Pandas —— 基础数据结构概念和创建
Posted long5683
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas —— 基础数据结构概念和创建相关的知识,希望对你有一定的参考价值。
@
目录
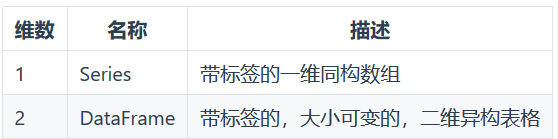
一、Pandas简介
1.1 数据结构
1.2 大小可变与数据复制
-
Pandas 所有数据结构的值都是可变的,但数据结构的大小并非都是可变的,比如,Series 的长度不可改变,但 DataFrame 里就可以插入列。
-
Pandas 里,绝大多数方法都不改变原始的输入数据,而是复制数据,生成新的对象。 一般来说,原始输入数据不变更稳妥。
二、Series 数据结构
2.1 Series简介
Series 是带有标签的一维数组,可以保存任何数据类型(整数,字符串,浮点数,Python对象等),轴标签统称为索引
s = pd.Series(np.random.rand(5))
print(s)
print(type(s))
# 查看数据、数据类型
print(s.index,type(s.index))
print(s.values,type(s.values))
# .index查看series索引,类型为rangeindex
# .values查看series值,类型是ndarray
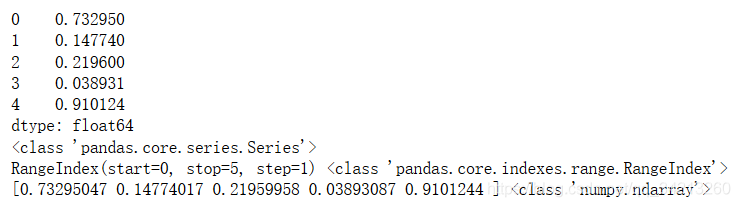
核心:series相比于ndarray,是一个自带索引index的数组 → 一维数组 + 对应索引
所以当只看series的值的时候,就是一个ndarray。 series和ndarray较相似,索引切片功能差别不大 series和dict相比,series更像一个有顺序的字典(dict本身不存在顺序),其索引原理与字典相似(一个用key,一个用index)
2.2 Series 创建方法
2.2.1 由字典创建
字典的key就是index,values就是values
dic = {‘a‘:1 ,‘b‘:2 , ‘c‘:3, ‘4‘:4, ‘5‘:5}
s = pd.Series(dic)
2.2.2 由数组创建(一维数组)
arr = np.random.randn(5)
s = pd.Series(arr)
# 默认index是从0开始,步长为1的数字
# 也可以自己设置index,dtype和 name参数
s = pd.Series(arr, index = [‘a‘,‘b‘,‘c‘,‘d‘,‘e‘],dtype = np.object, name = ‘test‘)
# index参数:设置index,长度保持一致
# dtype参数:设置数值类型
# name为Series的一个参数,创建一个数组的名称,格式为str,如果没用定义输出名称,输出为None
重命名
# .rename()重命名一个数组的名称,并且新指向一个数组,原数组不变
s2 = s.rename(‘hehehe‘)
三、Dataframe数据结构
3.1 Dataframe简介
"二维数组"Dataframe:是一个表格型的数据结构,“带有标签的二维数组”。包含一组有序的列,其列的值类型可以是数值、字符串、布尔值等。
Dataframe中的数据以一个或多个二维块存放,Dataframe带有index(行标签)和columns(列标签)(不是列表、字典或一维数组结构。)
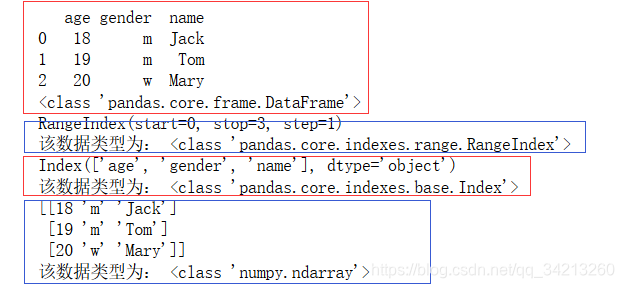
data = {‘name‘:[‘Jack‘,‘Tom‘,‘Mary‘],
‘age‘:[18,19,20],
‘gender‘:[‘m‘,‘m‘,‘w‘]}
frame = pd.DataFrame(data)
print(frame‘
该数据类型为:‘,type(frame)) # 查看数据,数据类型为dataframe
print(frame.index,‘
该数据类型为:‘,type(frame.index))# .index查看行标签
print(frame.columns,‘
该数据类型为:‘,type(frame.columns))# .index查看行标签
print(frame.values,‘
该数据类型为:‘,type(frame.values))# .values查看值,数据类型为ndarray
# to_list()数据类型转换成列表
frame.index.to_list()
frame.columns.to_list()
frame.values.to_list()
3.2 Dataframe创建方法
3.2.1 由数组/list组成的字典创建
# 由数组/list组成的字典 创建Dataframe,columns为字典key,index为默认数字标签
# 字典的值的长度必须保持一致!
data1 = {‘a‘:[1,2,3],
‘b‘:[3,4,5],
‘c‘:[5,6,7]}
data2 = {‘one‘:np.random.rand(3),
‘two‘:np.random.rand(3)} # 这里如果尝试 ‘two‘:np.random.rand(4) 会怎么样?
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 和Series一样也可以自己设置参数值
df1 = pd.DataFrame(data1, columns = [‘b‘,‘c‘,‘a‘,‘d‘])
df2 = pd.DataFrame(data2, index = [‘f1‘,‘f2‘,‘f3‘])
3.2.2 由Series组成的字典创建
data1 = {‘one‘:pd.Series(np.random.rand(2)),
‘two‘:pd.Series(np.random.rand(3))} # 没有设置index的Series
data2 = {‘one‘:pd.Series(np.random.rand(2), index = [‘a‘,‘b‘]),
‘two‘:pd.Series(np.random.rand(3),index = [‘a‘,‘b‘,‘c‘])} # 设置了index的Series
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
3.2.3 通过二维数组直接创建
ar = np.random.rand(9).reshape(3,3)
df2 = pd.DataFrame(ar, index = [‘a‘, ‘b‘, ‘c‘], columns = [‘one‘,‘two‘,‘three‘]) # 可以尝试一下index或columns长度不等于已有数组的情况
打赏
码字不易,如果对您有帮助,就打赏一下吧O(∩_∩)O


以上是关于Pandas —— 基础数据结构概念和创建的主要内容,如果未能解决你的问题,请参考以下文章