csprng
Posted janly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了csprng相关的知识,希望对你有一定的参考价值。
http://tinylab.org/myths-about-urandom/
原文:Myths about /dev/urandom 作者:Thomas Hühn 译者:Chen Jie
1 译之前言
你知道 /dev/random 与 /dev/urandom 之区别吗?本文就是一篇关于 /dev/urandom 的“谣言粉碎机”。
以下开始正文。
有些 /dev/urandom 与 /dev/random 的错误说法仍在广为流传:
这里我主要谈论较新的 Linux 系统,而非其他类 UNIX 系统。/dev/urandom 不安全。 在加密应用中,务必使用 /dev/random。
: 事实:在类 UNIX 系统上,/dev/urandom 是加密应用中一个很好的随机数来源。
/dev/urandom 是一个伪随机数生成器(PRNG – Pseudo Random Number Generator),而 /dev/random 是一个“真正”的随机数生成器。
: 事实:/dev/urandom 与 /dev/random 用的是一模一样的 CSPRNG(Cryptographically Secure Pseudorandom Number Generator,加密安全的伪随机数生成器)。他们仅有少数细微的区别,且这些区别也与“真正随机”无关。
在加密应用中,/dev/random 无疑是更好的选择。即便 /dev/urandom 的安全性也差不多,但没有理由选用之。
: 事实:/dev/random 有个很讨厌的问题:它会阻塞。
阻塞很好啊!因为 /dev/random 提供的随机性源自它的熵池,快用完了就会阻塞呀。而 /dev/urandom 给出的是不安全的随机数(即便长时间运行后积累了熵也一样)。
: 事实:才不是呢。即便忽视可用量和随后用户的消耗,“熵值偏低”问题仍属杞人忧天。大约 256 字节的熵就可计算生成相当长一段时间内的、安全的随机数了。
这里有个有趣的问题,/dev/random 咋知道有多少熵可消耗?且看下文!
但密码学家总说要随时的“补种”(re-seeding)。这不反驳你上个观点?
: 事实:你难到我了。某种程度上是吧。随机数生成器需要不断地注入新的“种子”(系统信得过的、各种来源的熵)。但这么做,(部分地)因为其他方面的需要。
额,我可不是说注入熵不好,相反,注入熵没错。我只是说熵值偏低时阻塞不太合适。
就算你说的有理。但是 /dev/(u)random 的 man 页与你说的有出入呀!这个材料实际上赞同你的观点吗?有谁知道?
: man 页看起来是说,对于加密应用,/dev/urandom 是不是安全的,除非你真的了解全部密码学细节。
的确,在*某些*情形下,man 页推荐使用 /dev/random(在我看来,这也没关系,但没必要教条化)。但手册同时也推荐 /dev/urandom 用于“普通”的加密应用中。还有,虽说寻求权威的意见没啥了不起,在密码学问题上,小心谨慎并尝试得到领域专家的建议,总不会错。嗯,确实有不少专家和我持同样观点:在类 UNIX 系统上,/dev/urandom 适于提供加密应用中的随机数。显然,是他们的观点影响了我,而非我影响了他们。
难以置信,是吧?我一定错了!好吧,继续读下去,让我来说服你。
我试着不涉及太多,但展开正题之前,有两点怕是免不了要谈。
即啥是随机,或更确切的:这里谈论什么样的随机?
更重要的,我可不是假装谦逊。写下这篇文章是为了精炼和捍卫自身观点,以便在其他讨论中加以引用。
然后,我非常希望听到不同的声音。但光说 /dev/urandom 是坏掉的,这还不够,你得详细说不同意哪些点,及讨论为什么。
2 真正的随机
随机数是“真随机”的意味着啥?
我不想深入该问题,因为一深入马上就成了哲学范畴。讨论它往往也很发散,因为每个人只顾宣扬自己认可的随机模型,而不倾听别人的。甚至都不愿阐明自己的观点。
我认为判断是否为“真随机”的“黄金标准”是量子效应。观察一个光子是否穿过半透明反射镜,观察某些放射性物质释放出 Alpha 粒子。这些是谈论随机性最好的思路。一些人可能部分程度上,相信这些效应不也是“真随机”的。甚至是认为这世上根本没有随机性。此处且让各种观点百花齐放。
对此,密码学家无视“真随机”的含义,来规避这些哲学上的争论。他们关心不可预测性。只要没人能预知下一随机数,那么一切都 ok。当谈论随机数是加密技术的先决条件时,在我看来,不可预测性正是你需要的。
无论如何,我不太关心这些“哲学上安全”的随机数。我关心的是,对你而言,是否为“真随机数”。
3 两类的安全性,其一有意义
假定你获得了这些“真正”的随机数,你会用来干嘛?
你把它们打印出来,装裱起来挂在卧室,来彰显量子世界之美?那不错,我完全能理解。
等等,咋地,你要用它们来加密?那么,这样。。。有点丑陋了。
你看,基于量子效应的、“真”的随机数,被用在了现实世界中不那么完美的加密算法中了。
几乎所有在用的加密算法,都达不到信息论上的安全。它们仅算是“计算上”的安全。脑中冒出的两个例外,是 Shamir’s Secret Sharing 和 the One-time pad。前者似乎是一个有效的例外(如果你切实想使用之),后者则完全是现实不可行的。
但所有熟知的加密算法,aes,rsa,Diffie-Hellman,椭圆曲线,以及所有这些常用加密软件包,OpenSSL,GnuTLS,Keyczar,正在用的操作系统的加密 API,全只达到了计算安全。
其中差别在哪?信息论上安全的算法,那确实是安全的,经得起时间考验。而其他那些算法,没法抵御攻击者用无限计算资源来枚举密码。但我们仍然用那些算法,因为破解它们需要这世上所有计算机,花上自宇宙诞生至今还要长的时间。所谓“不那么安全”,也就是这个样子了。
除非有些聪明人,能使用很少的计算资源就破解了算法。即便如今计算能力如此发达,对于密码专家,若能破解 ase,rsa 等,是莫大的成就。
当你不信任随机数生成器背后的密码学算法,坚持要“真随机”而非“伪随机”数,你却不得不把这些“真随机数”用到刚被你鄙视了的密码学算法。
所以事实是,若这些最先进的 hash 算法是坏掉的,或最先进的块加密算法是坏掉的,即便手头上都是“哲学上不安全”的随机数也木有关系了。因为根本就不存在“安全地”用随机数的方法。
综上,在计算安全的算法中,勇敢地用计算安全的随机数吧,骚年。换句话说,用 /dev/urandom。
4 Linux 随机数生成器的框框图
4.1 一个错误视图
Linux 内核的随机数生成器,在大多数人想象中,大概是这个样子的:
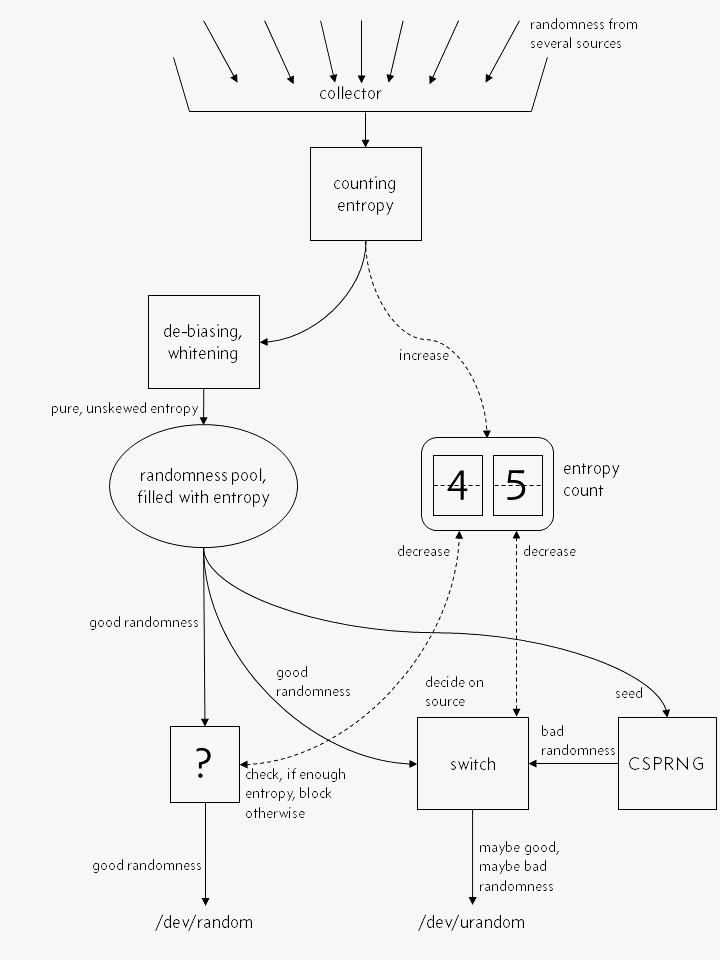
“真正的随机”,或者说是略带偏差、“不纯”的随机,流入系统,其含有的熵被精确衡量,然后内部熵计数增加。之后,流入的随机被“提纯”,并放入内核的熵池。/dev/random 和 /dev/urandom 都从中取随机数。
“真”随机数生成器,/dev/random,直接从熵池中读取随机数,如果熵池熵足够,就返回随机数并递减熵计数。若熵不足,就阻塞,直到新的熵注入。
上面这段叙述,重点在于 /dev/random 是直接地输出提纯后的、各随机源注入的随机。
而 /dev/urandom,也类似,只是当系统熵不够时,不同于 /dev/random,它才不阻塞咯。它会输出一些由伪随机数生成器(CSPRNG)产生的、“低质量”的随机数。这个 CSPRNG 仅补种(be seeded)一次(或常常补种,没啥差别),种子来自熵池。CSPRNG 产生的随机数不该被信任。
上述好像是许多人对 Linux 上的随机数的认识。这样看来,避免使用 /dev/urandom 好像很有道理 - 因为熵足够时,从 /dev/random 和 /dev/urandom 读是一样的,而熵不足时,读 /dev/urandom 只能得到 CSPRNG 产生的、低质量的随机数。
貌似很有道理,然而却是彻头彻尾的,嗯,错觉。事实上,随机数生成器的框框图看起来是下面酱紫的哟。
4.2 一个正确的简化视图
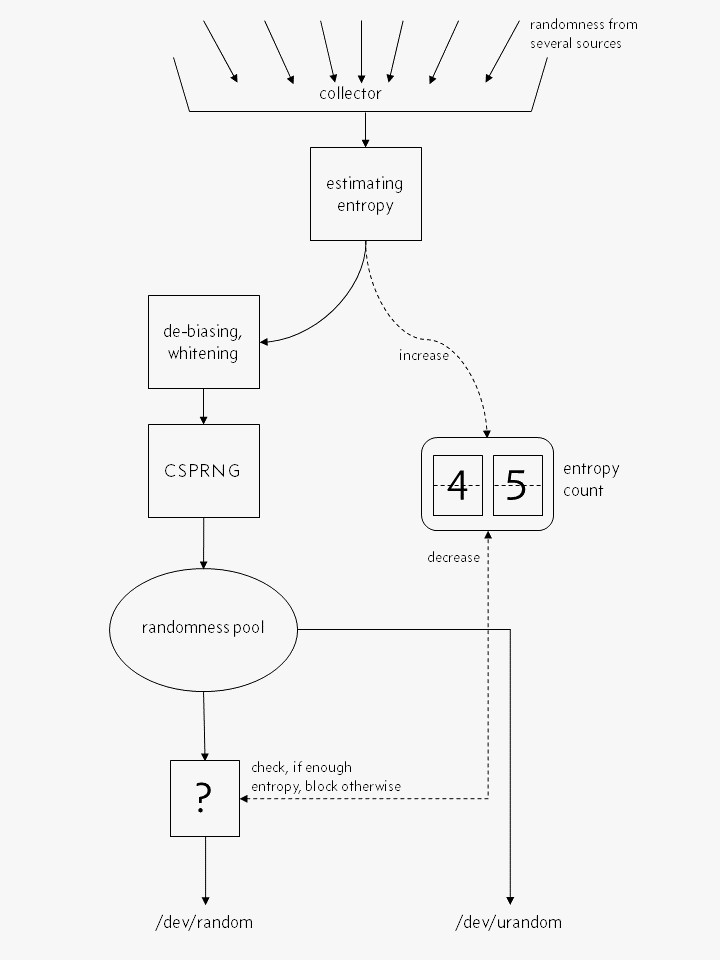
看出两个图最大的不同了没?生成随机数过程中,CSPRNG 是不可避免的环节。才没什么 /dev/random 直接由熵池输出“优质精纯”的随机数呢。各个随机源的输入被彻底 混合 与 哈希 进 CSPRNG,然后才输出随机数。该环节 /dev/urandom 和 /dev/random 都会经历。
另一个重要的不同在于,才没有啥熵的精确计量,只是熵的估值。随机源提供的熵,不能被精确计量,而是估算。请注意,当熵估算过分乐观时,/dev/random 那种“熵池有多少给多少”的特点没了。另外,很难估算熵总量。
Linux 内核只使用某事件的到达时间,来估算其中含有的熵。它通过将“事件达到时间”,输入一个多项式插值公式,从而计算出这些“时间”到底有多“出乎意料”。这个多项式插值模型是否是最好的熵估算方法呢?这个问题很有意思。另外,硬件限制可能会影响这些“达到时间”。硬件的各种采用率也可能影响之,因为直接影响了“事件到达时间”的精度。
最后,据我们目前的全部已知,内核的熵估值算法还挺好的。换句话说,比较保守的。当然,有人会争论熵估值算法是否真有那么好,但我觉着该不是个问题。对于那些期望“每个输出的随机数,都该有一定数量熵来对应”的人而言,会担心估值算法不佳而紧张失眠。不过我才不关心熵估值呢,蒙头睡大觉去也~
一句话总结了:从 /dev/random 和 /dev/urandom 读出的随机数,是由同样的 CSPRNG 产生的。它们的差别,只在于当各自熵池估值为 0 时,/dev/random 阻塞,而 /dev/urandom 不阻塞。
5 阻塞有什么问题?
你是否有过等 /dev/random 生成足够的随机数的经历?例如在虚拟机中生成一个 PGP 密钥?连接 web 服务器时,等着足够的随机数来作为一个短暂的会话密钥?
这就是问题所在。
我从事工厂自动化中安全相关系统的工作。猜猜安全系统失效的主要原因是啥?是操作。一些安全措施让工人觉着繁琐,诸如花了太多时间,太不方便了。于是就有了“随机应变”的不规范操作。更深层而言:人总是讨厌按自己的方式做事时被妨碍到。他们会想出各种绕过方法,来维持原有的方式。正常人很少有懂密码学的。
为啥不移掉 random() 调用?为啥论坛上的总有些家伙,会给出攻略,即用 ioctl 来增加熵计数呢?为啥不关掉 SSL 算逑?
这些点子,不过就是了愚弄系统,看起来避免了系统阻塞卡顿,实则牺牲了安全性,你甚至都不知道这些。
“为了安全,就该忽视可用性,易用性,以及其他优点”,这是个伪对立。安全并不意味着阻塞,如前所述的那样,/dev/urandom 能给出和 /dev/random 同样好的随机数,用它!
6 CSPRNGs 很 ok
即便是从 /dev/random 读出的“优质”随机数,其实也是 CSPRN 产生的,那我们怎能在高安全的应用中用它们呢?
其实,对于我们大部分的密码学组件而言,“看起来随机”就够了。对于密码学家而言,若某个密码学哈希算法输出,没法和一个随机字串相区别;一个块加密算法输出(不知道密钥前提下),没法和一个随机数据块相区别,这就够了。
如果真有人找到了 CSPRNG 的缺陷,那又成了本文开头所说的:啥安全都没了,因为 CSPRNG 和 块加密、哈希算法用的是一样的数学基础。所以别担心。
7 熵值过低的时候呢?
没关系。
底层的密码学组件,设计上能防止其输出结果被预测出来,只要在一开始有足够随机性(即熵)。“足够”的定义通常是 256 位,不需要更多了。
8 补种(re-seeding)
既然熵如此不重要,为啥还要不断将新的熵注给随机数生成器呢?
[djb 说][5] 熵太多反而有害。首先,这是无害的。若你拿到了更多的随机,请用任何方式用它!
为啥要不断补种的另一理由:
想象一下,攻击者知道了你随机数生成器的内部状态。这是安全被攻破能想到的最坏情况了。攻击者能完全访问系统。
现在你失去了一切,因为攻击者能计算出现在开始的所有输出。
但随着时间推移,越来越多的新熵被混入,内部状态又变得随机了。这样的一个随机数生成器设计,看起来有“自愈”功能。
这只是说熵注入到随机数生成器的内部状态中,没说要阻塞其输出。
9 random 和 urandom 的 man 页
/dev/random 和 /dev/urandom man 页写的。。。很容易惊吓到一些程序员:
A read from the /dev/urandom device will not block waiting for more entropy. As a result, if there is not sufficient entropy in the entropy pool, the returned values are theoretically vulnerable to a cryptographic attack on the algorithms used by the driver. Knowledge of how to do this is not available in the current unclassified literature, but it is theoretically possible that such an attack may exist. If this is a concern in your application, use /dev/random instead.
这种攻击在世间似乎没有,但 NSA(美国国家安全局) 一定掌握了这种攻击手段,是吧?如果你真信,请用 /dev/random 吧。
事实上,某个间谍机构、黑客或者其他妖魔鬼怪掌握了这样的攻击手段的可能性仍有,但光凭假想做决策,显然不理性。
即使想省事(不去纠结用 /dev/urandom 与否),让我说个秘密:目前世间没有现实可行的攻击,能破解 aes,sha-3 或其他可靠的加密和哈希算法。(但也许某个间谍机构、。。。能破解之?),你打算不用这些算法了吗?当然不是。
再看看 man 页中一句,“use /dev/random instead”,当 /dev/random 没有阻塞时,其随机数由同 /dev/urandom 一样的 CSPRNG 生成。
man 页最后又唠叨了这么一段(打脸了,有木有):
If you are unsure about whether you should use /dev/random or /dev/urandom, then probably you want to use the latter. As a general rule, /dev/urandom should be used for everything except long-lived gpg/ssl/ssh keys.
好吧,我觉着没必要。如果你为了“long-lived keys”(长期使用的密钥),真觉着有必要用 /dev/random,那就用呗 – 等上几秒钟时间生成密钥,期间还要你随便敲敲键盘(来增加熵)。
但别把它在邮件服务器的安全连接中,想着更安全些,却让服务卡半天,真没法用了。
10 正统观点
本文表达的观点,在网上,算是少数观点。但问问一些真正的密码学家,你很少能听到“用会阻塞的 /dev/random ”的声音。
比如 Daniel Bernstein,其网名 “djb” 更为人熟悉:
Cryptographers are certainly not responsible for this superstitious nonsense. Think about this for a moment: whoever wrote the /dev/random manual page seems to simultaneously believe that
(1) we can’t figure out how to deterministically expand one 256-bit /dev/random output into an endless stream of unpredictable keys (this is what we need from urandom), but
(2) we can figure out how to use a single key to safely encrypt many messages (this is what we need from ssl, pgp, etc.).
或者 Thomas Pornin,他是我在 Stackexchange 上遇到的、最有帮助的人之一:
The short answer is yes. The long answer is also yes. /dev/urandom yields data which is indistinguishable from true randomness, given existing technology. Getting “better” randomness than what /dev/urandom provides is meaningless, unless you are using one of the few “information theoretic” cryptographic algorithm, which is not your case (you would know it).
The man page for urandom is somewhat misleading, arguably downright wrong, when it suggests that /dev/urandom may “run out of entropy” and /dev/random should be preferred;
或者 Thomas Ptacek,他设计加密算法、加密系统,同时也创建了一个有声望的安全机构。该机构进行过许多安全检测,并破解过许多糟糕的加密算法。
Use urandom. Use urandom. Use urandom. Use urandom. Use urandom. Use urandom.
11 略带缺陷
/dev/urandom 也不是完美的,有两重问题:
Linux 不像 FreeBSD,它的 /dev/urandom 总是非阻塞的。其整个安全性的保证,要求开始时刻必须是随机的,即要有一个种子。
刚启动时,Linux 内核还没来得及收集熵,所以 /dev/urandom 给出的随机数不是那么随机的。
这点上,FreeBSD 做的比较好:其上的 /dev/random 和 /dev/urandom 就是同一设备。在开始时刻,/dev/random 是阻塞的,直到收集到足够熵。之后就不阻塞了。
同时,Linux 也加入了一个新的系统调用 getrandom(2),源自 OpenBSD 的 getentropy(2)。该系统调用行为优雅:阻塞直到集得足够初始熵,之后就不阻塞了。当然,由于这是个系统调用而非字符设备,对脚本而言使用不便。对此 Linux 也有补救措施,那就是本次开机,保存的一些随机数到一个种子文件。下次启动时读入该种子文件(将种子文件内容写入 /dev/urandom)。从而在启动中,能汲取上次开机的随机性。
至于在什么时候写种子文件,在关机脚本中写不是很好。例如死机崩溃了,就没机会写了。所以,别依赖每次都正常关机。
还有,在安装完系统后的第一次启动,上面机制失效了。其对策为,系统安装时,安装器会写一个种子文件。
对于虚拟机,是另一层面的问题了:人们总是喜欢克隆虚拟机,或者存虚拟机快照,此时种子文件不起作用。
但其解决方案也不是到处用 /dev/random,而是类似在克隆后,或从快照中恢复后,进行补种。
12 tldr;
勇敢地用 /dev/urandom 吧,骚年!
以上是关于csprng的主要内容,如果未能解决你的问题,请参考以下文章