领域驱动设计实践,精通业务,面向对象编程,面条编程,过程编程
Posted huangchanghuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了领域驱动设计实践,精通业务,面向对象编程,面条编程,过程编程相关的知识,希望对你有一定的参考价值。
背景介绍
近年来,苏宁集团业务不断扩大,用户快速增长,线上线下融合不断深入,系统的复杂性越来越高,技术的广度和深度都在不断拓展。
在整个集团技术不断迭代演进的过程中,集团内各个系统也同步更新、迭代、重构,快速适应技术的发展,满足业务增长的需求。
苏宁金融会员系统作为苏宁金融的一级系统,从易付宝诞生开始就作为基础支撑系统为整个金融业务系统提供会员服务。经过多年的演化和业务版本的迭代维护,到如今代码调用错综复杂,各个逻辑散落在代码的各个角落,牵一发而动全身。而且这些业务逻辑基本都集中落在了代码的 Biz 层中,导致 Biz 层臃肿庞大。
为了适应苏宁业务的快速发展,跟进苏宁集团多活架构的演进,金融会员系统的技术架构需要再一次跃迁。
架构选型
重构系统的架构选型是一个仁者见仁智者见智的事情,没有哪一种模式是标准答案,只能追求更适合的选项。本次对金融会员系统重构,从框架选型到架构选型都做了新的选择,选择了 Spring+Mybatis+Mycat+mysql 的技术框架和 DDD+CQRS+ 插件的架构模式。
领域驱动设计(DDD,Domain-Driven Design)作为这一次系统重构的架构选型,主要考虑到以下因素:
-
DDD 模式更加关注业务领域,能够使得苏宁金融会员系统更加聚焦会员产品的核心业务。
-
DDD 模式采用面向对象的设计,将系统模块化,有利于实现软件模块的高内聚和低耦合,使得会员系统更加适合应对苏宁业务的快速迭代。
技术实现
领域驱动设计实践
DDD 模式的最大优势在于聚焦产品核心业务,最难搞定的也在此处。那么该如何实现呢?领域驱动设计的关键在领域模型,如果把领域模型拆开来看,如下图,就不难理解了。
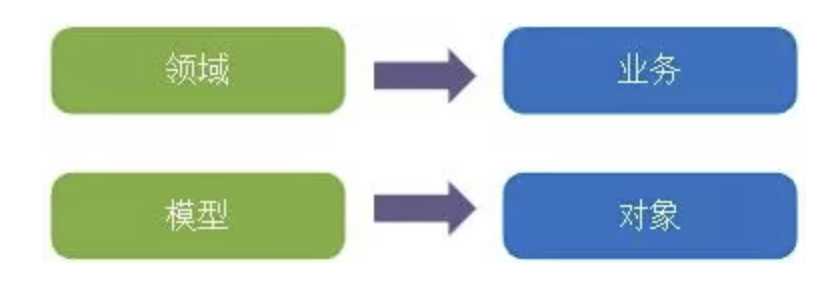
图 1 领域驱动设计拆分
那么,理解领域驱动设计就变成如下四点内容:
1. 精通业务
精通业务,需要业务专家,对于互联网产品,产品经理就是业务专家。技术人员作为重构发起方,需要不断和产品经理讨论业务,梳理出业务流程中隐藏的数据信息。例如会员系统的开户服务,产品经理给出的业务流程如下:
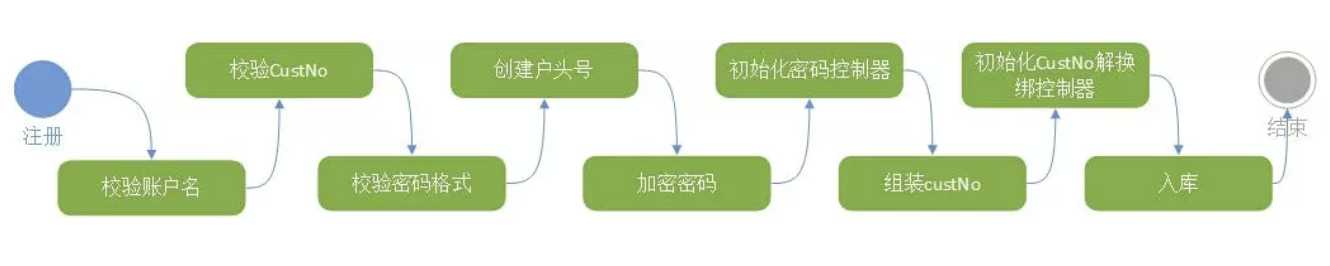
图 2 面向过程的开发模式
上面流程看似很清晰,按着常规思路,上面每一步对应一段代码,按这种方式写出来的代码,就是大家常说的面条代码(或者事务脚本)。
如果采用领域驱动设计的模式来做的话,会怎么样?首先,和产品经理讨论,注册流程涉及哪些操作步骤,各个步骤涉及哪些数据;然后,将各个步骤的数据和对应的操作包装起来成为一个一个对象;最后,和产品经理讨论这些对象还应该具有哪些功能,各个业务功能模块分属于哪些对象。和产品经理的沟通不再是基于业务流程,而是基于业务模型。那么注册流程应该如下图所示:
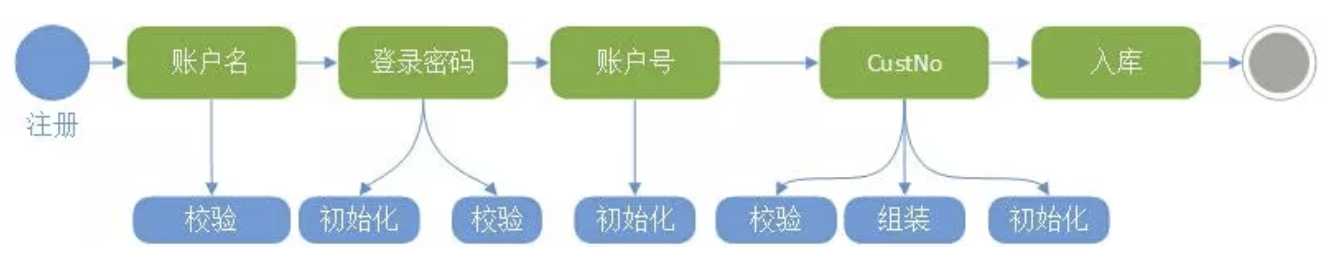
图 3 面向对象的开发模式
2. 精通面向对象编程
在 DDD 模式中将对象分为 ValueObject 和 Entity。ValueObject 代表的是值对象,比如一个地址“南京市玄武区徐庄软件园”,该地址没有生命周期,可以通过对象拷贝关联到任何一个在徐庄软件园的个人账户,这就是一个 ValueObject。而 Entity 对象是有生命周期的,可以唯一标识的,该对象只能属于某一个业务,比如 LoginPassword,一个 LoginPassword 对象只能属于某一个 Account 所有,不能任意拷贝,并伴随 Account 注册而初始化,随着 Account 注销而删除。
采用面向对象的编程,合理的组织对象之间的关联、聚合、组合关系,能够更好的遵循 SOLID 原则,能够更好管理对象。例如易购账号(CustNo)和易付宝账号(UserNo)绑定关系,对于易付宝来讲一个账号要么建立绑定关系要么没有建立绑定关系。如果建立绑定关系了,一个易购账号一定对应一个易付宝账号,那么当我们在易付宝会员侧建立 CustNo 领域对象时,和 UserNo 对象之间就是聚合的关系。当一个绑定关系建立时,该绑定关系对应的绑定关系控制器(EgoBindCtrl)也同时创建,但是一个 EgoBindCtrl 只对应一个绑定关系,如果绑定关系不存在了,那么 EgoBindCtrl 也没有存在的必要了,此时 CustNo 对象和 EgoBindCtrl 对象之间就是组合的关系,如下图:
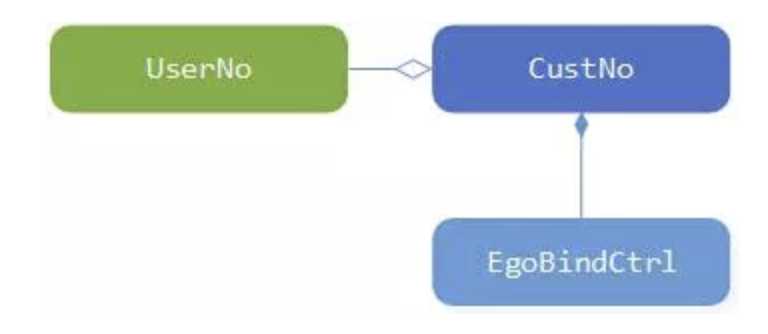
图 4 对象关系示意图
3. 对象创建
通过上面两步,有了领域建模的思路,接下来需要考虑对象怎么创建的问题了。苏宁金融会员系统已经运行超过 8 年时间,拥有超过 3 亿用户,这么大的数据量,如果对表结构进行重构,是不太现实的,保持现有的数据结构,对于表结构和领域对象之间的映射关系是复杂的。我们采用 Repository 对 Domain 进行数据转化,在 Repository 中将 DMO 转化为 Domain,这里有两种模式可选择:
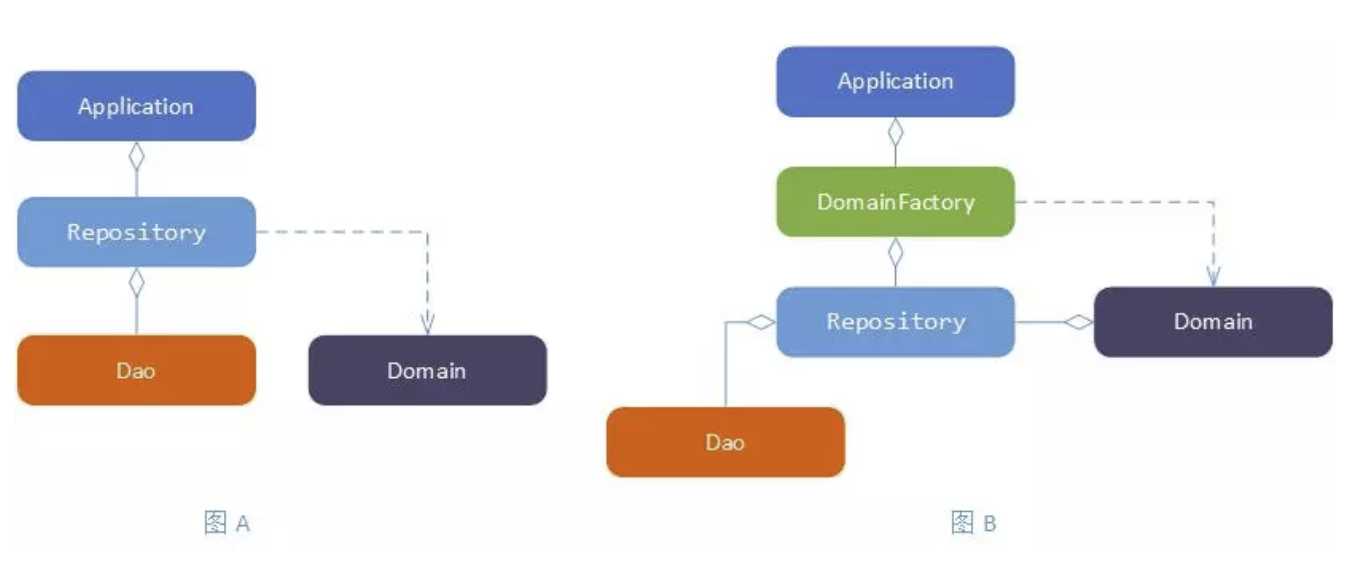
图 5 领域模型对象创建模式对比
如上方式中 Application,DomainFactory,Repository,Dao 都是采用 Spring 单例的方式管理,通过注入的方式集成,Domain 是根据业务需要 new 出来的。
如图 A 的方式,在应用层(Application)注入 Repository 服务,在 Repository 中转化 Domain 对象,这种方式简单直接,但是很容易将 Repository 的服务做成事务脚本的模式,结果将业务由 Domain 转移到 Repository 的服务中来,做成了伪 DDD 模式。如图 B 的方式,在应用层(Application)注入 DomainFactory 服务,在 DomainFactory 中构建 Domain 对象时将 Repository 服务导入到 Domain 对象中。Application 无法直接调用 Repository 服务,只能通过 Domain 来操作 Repository 服务,这样避免了 Repository 作为上帝之手的角色。将业务封装在 Domain 中,最大可能的避免 Repository 的臃肿。
4. 对象的聚合
做到上面三点之后,发现这不就是面向对象编程吗?为什么起一个领域驱动设计这样高大上的名字呢?没错,完成上面三项之后,就解决了 DDD 模式的大部分问题,还剩下的一个问题就是业务聚合。我们已经将业务封装在模型中,但是不可能把一个领域的所有业务都封装在一个模型中,为了完成一个领域业务会创建一系列模型,还需要考虑这些模型之间的关系,将一个模块的业务聚合在一个聚合根下面,同一个聚合根下的所有对象只能拥有唯一的访问入口,来保证聚合内部的一致性。例如 PaymentPassword 业务,同时还需要 PayPwdCtrl 来对支付密码进行校验控制,对 PayPwdCtrl 的访问只能通过 PaymentPassword 的入口来完成。
如何避免低效的查询服务
苏宁金融会员系统,不仅对外提供注册、激活、帐密安全管理等用户生命周期的动作,同时还对多个外系统提供数据查询服务。很多查询服务查询的数据会跨越多个聚合领域,如果查询服务经过领域模型,势必存在效率问题。因此,有必要引入另外一个设计模式读写分离设计(CQRS)。
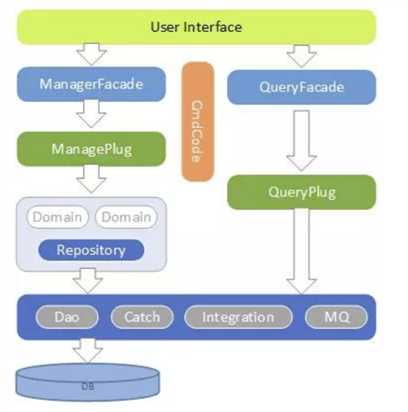
图 6 CQRS 设计图
业内有比较成熟的 CQRS+Event Sourcing 模式,但是事件溯源(Event Sourcing)比较复杂,而且对数据存储需要重新设计,所以在会员系统重构设计上抛弃了事件溯源模式,单独采用 CQRS 模式。
如何做读写分离设计
读写分离本身是一个比较朴素的设计,在系统中我们常用到缓存读写分离,数据库读写分离,那么服务读写分离应该如何设计呢?在系统架构上,通常采用水平拆分来提高程序的伸缩性,采用垂直拆分来提高程序的可扩展性。垂直拆分应当是按业务来拆分,下图 B 按读写分离进行垂直拆分打破了业务内聚属性,会增加后期维护难度。
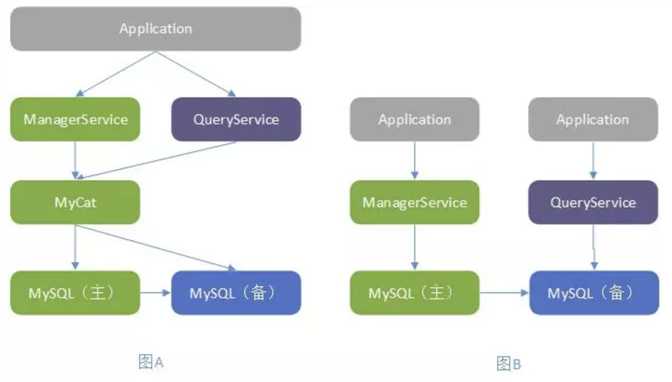
图 7 读写分离设计
为了保证业务的内聚,会员服务系统采用图 A 这种方式,所有业务落在一个系统内部。在代码上实现读写分离,使用插件结构,将读写在设计上分离开来,对读写代码分开维护,独立演化,业务上保持一个系统的内聚。
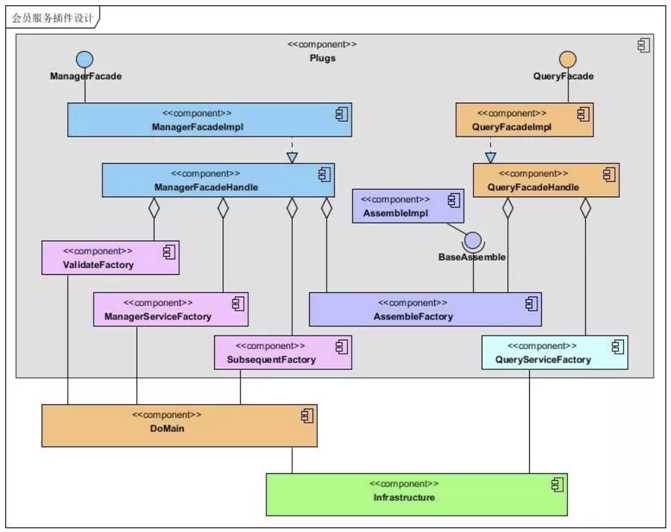
图 8 基础插件设计图
如何实现插件模式设计
插件模式就是将系统开发看成是搭积木,将一个个功能模块做成一个个小积木。当需要一个完整功能,只需要将积木拼装在一起就可以了,模块在不同的功能之间可以重用。在设计上 Spring 的 IoC 恰巧给我们提供了便利性,利用 Spring 容器来管理我们的插件,当某一个接口需要某一个插件,直接注入就可以。当然,这里还需要我们定义好标准的插口(接口)。下面给出写服务(ManagerService)代码示例。
1、首先需要一个插件组装框架,这个框架通过一个抽象类 Handle 来完成,如下所示:
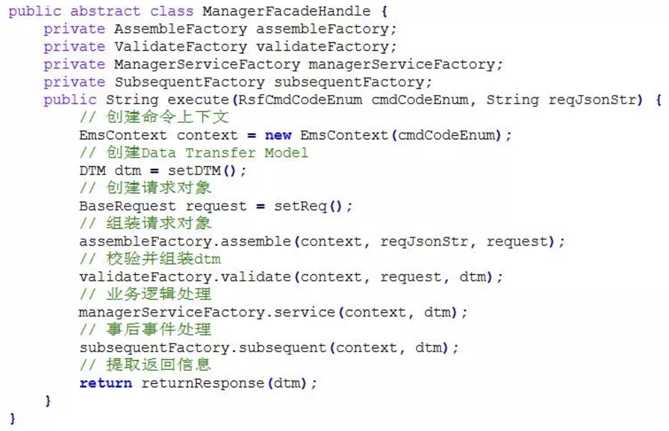
2、如上框架中列出了四个层级的插件,分别是 Assemble(入参组装与校验)、Validate(业务校验)、Manager(业务事务)、Subsequent(事务后业务)。针对框架中的各个插件结构层级,需要一个对应的插件工厂(Factory)来组装该层级的多个插件,如下列举了 Manager 插件工厂代码:
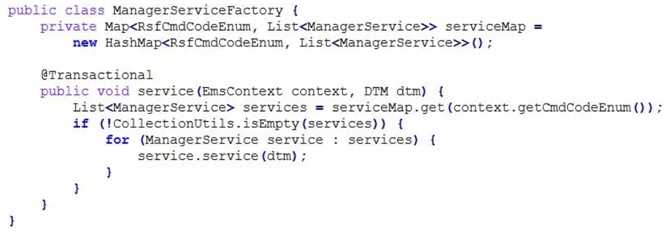
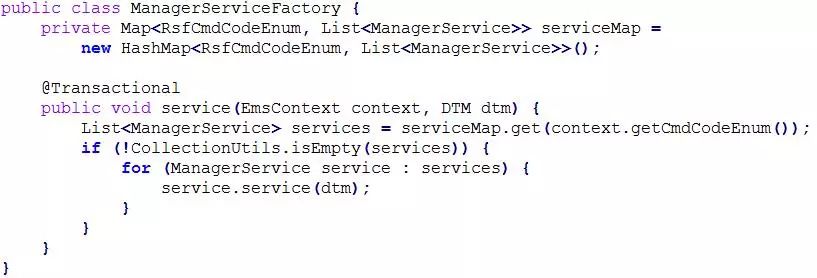
3、在上面的插件组装框架 Handle 中还有一个对象 EmsContext,该对象构建时传入了 RsfCmdCodeEnum。这个 RsfCmdCodeEnum 是一个至关重要的变量,这个变量由具体接口传入的,每一个接口对应唯一的 CmdCode,下面是一个快速注册接口的接口代码:

4、接下来就需要对这个接口注入各层级的插件了,我们把插件组装放在一个名为 beans-manager-facade.xml 的 XML 文件中,如下例举了一个接口的配置:
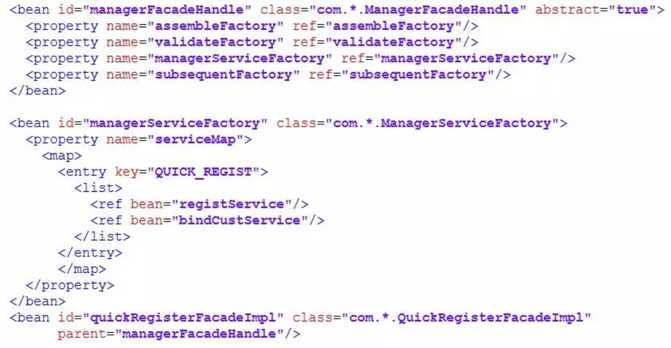
如上 registService,bindCustService 这两个服务都是 Spring 的 Bean,通过这种方式将多个服务插件组装为一个大的接口级服务对外提供,不同的接口可以共用插件。
总 结
本次对苏宁金融会员服务系统重构,采用恰当的设计模式,提高了系统的性能;完成了与异地多活的技术对接,提高系统的可靠性;增加了系统的可维护性,提高了系统的维护开发效率。
重构提高了系统的性能
例如,采用短事务,减少事务时间,提高了系统的性能。在老框架代码中对于业务事务的管理是放在 Biz 层中接口进行统一管理,这样带来一个问题,如果接口中还依赖别的系统接口,会增加整个事务时间,导致一个事务长时间占着数据库锁无法释放。本次重构之后的新代码,采用插件模式,只在 Service 插件中使用事务,这样缩小了事务范围,减少了事务时间,显著提高了系统的性能。
重构降低了系统的响应时间
例如使用异步的方式管理 Subsequent(事务后业务),缩短了接口响应时间。在互联网系统演进中,随着业务不断增长,系统越来越多,系统间的交互也越来越多。当一个系统处理完当前系统的数据更新之后,往往还需要处理一系列事后工作,来完成和其他系统的交互,这些交互有些需要本地计算,有些是同步交互,这些交互会增加接口响应耗时,本次重构设计了统一的事后异步方式,对于本系统不关心的结果并且处理起来耗时的事后工作,采用异步的方式来完成,提高了接口的响应时间。
重构增加系统的可维护性
例如重构代码采用插件模式和边界清晰的领域模型,增加了索引数据维护的便利性。系统按着多活改造的需求,需要放弃之前的商用数据库,采用 Mycat+MySQL 分库分表的方式存储数据,原本可以通过多个不同的查询条件查询数据,现在只能通过分库分表字段来查询数据,如果需要通过别的字段条件查询数据,需要对该字段创建索引表。先通过索引表检索分库分表字段,再通过分库分表字段检索数据。例如苏宁金融业务中分库分表字段使用会员编号,那么用户登录时使用的是用户名,此时需要通过用户名获取用户信息,再对用户名建立索引表。
索引表的维护比较麻烦,涉及业务场景多了,容易遗漏数据,系统并发高了,容易带来脏数据。对索引数据的维护,需要达到两个要求:
-
必须容易维护,将索引代码和业务代码解耦;
-
杜绝脏数据,索引数据必须和业务数据具有强一致性。
如果单看第一条,采用异步事件就可以完成,但是加上第二条,异步事件就无法满足了。
在本次重构中,得益于 DTM(Data Transfer Model)的设计,采用统一上下文数据,业务维护只需要提取出需要维护的索引数据,塞到 DTM 中,具体的索引维护的事情交给框架去做。
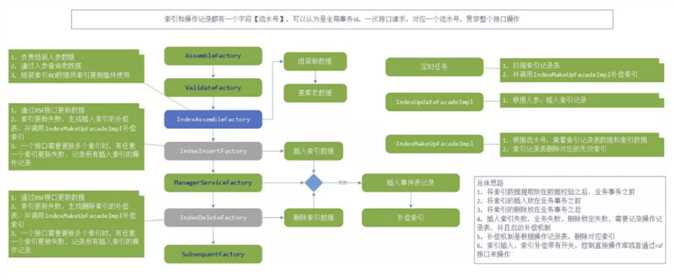
图 9 索引更新设计
对于苏宁金融会员服务系统的系统重构,是我们尝试使用领域驱动设计的第一个案例,但不会是最后一个案例,希望借此设计模式,能够打通产品和研发沟通的墙,使得双方都能够从业务领域模型中受益,使得系统能够更加聚焦产品核心业务价值,快速适应苏宁金融业务的发展变化。
如果你喜欢本文,更多领域驱动设计文章,交流群
请长按二维码,关注

转发至 朋友圈,是对我最大的支持
背景介绍
近年来,苏宁集团业务不断扩大,用户快速增长,线上线下融合不断深入,系统的复杂性越来越高,技术的广度和深度都在不断拓展。
在整个集团技术不断迭代演进的过程中,集团内各个系统也同步更新、迭代、重构,快速适应技术的发展,满足业务增长的需求。
苏宁金融会员系统作为苏宁金融的一级系统,从易付宝诞生开始就作为基础支撑系统为整个金融业务系统提供会员服务。经过多年的演化和业务版本的迭代维护,到如今代码调用错综复杂,各个逻辑散落在代码的各个角落,牵一发而动全身。而且这些业务逻辑基本都集中落在了代码的 Biz 层中,导致 Biz 层臃肿庞大。
为了适应苏宁业务的快速发展,跟进苏宁集团多活架构的演进,金融会员系统的技术架构需要再一次跃迁。
架构选型
重构系统的架构选型是一个仁者见仁智者见智的事情,没有哪一种模式是标准答案,只能追求更适合的选项。本次对金融会员系统重构,从框架选型到架构选型都做了新的选择,选择了 Spring+Mybatis+Mycat+MySQL 的技术框架和 DDD+CQRS+ 插件的架构模式。
领域驱动设计(DDD,Domain-Driven Design)作为这一次系统重构的架构选型,主要考虑到以下因素:
-
DDD 模式更加关注业务领域,能够使得苏宁金融会员系统更加聚焦会员产品的核心业务。
-
DDD 模式采用面向对象的设计,将系统模块化,有利于实现软件模块的高内聚和低耦合,使得会员系统更加适合应对苏宁业务的快速迭代。
技术实现领域驱动设计实践
DDD 模式的最大优势在于聚焦产品核心业务,最难搞定的也在此处。那么该如何实现呢?领域驱动设计的关键在领域模型,如果把领域模型拆开来看,如下图,就不难理解了。
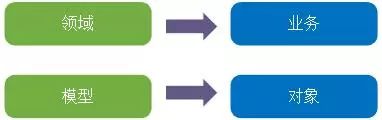
图 1 领域驱动设计拆分
那么,理解领域驱动设计就变成如下四点内容:
1. 精通业务
精通业务,需要业务专家,对于互联网产品,产品经理就是业务专家。技术人员作为重构发起方,需要不断和产品经理讨论业务,梳理出业务流程中隐藏的数据信息。例如会员系统的开户服务,产品经理给出的业务流程如下:

图 2 面向过程的开发模式
上面流程看似很清晰,按着常规思路,上面每一步对应一段代码,按这种方式写出来的代码,就是大家常说的面条代码(或者事务脚本)。
如果采用领域驱动设计的模式来做的话,会怎么样?首先,和产品经理讨论,注册流程涉及哪些操作步骤,各个步骤涉及哪些数据;然后,将各个步骤的数据和对应的操作包装起来成为一个一个对象;最后,和产品经理讨论这些对象还应该具有哪些功能,各个业务功能模块分属于哪些对象。和产品经理的沟通不再是基于业务流程,而是基于业务模型。那么注册流程应该如下图所示:

图 3 面向对象的开发模式
2. 精通面向对象编程
在 DDD 模式中将对象分为 ValueObject 和 Entity。ValueObject 代表的是值对象,比如一个地址“南京市玄武区徐庄软件园”,该地址没有生命周期,可以通过对象拷贝关联到任何一个在徐庄软件园的个人账户,这就是一个 ValueObject。而 Entity 对象是有生命周期的,可以唯一标识的,该对象只能属于某一个业务,比如 LoginPassword,一个 LoginPassword 对象只能属于某一个 Account 所有,不能任意拷贝,并伴随 Account 注册而初始化,随着 Account 注销而删除。
采用面向对象的编程,合理的组织对象之间的关联、聚合、组合关系,能够更好的遵循 SOLID 原则,能够更好管理对象。例如易购账号(CustNo)和易付宝账号(UserNo)绑定关系,对于易付宝来讲一个账号要么建立绑定关系要么没有建立绑定关系。如果建立绑定关系了,一个易购账号一定对应一个易付宝账号,那么当我们在易付宝会员侧建立 CustNo 领域对象时,和 UserNo 对象之间就是聚合的关系。当一个绑定关系建立时,该绑定关系对应的绑定关系控制器(EgoBindCtrl)也同时创建,但是一个 EgoBindCtrl 只对应一个绑定关系,如果绑定关系不存在了,那么 EgoBindCtrl 也没有存在的必要了,此时 CustNo 对象和 EgoBindCtrl 对象之间就是组合的关系,如下图:
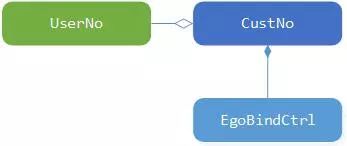
图 4 对象关系示意图
3. 对象创建
通过上面两步,有了领域建模的思路,接下来需要考虑对象怎么创建的问题了。苏宁金融会员系统已经运行超过 8 年时间,拥有超过 3 亿用户,这么大的数据量,如果对表结构进行重构,是不太现实的,保持现有的数据结构,对于表结构和领域对象之间的映射关系是复杂的。我们采用 Repository 对 Domain 进行数据转化,在 Repository 中将 DMO 转化为 Domain,这里有两种模式可选择:
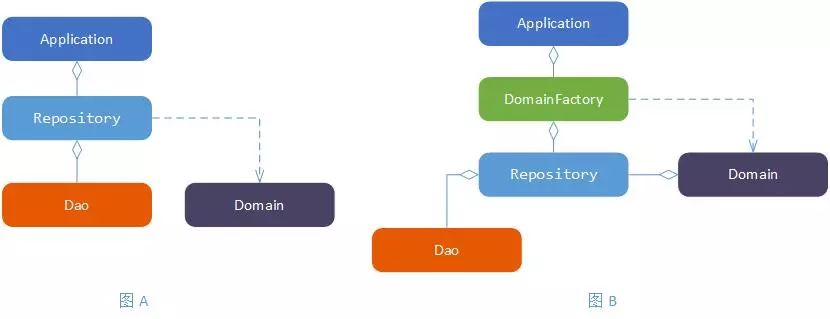
图 5 领域模型对象创建模式对比
如上方式中 Application,DomainFactory,Repository,Dao 都是采用 Spring 单例的方式管理,通过注入的方式集成,Domain 是根据业务需要 new 出来的。
如图 A 的方式,在应用层(Application)注入 Repository 服务,在 Repository 中转化 Domain 对象,这种方式简单直接,但是很容易将 Repository 的服务做成事务脚本的模式,结果将业务由 Domain 转移到 Repository 的服务中来,做成了伪 DDD 模式。如图 B 的方式,在应用层(Application)注入 DomainFactory 服务,在 DomainFactory 中构建 Domain 对象时将 Repository 服务导入到 Domain 对象中。Application 无法直接调用 Repository 服务,只能通过 Domain 来操作 Repository 服务,这样避免了 Repository 作为上帝之手的角色。将业务封装在 Domain 中,最大可能的避免 Repository 的臃肿。
4. 对象的聚合
做到上面三点之后,发现这不就是面向对象编程吗?为什么起一个领域驱动设计这样高大上的名字呢?没错,完成上面三项之后,就解决了 DDD 模式的大部分问题,还剩下的一个问题就是业务聚合。我们已经将业务封装在模型中,但是不可能把一个领域的所有业务都封装在一个模型中,为了完成一个领域业务会创建一系列模型,还需要考虑这些模型之间的关系,将一个模块的业务聚合在一个聚合根下面,同一个聚合根下的所有对象只能拥有唯一的访问入口,来保证聚合内部的一致性。例如 PaymentPassword 业务,同时还需要 PayPwdCtrl 来对支付密码进行校验控制,对 PayPwdCtrl 的访问只能通过 PaymentPassword 的入口来完成
如何避免低效的查询服务
苏宁金融会员系统,不仅对外提供注册、激活、帐密安全管理等用户生命周期的动作,同时还对多个外系统提供数据查询服务。很多查询服务查询的数据会跨越多个聚合领域,如果查询服务经过领域模型,势必存在效率问题。因此,有必要引入另外一个设计模式读写分离设计(CQRS)。
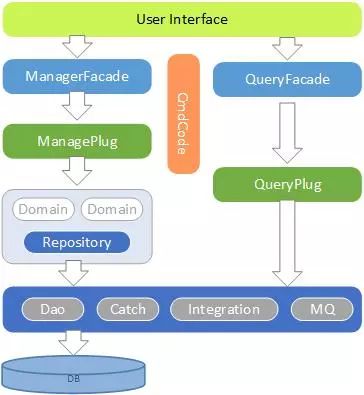
图 6 CQRS 设计图
业内有比较成熟的 CQRS+Event Sourcing 模式,但是事件溯源(Event Sourcing)比较复杂,而且对数据存储需要重新设计,所以在会员系统重构设计上抛弃了事件溯源模式,单独采用 CQRS 模式。
如何做读写分离设计
读写分离本身是一个比较朴素的设计,在系统中我们常用到缓存读写分离,数据库读写分离,那么服务读写分离应该如何设计呢?在系统架构上,通常采用水平拆分来提高程序的伸缩性,采用垂直拆分来提高程序的可扩展性。垂直拆分应当是按业务来拆分,下图 B 按读写分离进行垂直拆分打破了业务内聚属性,会增加后期维护难度。
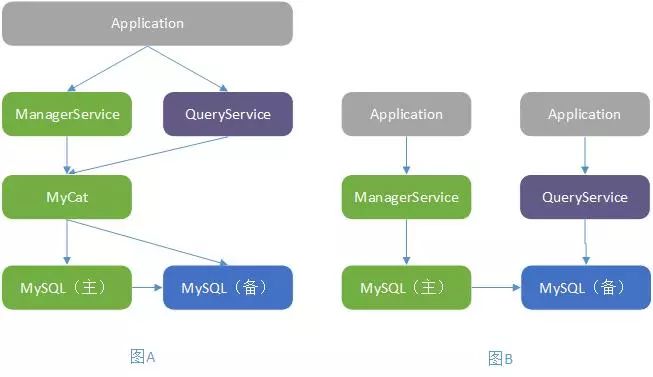
图 7 读写分离设计
为了保证业务的内聚,会员服务系统采用图 A 这种方式,所有业务落在一个系统内部。在代码上实现读写分离,使用插件结构,将读写在设计上分离开来,对读写代码分开维护,独立演化,业务上保持一个系统的内聚。
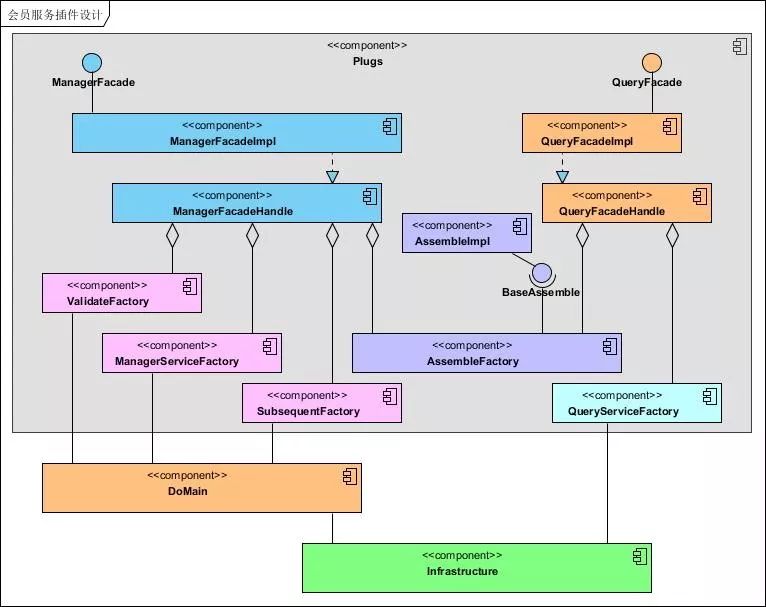
图 8 基础插件设计图
如何实现插件模式设计
插件模式就是将系统开发看成是搭积木,将一个个功能模块做成一个个小积木。当需要一个完整功能,只需要将积木拼装在一起就可以了,模块在不同的功能之间可以重用。在设计上 Spring 的 IoC 恰巧给我们提供了便利性,利用 Spring 容器来管理我们的插件,当某一个接口需要某一个插件,直接注入就可以。当然,这里还需要我们定义好标准的插口(接口)。下面给出写服务(ManagerService)代码示例。
1、首先需要一个插件组装框架,这个框架通过一个抽象类 Handle 来完成,如下所示:
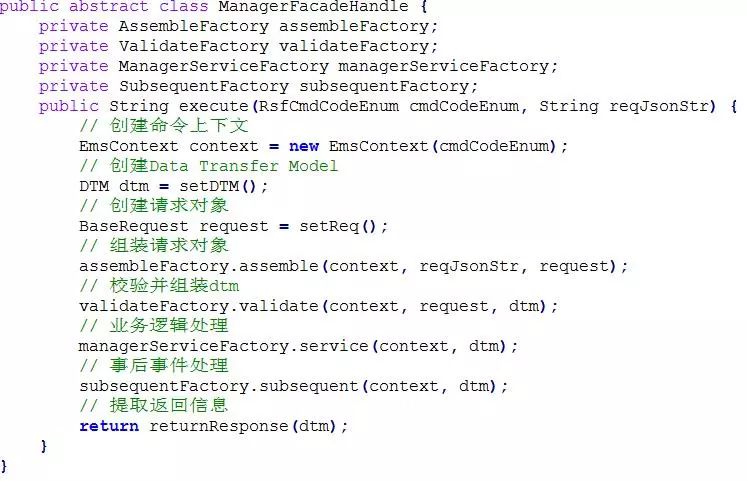
2、如上框架中列出了四个层级的插件,分别是 Assemble(入参组装与校验)、Validate(业务校验)、Manager(业务事务)、Subsequent(事务后业务)。针对框架中的各个插件结构层级,需要一个对应的插件工厂(Factory)来组装该层级的多个插件,如下列举了 Manager 插件工厂代码:
3、在上面的插件组装框架 Handle 中还有一个对象 EmsContext,该对象构建时传入了 RsfCmdCodeEnum。这个 RsfCmdCodeEnum 是一个至关重要的变量,这个变量由具体接口传入的,每一个接口对应唯一的 CmdCode,下面是一个快速注册接口的接口代码:
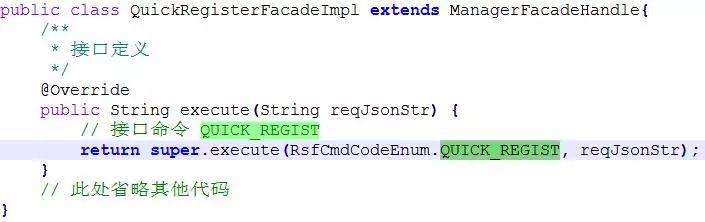
4、接下来就需要对这个接口注入各层级的插件了,我们把插件组装放在一个名为 beans-manager-facade.xml 的 XML 文件中,如下例举了一个接口的配置:
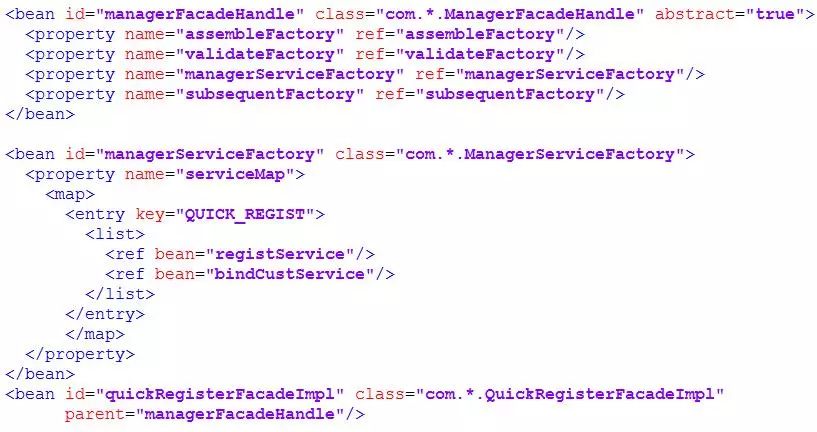
如上 registService,bindCustService 这两个服务都是 Spring 的 Bean,通过这种方式将多个服务插件组装为一个大的接口级服务对外提供,不同的接口可以共用插件。
总 结
本次对苏宁金融会员服务系统重构,采用恰当的设计模式,提高了系统的性能;完成了与异地多活的技术对接,提高系统的可靠性;增加了系统的可维护性,提高了系统的维护开发效率。
重构提高了系统的性能
例如,采用短事务,减少事务时间,提高了系统的性能。在老框架代码中对于业务事务的管理是放在 Biz 层中接口进行统一管理,这样带来一个问题,如果接口中还依赖别的系统接口,会增加整个事务时间,导致一个事务长时间占着数据库锁无法释放。本次重构之后的新代码,采用插件模式,只在 Service 插件中使用事务,这样缩小了事务范围,减少了事务时间,显著提高了系统的性能。
重构降低了系统的响应时间
例如使用异步的方式管理 Subsequent(事务后业务),缩短了接口响应时间。在互联网系统演进中,随着业务不断增长,系统越来越多,系统间的交互也越来越多。当一个系统处理完当前系统的数据更新之后,往往还需要处理一系列事后工作,来完成和其他系统的交互,这些交互有些需要本地计算,有些是同步交互,这些交互会增加接口响应耗时,本次重构设计了统一的事后异步方式,对于本系统不关心的结果并且处理起来耗时的事后工作,采用异步的方式来完成,提高了接口的响应时间。
重构增加系统的可维护性
例如重构代码采用插件模式和边界清晰的领域模型,增加了索引数据维护的便利性。系统按着多活改造的需求,需要放弃之前的商用数据库,采用 Mycat+MySQL 分库分表的方式存储数据,原本可以通过多个不同的查询条件查询数据,现在只能通过分库分表字段来查询数据,如果需要通过别的字段条件查询数据,需要对该字段创建索引表。先通过索引表检索分库分表字段,再通过分库分表字段检索数据。例如苏宁金融业务中分库分表字段使用会员编号,那么用户登录时使用的是用户名,此时需要通过用户名获取用户信息,再对用户名建立索引表。
索引表的维护比较麻烦,涉及业务场景多了,容易遗漏数据,系统并发高了,容易带来脏数据。对索引数据的维护,需要达到两个要求:
-
必须容易维护,将索引代码和业务代码解耦;
-
杜绝脏数据,索引数据必须和业务数据具有强一致性。
如果单看第一条,采用异步事件就可以完成,但是加上第二条,异步事件就无法满足了。
在本次重构中,得益于 DTM(Data Transfer Model)的设计,采用统一上下文数据,业务维护只需要提取出需要维护的索引数据,塞到 DTM 中,具体的索引维护的事情交给框架去做。
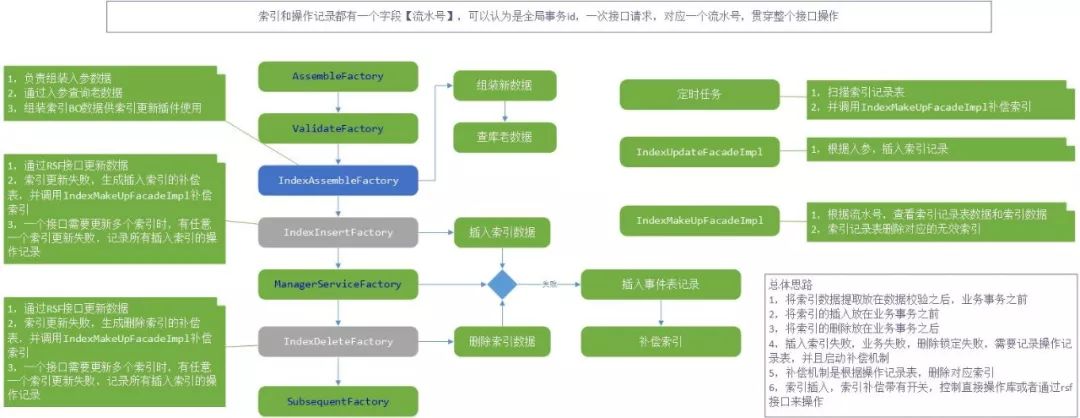
图 9 索引更新设计
对于苏宁金融会员服务系统的系统重构,是我们尝试使用领域驱动设计的第一个案例,但不会是最后一个案例,希望借此设计模式,能够打通产品和研发沟通的墙,使得双方都能够从业务领域模型中受益,使得系统能够更加聚焦产品核心业务价值,快速适应苏宁金融业务的发展变化。
?
如果你喜欢本文
请长按二维码,关注
转发至 朋友圈,是对我最大的支持
以上是关于领域驱动设计实践,精通业务,面向对象编程,面条编程,过程编程的主要内容,如果未能解决你的问题,请参考以下文章