Cortex-M3&Cortex-M4-技术综述
Posted xqyjlj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cortex-M3&Cortex-M4-技术综述相关的知识,希望对你有一定的参考价值。
Cortex-M3&Cortex-M4-技术综述
Cortex-M3 和Cortex-M4处理器的一般信息
处理器类型
? ARM Cortex-M为32位RISC(精简指令集)处理器,其具有:
- 32位寄存器
- 32位内部数据通路
- 32位总线接口.
? 除了32位数据,Cortex-M处理器(以及其他任何ARM处理器)还可以高效地处理8位和16位数据。Cortex-M3和Cortex-M4处理器还支持涉及64位数据的多种运算(如乘、累加)。
? Cortex-M3和Cortex-M4处理器都具有三级流水线(取指、译码和执行),它们都基于哈佛总线架构,取指令和数据访问可以同时执行。ARM Cortex-M处理器的存储器系统使用32位寻址,地址空间最大为4GB。存储器映射是一致的,这就意味着尽管总线接口有多个,4GB存储器空间却只有一个。存储器空间包括程序代码、数据、外设以及处理器内的调试支持部件。
? 与其他任何ARM处理器相同,Cortex-M处理器基于一种加载一存储架构。这也就意味着数据需要从存储器中加载和处理后,使用多个单独的指令写回存储器。例如,要增加SRAM中存储的数据值,处理器需要使用一条指令从SRAM中读出数据,并且将数据放到处理器的寄存器中,然后使用第二条指令增加寄存器中的数据值,最后使用第三条指令将数值写回存储器。处理器内部的寄存器细节一般被称作编程模型。
指令集
? Cortex-M处理器使用的指令集名为Thumb(其中包括16位Thumb指令和更新的32位Thumb指令),Cortex-M3和Cortex-M4处理器用到了Thumb-2技术,它允许16位和32位指令的混合使用,以获取更高的代码密度和效率。
? ARM7TDMI等经典的ARM处理器具有两种操作状态:32位的ARM状态和16位的Thumb状态。在ARM状态中,指令是32位的,内核能够以很高的性能执行所有支持的指令;而对于Thumb状态,指令是16位的,这样可以得到很好的代码密度,不过Thumb指令却不具有ARM指令的所有功能,要完成特定的操作,可能需要更多的指令。
? 要同时得到两者的优势,许多用于经典ARM处理器的应用程序混合使用了ARM和Thumb代码。不过这种混合编码的方式并不是非常理想,它会带来状态间切换的开销(执行时间和指令数,如下图所示),而且两个状态的分离还增加了软件编译过程的复杂度,对于不是很熟练的开发人员来说,优化代码更加困难。
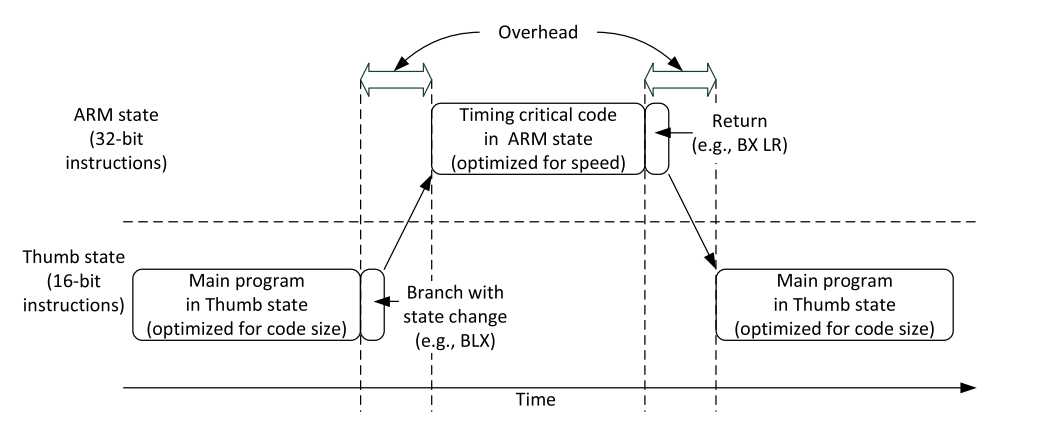
? 随着Thumb-2技术的引入,Thumb指令被扩展为支持16 位和32位两种解码方式,现在,无须在两个不同操作状态间切换就可以满足所有的处理需求。事实上,Cortex-M 处理器根本不支持32位的ARM指令(如下图所示),甚至中断处理都可以完全在Thumb状态中实现,不过对于经典的ARM处理器,中断处理是会进入ARM状态的。利用Thumb-2技术,与经典的ARM处理器相比,Cortex-M处理器具有诸多优势。例如:
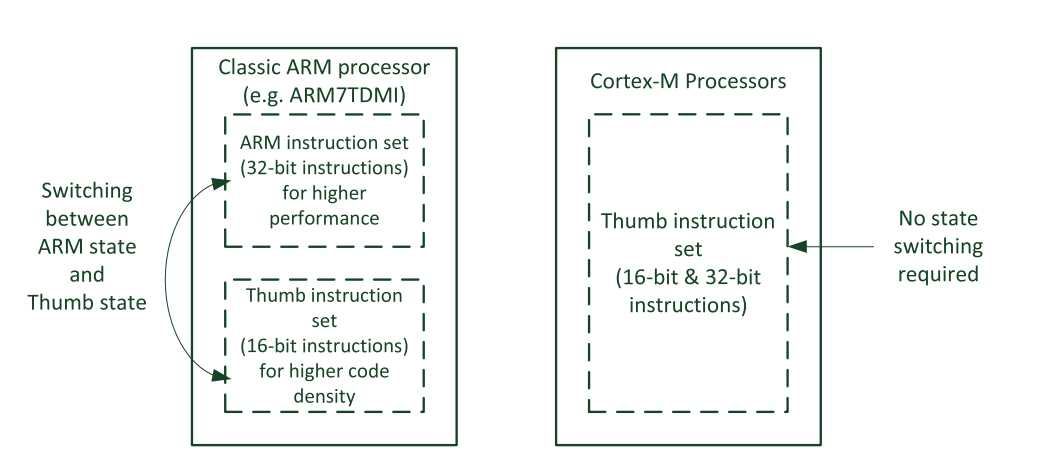
- 无状态切换开销,节省执行时间和指令空间。
- 无须指定源文件中的
ARM状态或Thumb状态,开发软件也更容易。 - 在获得最佳的代码密度和效率的同时,还能很容易地达到高性能。
- 利用
Thumb-2技术,与ARM7TDMI等经典处理器相比,Thumb指令集已经得到很大的扩展。注意,尽管所有的Cortex-M处理器都支持Thumb-2技术,它们实现的Thumb ISA子集不尽相同(见下表)。
| 指令组 | Cortex- M0、M1 | Cortex- M3 | Cortex- M4 | 具有FPU的Cortex -M4 |
|---|---|---|---|---|
| 16位ARMv6-M指令 | ● | ● | ● | ● |
| 32位间接跳转链接指令 | ● | ● | ● | ● |
| 32位系统指令 | ● | ● | ● | ● |
| 16位ARMv7-M指令 | ● | ● | ● | |
| 32位ARMv7-M指令 | ● | ● | ● | |
| DSP扩展 | ● | ● | ||
| 浮点指令 | ● |
? 有些Thumb指令集中定义的指令在当前的Cortex-M处理器中是不支持的,如协处理器指令(尽管可能会增加经过存储器映射的独立的数据处理引擎)。同样,有些其他的经典ARM处理器中的Thumb指令也不再支持了,如带有立即数的跳转链接并交换状态(BLX)(用于将处理器状态从Thumb切换到ARM)、几个修改处理器状态指令(CPS)以及SETEND(端设置)指令,它们都是随着架构v6引入的。
模块框图
? 从较高的层级来看,Cortex-M3和Cortex-M4是非常相似的。尽管它们在内部数据通路.设计上存在巨大差异,处理器的一些部分还是相似的,如取指缓冲、部分指令译码和执行阶段以及NVIC。另外,”内核“层级外的部件基本上是相同的。
? Cortex-M3和CortexM4处理器包含处理器内核、嵌套向量中断控制器(NVIC)、SysTick定时器以及可选的浮点单元(用于Cortex-M4)。除了这些以外,处理器中还有一些内部总线系统、可选的存储器保护单元(MPU)以及支持软件调试操作的一组部件。内部总线连接可以将处理器和调试产生的传输送到设计的各个部分。
? Cortex-M3和CortexM4处理器是高度可配置的。例如,调试特性是可选的,若产品需要支持调试,片上系统设计人员可以将调试部件去掉,这样可以显著降低设计的硅片面积。有些情况下,芯片设计人员还可以选择降低硬件指令断点和数据监视点比较器的数量,以降低系统的门数量。许多系统特性也是可配置的,如中断输入的数量、支持的中断优先级的数量以及MPU等。
? 下图为CortexM3和Cortex-M4处理器框图
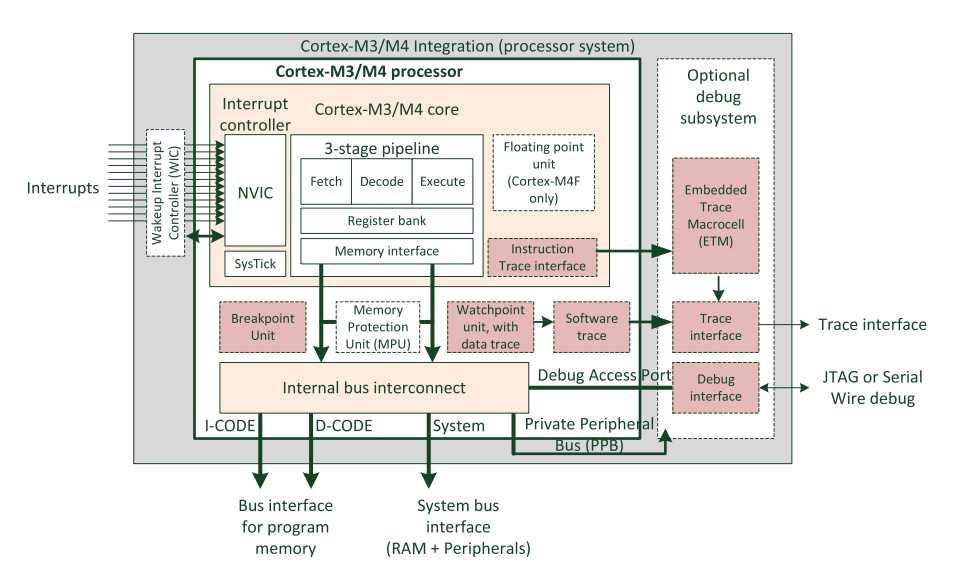
? Cortex-M3和Cortex-M4处理器的顶层具有多个总线接口,如下表所示。
| 总线接口 | 地址范围 | 描述 |
|---|---|---|
| I-CODE | 0x0~0x1FFFFFFF | 主要用于程序存储器,适用于取指和取向量操作, 基于AMBA 3.0 AHB Lite总线协议 |
| D- CODE | 0x0~0x1FFFFFFF | 主要用于程序存储器,适用于数据和调试器访问操作, 基于AMBA3.0 AHB Lite总线协议 |
| 系统 | 0x20000000 ~ 0xFFFFFFFF(除PPB区) | 主要用于RAM和外设,适用于任何一种访问, 基于AMBA 3.0 AHB Lite总线协议 |
| PPB | 0xE0000000~0xE00FFFFF | 外部私有外设总线(PPB),范围内的私有调试部件, 基于AMBA 3.0 APB协议 |
| DAP | 调试访问端口(DAP)接口 用于调试接口模块产生到包含系统存储器 调试部件在内的任意存储器位置的调试器访问。 基于ARMCoreSight调试架构 |
存储器系统
? Cortex-M3和Cortex-M4处理器本身并不包含存储器(没有程序存储器、SRAM或缓存),它们具有通用的片上总线接口,因此,微控制器供应商可以将它们自己的存储器系统添加到系统中。一般来说,微控制器供应商需要将下面的部件添加到存储器系统中:
- 程序存储器,一般是
Flash。 - 数据存储器,一般是
SRAM。 - 外设。
? 这样,不同微控制器产品可能会具有不同的存储器配置,不同的存储器大小和类型,以及不同的外设.
? Cortex-M处理器的总线接口为32位宽,且基于高级微控制器总线架构(AMBA)标准。AMBA中包含多个总线协议,任何芯片设计者都可以免费使用这些标准协议。AMBA规范可以从ARM网站下载。由于这些标准协议的低硬件成本,效率以及开放性,它们大受芯片设计者的欢迎。
? CortexM3和Cortex-M4处理器主要使用的总线接口协议为AHBLite(高级高性能总线),它用于程序存储器和系统总线接口。AHBLite协议为流水线结构的总线协议,可以在低硬件成本下实现高运行频率。高级外设总线(APB)接口为处理器使用的另外一种总线协议,它通常用于基于ARM的微控制器的总线系统。另外,APB协议在Cortex-M3和Cortex-M4处理器内部还用于调试支持。
? 与片外总线协议不同,AHB Lite和APB协议相对简单。这是因为芯片内的硬件配置是固定的,无须一种复杂的初始化协议来处理可能的配置(例如,无须支持类似于计算机技术中的“热插拔”)。
? 由于这种开发方式和通用的总线架构的使用,每位芯片设计者都可以为ARM处理器开发外设、存储器控制器以及片上存储器模块。这些设计通常被称作IP,微控制器供应商可以在他们的产品中使用自己的外设设计或者其他公司的授权IP。通过一种标准的总线协议,这些IP可以很轻松地被集成到一个大的设计中。如今,AMBA协议已经成为了片上总线系统的标准,可以在许多片上系统设备中找到这些设计,其中,也包括其他处理器设计公司的处理器。
Cortex-M3和Cortex-M4处理器的特性
性能
Cortex-M处理器给微控制器产品带来了高性能。
-
三级流水线结构使得包括乘法在内的多数指令,可以在单周期内执行,同时允许微控制器设备运行较高的频率,一般可以超过100MHz,而利用现代半导体生产工艺则可以达到200MHz。甚至在运行和其他多数处理器产品相同的频率时,
Cortex-M3和Cortex-M4处理器的时钟周期比(CPI)也会更高。这样每MHz就可以完成更多的任务,若要降低功耗,也可以让系统运行在较低的时钟频率下。 -
由于多总线接口,指令和数据访问可以同时执行。
-
流水线结构的总线接口使得存储器系统可以运行较高的时钟频率。
-
由于指令集非常高效,执行复杂运算时可以使用较少的指令。
-
每次取指令都是32位的,而多数指令则是16位的,因此一次可以取两条指令,存储器接口上的多余带宽也带来了更高的性能和更佳的能耗效率。
利用目前的编译器技术,Cortex-M3和Cortex-M4的性能如下表所示。
| 处理器 | Dhrystone 2.1/MHz | CoreMark/MHz |
|---|---|---|
| Cortex-M3 | 1.25 DMIPS/MHz | 3.32 |
| Cortex-M4 | 1.25 DMIPS/ MHz | 3.38 |
| 具有FPU的Cortex-M4 | 1.25 DMIPS/MHz | 1.38 |
低功耗
? 低功耗是Cortex-M处理器的设计目标,许多Cortex-M3和Cortex-M4微控制器产品在运行时功耗会低于200μA/MHz(1. 8V供电时约为0. 36mW/MHz),而有些甚至会低于100μA/MHz。Cortex-M处理器的低功耗特性包括:
Cortex-M3面向低成本微控制器设计,它们的硅片面积不能太大(门数低)。由于具有SIMD指令和可选的浮点单元,Cortex-M4要稍微大一些。三级流水线设计可以很好地平衡性能和硅片大小。- 由于
Cortex-M处理器的高代码密度,软件开发者可以使用具有较小程序存储器的设备来实现自己的产品,这样可以降低功耗。 Cortex-M处理器具有多个低功耗特性,其中,包括定义在架构中的多个休眠模式和集成的架构时钟支持,这样当处理器的某部分不使用时,可以将这部分的时钟电路关闭。- 完全静态、同步以及可综合的设计使得处理器在生成时可以使用任何低功耗或标准的半导体工艺技术。对于从版本2开始的
Cortex-M3以及当前所有版本的Cortex-M4,处理器中存在一个名为唤醒中断控制器(WIC)的可选硬件单元,它可以使能状态保持功率门(SRPG)等低功耗技术。
? 由于这些低功耗特性的存在,Cortex-M处理器非常受嵌入式产品设计者的欢迎,他们总是会寻找能够改进自己的可移动产品电池寿命的方法。
? 除了较长的电池寿命,微控制器的低功耗也有助于降低电磁干扰(EMI),而且可能会简化电源设计(或者减小电池尺寸),因此,可以降低系统成本。
中断处理
? Cortex-M3和Cortex-M4处理器中存在一个复杂的中断控制器,其被称作嵌套向量中断控制器(NVIC)。NVIC具有多个特性:
- 支持最多240个中断输入、不可屏蔽中断(
NMI)输入和多个系统异常。每个中断(NMI除外)都可以被单独使能或禁止。 - 中断和多个系统异常具有可编程的优先级。对于
Cortex-M3和CortexM4,优先级可以在运行时动态修改(注意,Cortex-M0/M0+不支持优先级的动态修改)。 - 嵌套中断/异常以及中断/异常按照优先级的自动处理。
- 向量中断/异常。这就意味着处理器会自动取出中断/异常向量,无须软件确定产生的是哪个中断/异常。
- 向量表可以重定位在存储器中的多个区域。
- 低中断等待。对于具有零等待状态的存储器系统,中断等待仅为12个周期。
- 中断和多个异常可由软件触发。
- 多个优化用于降低不同异常上下文切换时的中断处理开销。中断/异常屏蔽功能可以将所有的中断和异常(
NMI除外)屏蔽掉,或者将中断/异常屏蔽为某个优先级之下。
? 为了支持这些特性NVIC使用了多个可编程寄存器。这些寄存器经过了存储器映射,而CMSIS-Core则为大多数常见的中断控制任务提供了所需的寄存器定义和访问函数(API)。这些访问函数易于使用,而且多数可用于Cortex-M0等其他Cortex-M处理器。
? 向量表为系统存储器的一部分,其中存有中断和系统异常的起始地址。向量表默认位于存储器空间的开头(地址0x0),不过,若需要,向量表偏移可以在运行时变为其他值。对于大多数应用程序,向量表可以在编译时被设置为应用程序映像的一部分,且在运行时保持不变。
? Cortex-M3或Cortex-M4设备实际支持的中断数量由微控制器供应商在设计芯片时确定。
调试支持
? Cortex-M3和Cortex-M4处理器具有丰富的调试特性,可以降低软件开发的难度。除了暂停和单步等标准的调试特性外,在无须昂贵设备的前提下,还可以利用跟踪特性查看程序执行的细节。
? Cortex-M3和Cortex-M4处理器的Flash补丁和断点单元(FPB)中存在最多8个用于断点的硬件比较器(6个用于指令地址,2个用于数据地址)。在触发时,处理器可被暂停,或将传输重映射到SRAM区域。利用重映射特性,只读的存储器位置也可以被修改,例如,可以利用一小块可编程存储器为掩膜ROM补上部分程序。这样,即使主程序代码位于掩膜ROM中,也可以修正代码错误或者进行改进。
? Cortex-M3和Cortex-M4处理器的数据监视点和跟踪(DWT)单元中还存在最多4个硬件数据监视点比较器。在访问所选择的数据时,这些比较器会产生监视点事件并暂停处理器,或者在无须暂停处理器的情况下产生可由跟踪接口收集的跟踪信息。集成开发环境(IDE)中的调试器可以将数据值和其他信息呈现出来,并将数据值的改变图像化。DWT可用于产生异常事件跟踪和基本概况信息,也通过跟踪接口输出。
? Cortex-M3和Cortex-M4处理器还具有一个可选的嵌人式跟踪宏单元(ETM)模块,其可用于产生指令跟踪。通过该模块可以查看执行过程中的程序流,它在调试复杂软件时非常重要,而且还可用于详细概况和代码覆盖分析。
? Cortex-M3和Cortex-M4处理器的调试可以通过两种接口实现: JTAG连接或名为串行线调试(SWD)的两线接口,许多开发工具供应商都同时支持JTAG和SWD协议。跟踪信息可以由单线的串行线查看(SWV)接口收集,或者若所需的跟踪带宽较大时(如使用指令跟踪时),也可以使用一种跟踪端口接口(一般为5针)。跟踪和调试接口可以合并到一个接头中。
以上是关于Cortex-M3&Cortex-M4-技术综述的主要内容,如果未能解决你的问题,请参考以下文章