爬取B站up主相册原图
Posted banshaohuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取B站up主相册原图相关的知识,希望对你有一定的参考价值。
爬取B站up主相册原图
从 Network 选项中找到 api 链接。
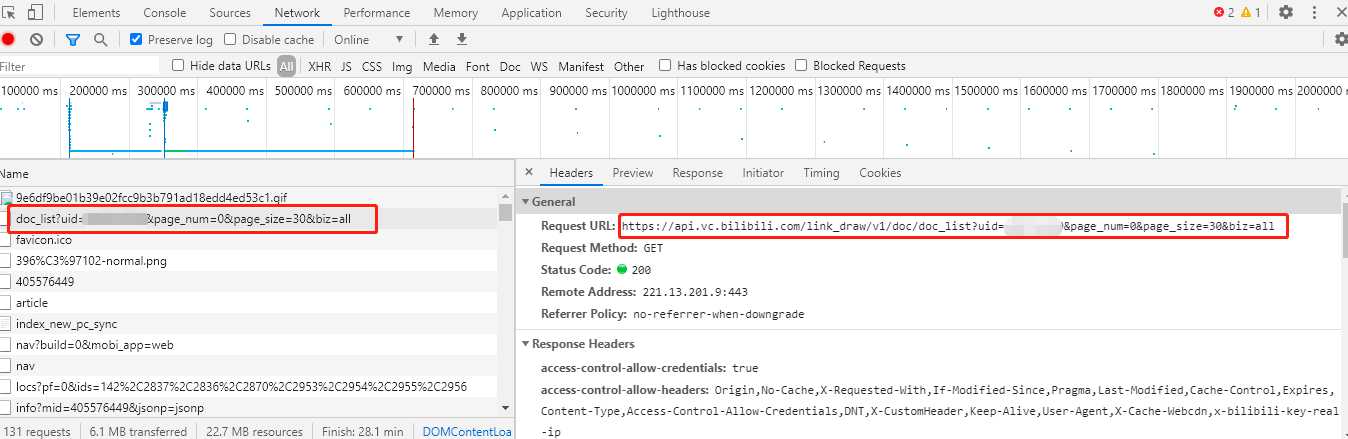
从 Preview 选项中一层一层地剥,直到找到真实的图片链接地址。
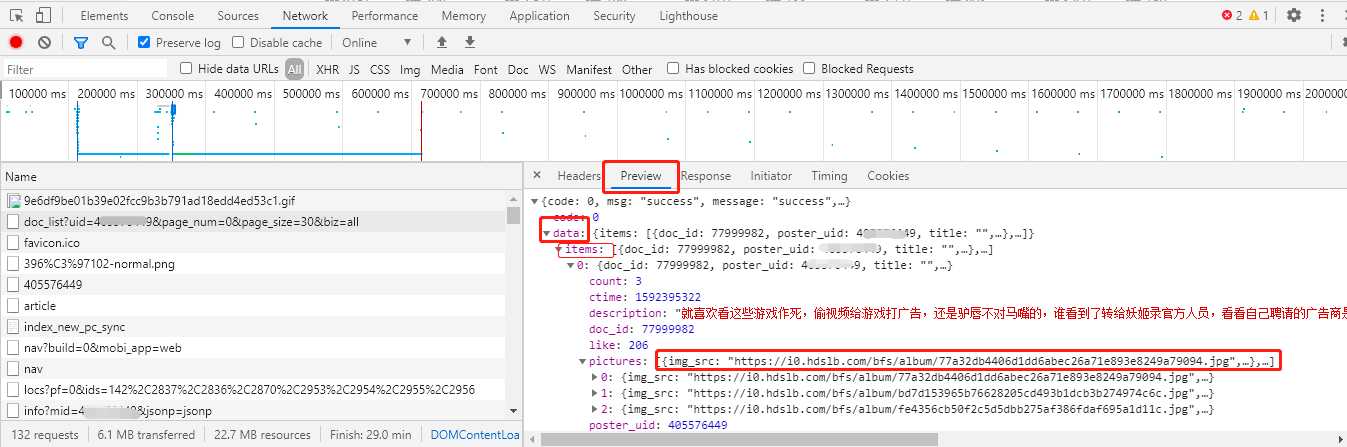
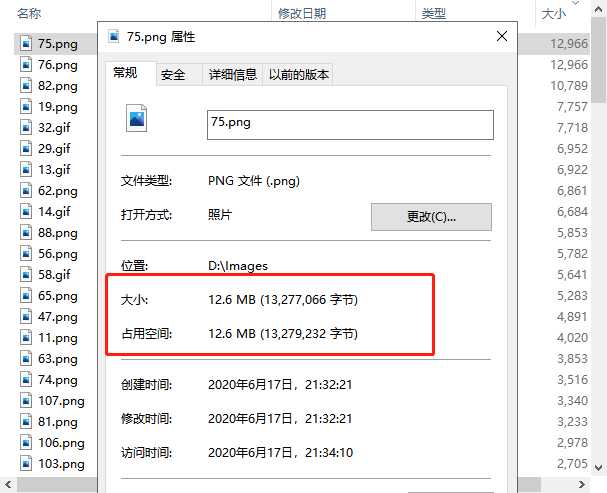
下载的图片可以达到 12MB,下载的是原图。
源码:
# -*- coding: utf-8 -*-
# @Time : 2020/6/17 20:54
# @Author : banshaohuan
# @Site :
# @File : album_bilibili.py
# @Software: PyCharm
import os
import requests
import json
import time
from fake_useragent import UserAgent
def get_fake_agent():
headers = {"User-Agent": UserAgent().random}
return headers
# 获取图片链接
def get_urls(uid, page=0):
# 存放图片链接
pic_list = []
while True:
url = f"https://api.vc.bilibili.com/link_draw/v1/doc/doc_list?uid={uid}&page_num={page}&page_size=30&biz=all"
content = requests.get(url, headers=get_fake_agent(), verify=False).content
time.sleep(2)
dic = json.loads(content)
if len(dic.get("data").get("items")) == 0:
break
# 返回的数据字典中图片信息在items中
item_list = dic.get("data").get("items")
for item in item_list:
# item是图片链接
item = item.get("pictures")[0].get("img_src")
pic_list.append(item)
page += 1
return pic_list
# 保存图片到本地
def save_pic(pic_list, file_path="D:/Images"):
if not os.path.exists(file_path):
os.mkdir(file_path)
for i in range(len(pic_list)):
content = requests.get(
pic_list[i], headers=get_fake_agent(), verify=False
).content
time.sleep(2)
with open(f"{file_path}/{i+1}.{pic_list[i][-3:]}", "wb") as f:
f.write(content)
print(f"{i+1}.{pic_list[i][-3:]} is downloaded")
def main():
# 不显示警告信息
requests.packages.urllib3.disable_warnings()
uid = 999999999 # 用户id,up主空间url中的最后一串数字
pic_list = get_urls(uid)
save_pic(pic_list)
if __name__ == "__main__":
main()
我在源码中增加了睡眠和获取随机 headers,这些都可以根据个人爱好更改。

以上是关于爬取B站up主相册原图的主要内容,如果未能解决你的问题,请参考以下文章