蚂蚁金服在 Service Mesh 监控落地经验总结
Posted java-xiatian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了蚂蚁金服在 Service Mesh 监控落地经验总结相关的知识,希望对你有一定的参考价值。
引言
Service Mesh 是目前社区最为炙手可热的技术方向,去年双11在蚂蚁金服得到全面的应用,并平稳顺滑的支撑了大促服务。作为目前规模最大的 Service Mesh 集群,本文从监控的领域对 Service Mesh 落地进行经验总结,主要从以下几方面进行介绍:
- 云原生监控,介绍蚂蚁金服 Metrics 监控的落地;
- 用户视角分析,介绍从应用 owner 的角度对这一基础服务设施的体验以及 SRE 从全站服务的稳定性对监控提出的要求;
- 未来的思考,介绍后续发展方向;
云原生监控
云原生应用的设计理念已经被越来越多的开发者接受与认可,今年蚂蚁金服应用服务全面云原生化,对我们监控服务提出更高的要求。目前 Metrics 指标监控服务也逐渐形成体系,如下图所示基于社区原生 Prometheus 采集方案在蚂蚁金服监控场景下落地。
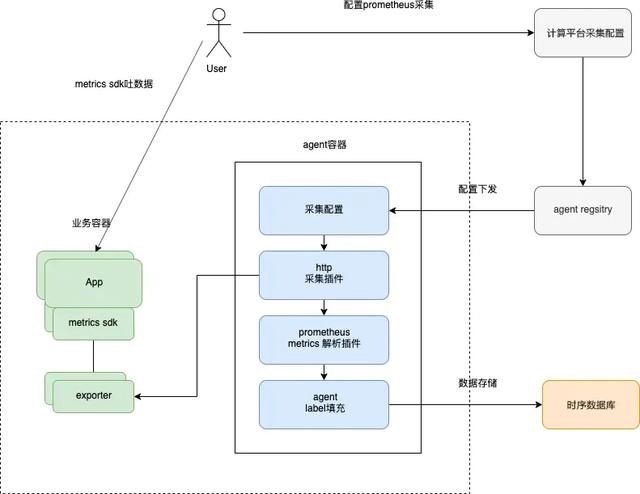
怎么采集
蚂蚁金服监控采集 AGENT 是部署在物理机上,支持多个采集插件,如下图,包括执行命令、日志、HTTP 请求、动态 SQL 采集、系统指标采集、JVM 采集以及进程监控等,同时支持多个解析插件自定义解析、单行文本解析、Lua 脚本解析、JSON 解析以及 Prometheus 解析等。
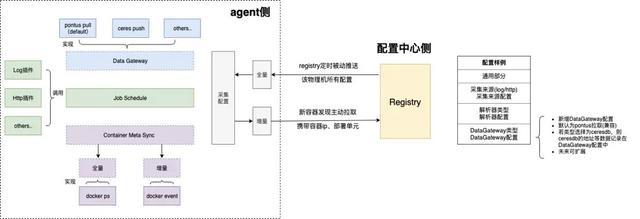
在Service Mesh 监控落地中,业务方参考业界标准输出 Metrics 指标数据,监控采集该物理机不同 Pod、App 和 Sidecar 的各项指标,包含 Metrics 指标和系统服务指标(CPU、MEM、DISK、JVM、IO 等),然后计算清洗集群节点通过拉取最近周期数据进行数据汇总、groupby 等,数据采集周期又分为:5秒级数据和分钟级数据。 对于 Service Mesh 来说,主要关注的指标有系统指标和 Metrics 指标:
- 系统指标(包括 Pod、App 和 MOSN 等 Sidecar 多个维度的系统指标): 系统指标, 包含 CPU、LOAD、MEM、BYTES、TCP、UCP 等信息; 磁盘,包含分区可用空间、使用率等信息; IO,包含 IOPS 等信息;
- Metrics 指标: PROCESSOR,包含 MOSN 进程打开的 fd 数量、申请的虚拟内存大小等进程资源信息; GO,包含 MOSN 进程 goroutine 数量(G)、thread 数量(M)以及 memstats 等 go runtime 信息; Downstream,包含全局下游累计建链数、总读取字节数、累计请求数、请求耗时等; Upstream,包含上游请求失败次数、集群累计建链数、累计断链数、异常断链次数、上游请求平均耗时等; MQ Mesh,包含发送消息总数、耗时、失败数等以及消费消息总数、耗时、失败数等; Gateway Mesh,包含 qps、rt、限流以及多维度的成功数和失败数等;
数据计算
对于 Agent 采集的数据需要从不同维度向上汇聚,满足不同用户对不同视角(LDC、IDC、APP、架构域、站点等视角)的数据需求,以适配蚂蚁金服运维架构体系。
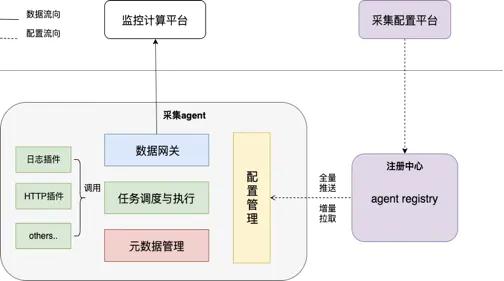
此时对于这么大规模的数据体系,我们团队建设蚂蚁金服统一的监控数据计算平台。
- 使用统一的监控数据标准、插件化的数据采集接入、通用的数据服务 API 服务来帮助不同的监控产品的快速迭代;
- 建立一套健全的数据质量体系、高可用计算集群来保障监控数据质量;
- 通过类 SQL 任务定义、自定义计算任务、插件化来提供丰富、开放的数据分析能力,来满足技术风险业务领域下各种复杂数据分析的需求;
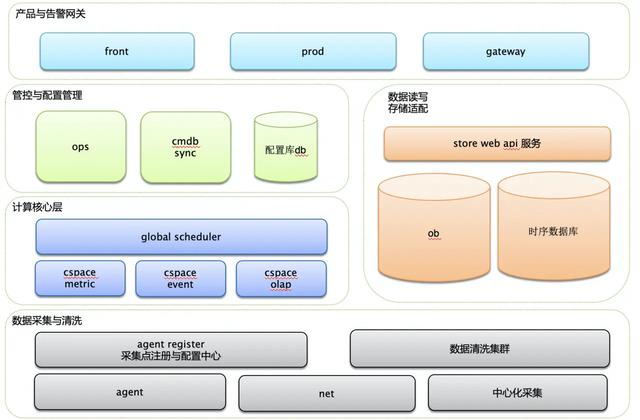
其中计算任务调度(spark)执行的关键组件包括 GS(Global-Scheduler 全局图调度)和 CS (Compute-Space 计算空间)。
GS 是平台的任务调度中心,如下图所示,它收集了所有业务的数据源配置,根据数据源之间的计算关系,构建出全局计算任务拓扑模型(GlobalGraph)。再根据不同的任务执行策略,将全局任务拓扑图切割成小范围的任务拓扑(Graph)。主要特性有:
- GS 根据任务优先级、资源质量、负载情况等策略,将 Graph 分发到不同的计算空间进行计算(Cspace);
- 同一个 Graph 内部的数据依赖是计算过程中直接依赖的;
- 不同的 Graph 之间的数据依赖会通过存储进行数据解耦;
- GS 会管理所有 Graph 及计算节点的任务状态,根据 Graph 的依赖关系和依赖 Graph 的执行状态,控制 Graph 的执行时间;
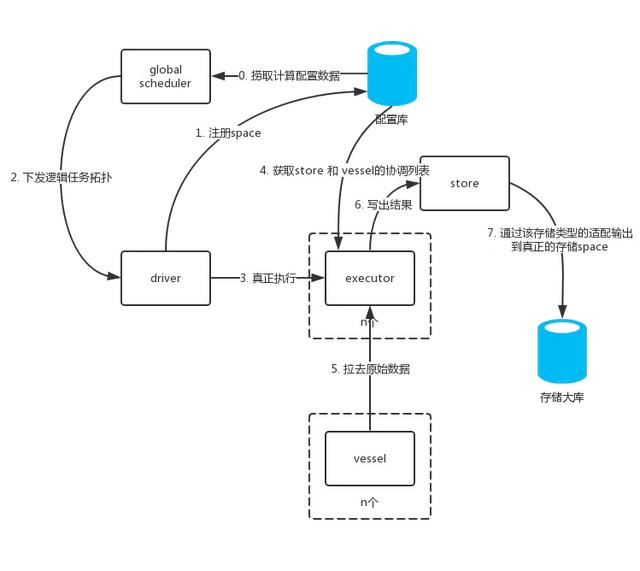
CS 是计算平台抽象的计算任务执行空间,如下图所示,主要负责 Graph 的解析和具体计算任务的提交执行,适用于不同的计算引擎,如 Spark/Flink。以 Spark 为例,CS 接收到 GS 发出的 GraphTask,根据 GraphTask 中的 Node(Transform) 解析成 Spark 的 Transfomation 算子和 Action 算子,组成计算 DAG 并提交到 Spark 集群执行。
在任务执行过程中,CS 会向 GS 同步各任务的执行状态,用于任务跟踪监控。

多个 CSpace 组成一个 CSpaceGroup,CSpace 之间可以根据负载均衡、资源等级、蓝绿发布等具体场景划分不同的计算分组,多个 CSpace 之间的任务切流可以满足负载均衡、资源隔离、蓝绿发布、灰度等高可用的要求。
规模化问题
对于蚂蚁金服这么大规模的 Service Mesh 集群数据,产品请求无法都通过 PromQL 方式实时查询结果,以及报警及时通知。此时我们对于监控数据进行分类,其中应用、机房、站点等维度数据进行预计算聚合,例如不同机房的 QPS、RPC 转发成功量、Error 错误等等,前端通过自定义配置出自己关注的大盘视图。
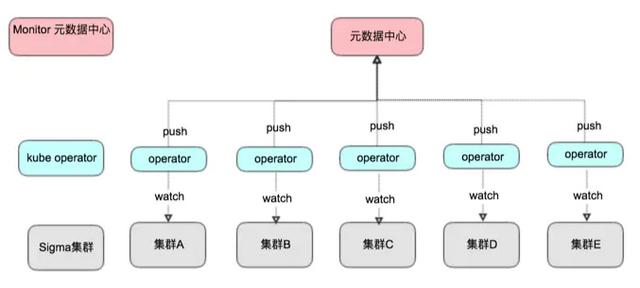
其中今年大促 MOSN 容器达到几十万,在频繁的发布部署,上线下线过程中,对监控查看的实时性提出更高的要求。其中 Meta 元数据模块对接 K8s 集群,部署监控 operator 监控容器状态变化,达到秒级将最新采集配置通过 Agent registry 更新到 Agent 模块。
大促保障
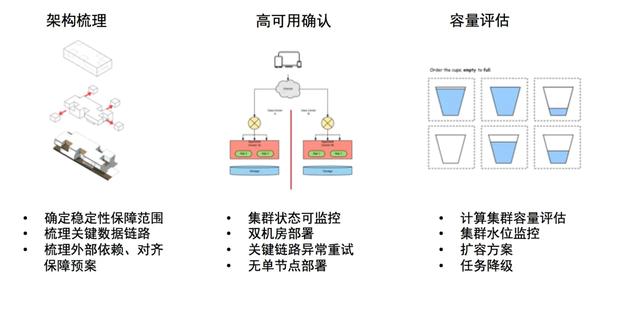
我们一方面对监控高可用进行保障,做到采集计算水平扩缩容,另一方面对容量进行评估,通过对不同任务进行分级处理,在大促的时候对高优先级任务进行重点保障,对低优先级任务和业务方进行沟通做降级处理。这样在监控计算资源紧张的情况下,保障核心数据稳定。
产品视角
Service Mesh 是蚂蚁金服内部应用服务所使用的基础服务设施,对不同的用户看的视角不一样。在监控产品上,用户对产品的使用主要集中在“配、看、用”数据这三个层面。我们早期也做过类似的用户分析。在蚂蚁金服按使用方式将用户分为全局关注者,产品 owner、SRE、领域专家和普通用户等,这里监控产品对于 Service Mesh 也提供不同的视角满足不同的用户需求,举例来说:
- 产品 Owner 视角:特指 MOSN 产品的开发们,他们重点负责 MOSN 的监控指标数据覆盖、数据准确性以及重点调优目标;
- 普通用户视角:特指应用 Owner,应用 Owner 主要看 MOSN 服务对应用 RPC 调用的影响以及该应用使用 MOSN 服务带来的效率提升;
- SRE 视角:他们关注全局视角,需要知道全部 MOSN 服务的稳定性,更注重预警、分析;
- 领域专家视角:特指对深度监控数据的使用者,比如深度的 JVM、CPU,Go 等指标,以及更深入的 perf、jfr 分析;
- 全局视角:特指架构师层次或全站维度关注者,关注全站应用服务领域;
应用 Owner
应用 Owner 对于这一新服务,期待又紧张,既期待这个 MOSN 服务可以给自己带来什么新的特性和服务,又担忧新服务给我又带来一层依赖和稳定性问题。此时对于产品上,在满足数据可观测性的同时,重点突出 MOSN 核心指标观测,以及 MOSN Error 的数据归档,同时告警能力及时适配,让开发 Owner 第一时间知道问题出在哪。
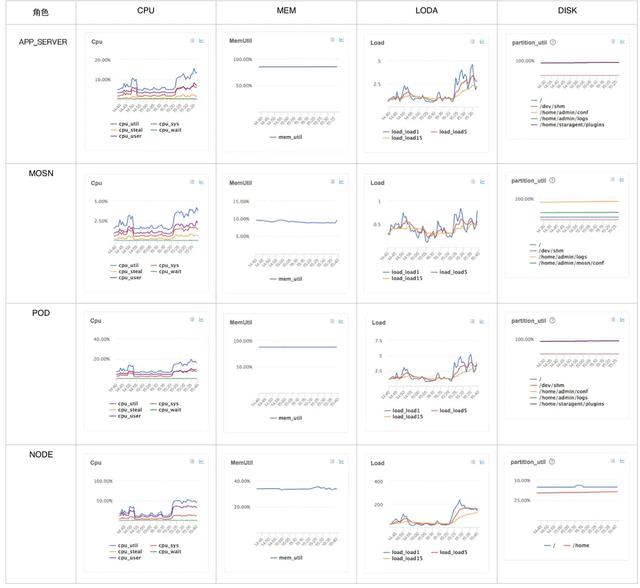
由于 MOSN 的部署模式是和应用容器是在同一个 Pod 里面,那么应用 Owner 这时会担心资源抢占问题,当然最终还是靠数据来验证,此时水位数据平铺对比必不可少。
MOSN 产品专家
MOSN 产品技术专家对自己新的服务充满信心,但是他们需要检验自己产品总体的性能指标以及性能调优,以达到最优化。所以一开始监控产品配合 MOSN 服务从线下到线上完成数据的覆盖和准确性校验,后来到核心指标的全局观测与对比。
在 MOSN 服务上线的过程中,打交道最多就是 MOSN 技术专家,类似 MOSN 大盘已经有应用维度汇聚的大盘展示,但是对于错误排查来说,全局的单机维度系统指标(cpu、mem、load) top n 更有意义,可以协助快速发现 CPU、MEM 异常的实例。
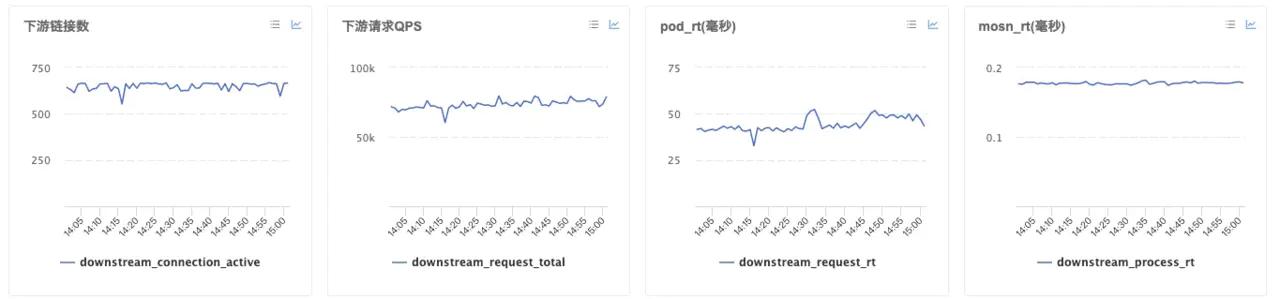
SRE 专家
SRE 专家们总是对新产品上线产生莫名的担忧,特别是今年蚂蚁金服 MOSN 服务这么大规模,所以此时需要充分数据做验证来达到上线的标准。此这时候又需要监控提供数据,特别是全站维度的数据,为此我们专门提供核心应用服务盯盘,在压测过程中观测核心应用 MOSN 的 rt、报错量以及 top 实例的水位等等。
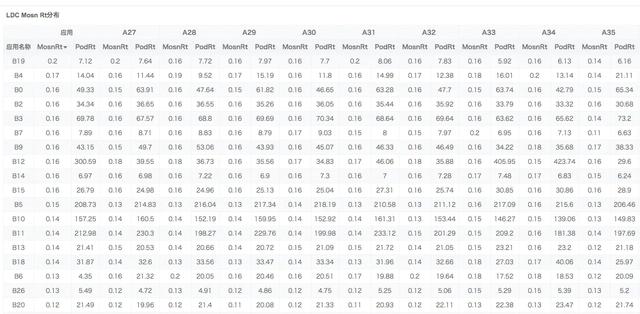
全局架构师
全局观测者当然关注核心指标,在了解 SRE 稳定性方案的同时,关注全部 MOSN 服务带来的性能提升,例如业务转发成功率,MOSN rt 等指标。
除了上述的这些基本产品能力以外,我们还尝试着从数据、功能、体验这些角度继续提升产品。
未来的思考
蚂蚁金服监控产品将致力于成为云原生时代的全栈监控,从应用到基础设施,从云、边到端,将技术风险领域的监控数据全部透明化,均具备一站式可观测能力。对内将支撑技术风险各个领域的业务场景,包括应急、容量、限流、安全、变更、大促等,对外将支撑科技输出、云产品、国际赋能和商业化。
后续重点方向有 Monitoring as a Service,旨在让业务研发和 SRE 同学通过 Code 方式完成从监控数据采集、数据聚合、预警规则配置、大盘 CMS 报表展现等功能,提升监控业务场景的便利性、灵活性和创造性,为监控领域丰富多彩的玩法带来更多可能。
最后,也欢迎志同道合的伙伴加入我们,一起参与金融级监控系统架构设计和创新。
小结:
最后小编整理了一份Java相关的资料,需要的小伙伴可以加我微信即可免费领取!

放一些大概截图,感兴趣的小伙伴可以收着。

java面试题及大厂真题
大量电子书
知识点相关面试题
以上是关于蚂蚁金服在 Service Mesh 监控落地经验总结的主要内容,如果未能解决你的问题,请参考以下文章
蚂蚁金服大规模微服务架构下的Service Mesh探索之路