooKeeper Atomic Broadcast,ZooKeeper原子广播协议)是通过ZAB协议来完成了Client各个节点选举的信息,ZAB协议是整个ZooKeeper的核心,支持崩溃保护机制,用于在Leader崩溃时重新选举出新的Leader,而且还要确保数据的完整性和一至性,此协议不仅能够保证ZooKeeper集群本身的选举,还能管理使用ZooKeeper协调服务的分布式程序的选举工作。
ZAB协议中存在的三种状态:
(1)Looking:集群刚启动,开始选举Leader,或者Leader崩溃之后再次选举新的Leader时,正在选举,被称为Looking状态。
(2)Following:Following就是Follower状态,这个时候集群中已经存在Leader,这些机器属于Follover节点称之为Following状态。
(3)Leading:Leader就被称为Leading状态。
ZAB协议中的存在的四个阶段:
•选举:election•发现:discovery•同步:sync•广播:Broadcast
部署ZooKeeper
ZooKeeper下载:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz解压并安装
tar xf zookeeper-3.4.14.tar.gz -C /application/cp /application/zookeeper-3.4.14/conf/zoo_sample.cfg /application/zookeeper-3.4.14/conf/zoo.cfg
添加环境变量
cat << EOF >> /etc/profileexport ZOOKEEPER_HOME=/application/zookeeper-3.4.14export PATH=$PATH:$ZOOKEEPER_HOME/binEOFsource /etc/profile
修改ZooKeeper配置
cat /application/zookeeper-3.4.14/conf/zoo.cfgtickTime=2000initLimit=10syncLimit=5dataDir=/application/zookeeper-3.4.14/datadataLogDir=/application/zookeeper-3.4.14/logsclientPort=2181maxClientCnxns=60autopurge.snapRetainCount=3autopurge.purgeInterval=1server.1=localhost:2888:3888
创建数据存储目录及日志目录
mkdir /application/zookeeper-3.4.14/{data,logs}ZooKeeper配置详解
tickTime=2000#ZooKeeper服务器之间或客户单与服务器之间维持心跳的时间间隔,单位是毫秒,默认为2000。initLimit=10#zookeeper接受客户端(这里所说的客户端不是用户连接zookeeper服务器的客户端,而是zookeeper服务器集群中连接到leader的follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。#当已经超过10个心跳的时间(也就是tickTime)长度后 zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20秒。syncLimit=5#标识ZooKeeper的leader和follower之间同步消息,请求和应答时间长度,最长不超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。dataDir=/application/zookeeper-3.4.14/data#存储内存数据库快照的位置;ZooKeeper保存Client的数据都是在内存中的,如果ZooKeeper节点故障或者服务停止,那么ZooKeeper就会将数据快照到该目录当中。clientPort=2181#ZooKeeper客户端连接ZooKeeper服务器的端口,监听端口maxClientCnxns=60#ZooKeeper可接受客户端连接的最大数量,默认为60dataLogDir=/application/zookeeper-3.4.14/logs#如果没提供的话使用的则是dataDir。zookeeper的持久化都存储在这两个目录里。dataLogDir里是放到的顺序日志(WAL)。而dataDir里放的是内存数据结构的snapshot,便于快速恢复。
为了达到性能最大化,一般建议把dataDir和dataLogDir分到不同的磁盘上,这样就可以充分利用磁盘顺序写的特性autopurge.snapRetainCount=3#ZooKeeper要保留dataDir中快照的数量autopurge.purgeInterval=1#ZooKeeper清楚任务间隔(以小时为单位),设置为0表示禁用自动清除功能server.1=localhost:2888:3888#指定ZooKeeper集群主机地址及通信端口#1 为集群主机的数字标识,一般从1开始,三台ZooKeeper集群一般都为123#localhost 为集群主机的IP地址或者可解析主机名#2888 端口用来集群成员的信息交换端口,用于ZooKeeper集群节点与leader进行信息同步#3888 端口是在leader挂掉时或者刚启动ZK集群时专门用来进行选举leader所用的端口
启动ZooKeeper
/application/zookeeper-3.4.14/bin/zkServer.sh startZooKeeper JMX enabled by defaultUsing
config: /application/zookeeper-3.4.14/bin/../conf/zoo.cfgStarting zookeeper ... STARTED查看ZK状态/application/zookeeper-3.4.14/bin/zkServer.sh statusZooKeeper JMX enabled by defaultUsing
config: /application/zookeeper-3.4.14/bin/../conf/zoo.cfgMode: standaloness -anplt | grep 2181LISTEN 0 50 :::2181 :::* users:(("java",pid=17168,fd=27))
ZooKeeper执行程序简介
ls /application/zookeeper-3.4.14/bin/ -ltotal 44-rwxr-xr-x 1 2002 2002 232 Mar 7 00:50 README.txt-rwxr-xr-x 1 2002 2002 1937 Mar 7 00:50 zkCleanup.sh-rwxr-xr-x 1 2002 2002 1056 Mar 7 00:50 zkCli.cmd-rwxr-xr-x 1 2002 2002 1534 Mar 7 00:50 zkCli.sh #ZK客户端连接ZK的脚本程序-rwxr-xr-x 1 2002 2002 1759 Mar 7 00:50 zkEnv.cmd-rwxr-xr-x 1 2002 2002 2919 Mar 7 00:50 zkEnv.sh #ZK变量脚本程序-rwxr-xr-x 1 2002 2002 1089 Mar 7 00:50 zkServer.cmd-rwxr-xr-x 1 2002 2002 6773 Mar 7 00:50 zkServer.sh #ZK启动脚本程序-rwxr-xr-x 1 2002 2002 996 Mar 7 00:50 zkTxnLogToolkit.cmd-rwxr-xr-x 1 2002 2002 1385 Mar 7 00:50 zkTxnLogToolkit.sh
zkServer.sh启动文件
zkServer.sh通常用来启动、终止、重启ZK服务器,用法如下:
/application/zookeeper-3.4.14/bin/zkServer.shZooKeeper JMX enabled by defaultUsing config: /application/zookeeper-3.4.14/bin/../conf/zoo.cfgUsage: /application/zookeeper-3.4.14/bin/zkServer.sh {start|start-foreground|stop|restart|status|upgrade|print-cmd}#关闭ZK服务/application/zookeeper-3.4.14/bin/zkServer.sh stop#启动ZK服务/application/zookeeper-3.4.14/bin/zkServer.sh start#启动ZK服务并打印启动信息到标准输出,方便于排错/application/zookeeper-3.4.14/bin/zkServer.sh start-foreground#重启ZK服务/application/zookeeper-3.4.14/bin/zkServer.sh restart#查看ZK服务状态/application/zookeeper-3.4.14/bin/zkServer.sh status
zkCli.sh客户端连接
zkCli.sh是用来连接zk服务的脚本程序文件,使用该脚本程序连接到ZK后,可管理ZK服务,用法如下:

create [-s] [-e] path data acl 选项介绍: -s用来指定节点特性为顺序节点;顺序节点:是创建时唯一且被独占的递增性整数作为其节点号码,此号码会被叠加在路径之后。 -e用来指定特性节点为临时节点,临时节点不允许有子目录;关于持久节点和临时节点请看上篇文章 若不指定,则表示持久节点 acl用来做权限控制
创建ZooKeeper持久节点
#创建持久节点permanent,关联字符串permanent[zk: localhost:2181(CONNECTED) 0]
create /permanent "permanent"Created /permanent#在持久节点permanent下创建子目录zk-node1和zk-nod2[zk: localhost:2181(CONNECTED) 1]create /permanent/zk_node1
"zk_node1"Created /permanent/zk_node1[zk: localhost:2181(CONNECTED) 2]create /permanent/zk_node2
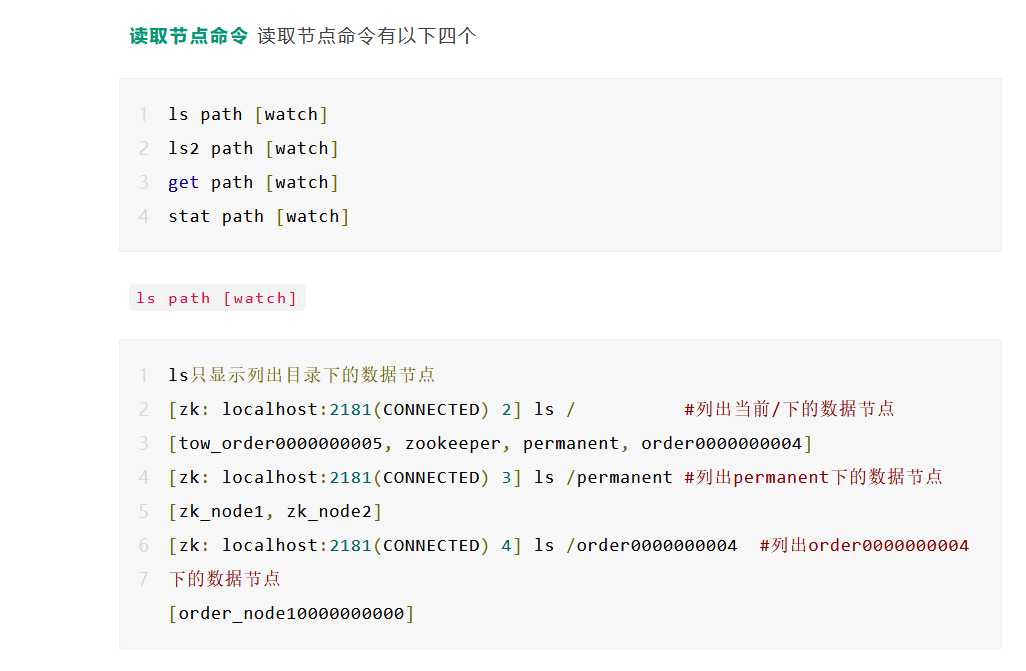
"zk_node2"Created /permanent/zk_node2#查看创建的zk数据文件[zk: localhost:2181(CONNECTED) 3] ls /[zookeeper, permanent][zk: localhost:2181(CONNECTED) 4] ls /permanent[zk_node1, zk_node2]
创建ZooKeeper顺序节点
#创建顺序节点order,关联字符串order,创建好之后并不会以我们创建的order命名,zk会自动在后面加上一排递增数字来显示此文件夹,递增数据不会从重复[zk: localhost:2181(CONNECTED) 5] create -s /order "order"Created /order0000000004[zk: localhost:2181(CONNECTED) 6] ls /[zookeeper, permanent, order0000000004]#我们再次创建一个顺序节点,会发现后面的增至数字默认加1,并没有重复[zk: localhost:2181(CONNECTED) 8] create -s /tow_order "two_order"Created /tow_order0000000005[zk: localhost:2181(CONNECTED) 9] ls /[tow_order0000000005, zookeeper, permanent, order0000000004]#创建顺序节点order的子节点[zk: localhost:2181(CONNECTED) 10] create -s /order0000000004/order_node1
"order_node1"Created /order0000000004/order_node10000000000
创建ZooKeeper临时节点
#创建临时节点temp[zk: localhost:2181(CONNECTED) 15] create -e /temp
"temp"Created /temp[zk: localhost:2181(CONNECTED) 16] ls /
#查看已经创建完成的临时节点
temp[tow_order0000000005, temp, zookeeper, permanent, order0000000004]#在临时节点temp中创建子目录,[zk: localhost:2181(CONNECTED) 17] create -e /temp/two_temp
"tow_temp"Ephemerals cannot have children: /temp/two_temp
#你会发现创建子目录,ZK给你报错误说”临时节点不允许子目录存在。我们上面也说过了,临时节点不允许存在子目录[zk: localhost:2181(CONNECTED) 18] ls /temp
#查看临时节点/temp下,并没有我们所创建的two_temp子目录[]#测试临时节点#创建的临时节点如果当前客户端断开了连接后临时节点会自动消失,而持久节点和顺序节点则需要使用删除命令来消失#退出当前ZK连接,再次连接到ZK[zk: localhost:2181(CONNECTED) 19] quit
#退出当前ZK连接/application/zookeeper-3.4.14/bin/zkCli.sh -server localhost:2181
#再次连接到ZK#查看临时目录是否存在[zk: localhost:2181(CONNECTED) 0] ls /[tow_order0000000005, zookeeper, permanent, order0000000004]
#当我们结束当前客户端连接后,ZK的临时节点temp也会随之消失

以上是关于ZooKeeper原理详解及常用操作的主要内容,如果未能解决你的问题,请参考以下文章